The Complete Data Science Study Roadmap
KDnuggets
AUGUST 29, 2022
This article will map out the things you need to do to become a data scientist.

KDnuggets
AUGUST 29, 2022
This article will map out the things you need to do to become a data scientist.

Simon Späti
AUGUST 25, 2022
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source Data Lake offloading data for analytics? Asked yourself what components and features would that include. Didn’t know the difference between a Data Lakehouse and a Data Warehouse? Or you just wanted to govern your hundreds to thousands of files and have more database-like features but don’t know how?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Marc Lamberti
AUGUST 11, 2022
The ShortCircuitOperator in Apache Airflow is simple but powerful. It allows skipping tasks based on the result of a condition. There are many reasons why you may want to stop running tasks. Let’s see how to use the ShortCircuitOperator and what you should be aware of. By the way, if you are new to Airflow, check my courses here ; you will get at a special discount.

Start Data Engineering
AUGUST 11, 2022
1. Introduction 2. Gathering requirements 2.1. Identify the end-users 2.2. Help end-users define the requirements 2.3. End-user validation 2.4. Deliver iteratively 2.5. Handling changing requirements/new features 3. Conclusion 4. Further reading 5. Reference 1. Introduction Data engineers are often caught off guard by undefined end-user assumptions.

Advertisement
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate

Confluent
AUGUST 11, 2022
Whether you’re new to stream processing or evaluating real-time data use cases, learn how stream processing works, its benefits, and the best way to get started.

Cloudera
AUGUST 17, 2022
?. What if you could access all your data and execute all your analytics in one workflow, quickly with only a small IT team? CDP One is a new service from Cloudera that is the first data lakehouse SaaS offering with cloud compute, cloud storage, machine learning (ML), streaming analytics, and enterprise grade security built-in. Data practitioners can now produce end to end analytic pipelines through one service.
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

|
Netflix Tech
AUGUST 1, 2022
Data Mesh?—?A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users. Our previous generation of streaming pipeline solution Keystone has a proven track record of serving multiple of our key business needs.

Data Engineering Podcast
AUGUST 28, 2022
Summary The dream of every engineer is to automate all of their tasks. For data engineers, this is a monumental undertaking. Orchestration engines are one step in that direction, but they are not a complete solution. In this episode Sean Knapp shares his views on what constitutes proper automation and the work that he and his team at Ascend are doing to help make it a reality.

Teradata
AUGUST 29, 2022
Teradata's new offerings, VantageCloud Lake and ClearScape Analytics, make it the complete cloud analytics & data platform, with cloud-native deployment and expanded analytics capabilities.

Confluent
AUGUST 17, 2022
Confluent Hackathon ‘22: Using Apache Kafka a Raspberry Pi, and a camera, Simon Aubury builds a detection and monitoring system to better understand wildlife population trends over time.

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.

Cloudera
AUGUST 30, 2022
Firms are burdened with tech debt and endless regulatory compliance, often leaving innovation last to receive the necessary budgets. Data-fuelled innovation requires a pragmatic strategy. This blog lays out some steps to help you incrementally advance efforts to be a more data-driven, customer-centric organization. Embrace incremental progress. The financial sector’s evolution is unleashing myriad demands on firms operating in the market.

KDnuggets
AUGUST 24, 2022
This blog post introduces seven techniques that are commonly applied in domains like intrusion detection or real-time bidding, because the datasets are often extremely imbalanced.
Netflix Tech
AUGUST 10, 2022
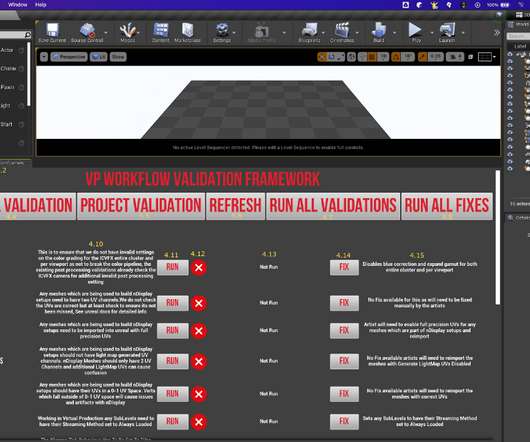
Virtual Production?—?A Validation Framework For Unreal Engine By Adam Davis, Jimmy Fusil, Bhanu Srikanth and Girish Balakrishnan Game Engines in Virtual Production The use of Virtual Production and real time technologies has markedly accelerated in the past few years. At Netflix, we are always thrilled to see technology enable new ways of telling stories, and the use of these techniques on some of our shows like 1899 and Super Giant Robot Brothers has given us a front row seat to this exciting e

Data Engineering Podcast
AUGUST 21, 2022
Summary Data has permeated every aspect of our lives and the products that we interact with. As a result, end users and customers have come to expect interactions and updates with services and analytics to be fast and up to date. In this episode Shruti Bhat gives her view on the state of the ecosystem for real-time data and the work that she and her team at Rockset is doing to make it easier for engineers to build those experiences.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.

Teradata
AUGUST 3, 2022
Teradata’s approach to the Smart City is an analytics-centric, city-data-ecosystem approach designed to give access across all relevant data. Find out more.

Confluent
AUGUST 10, 2022
Confluent’s ksqlDB product offers powerful, serverless stream processing tools that maximize Kafka on Azure.

Cloudera
AUGUST 4, 2022
Z-order is an ordering for multi-dimensional data, e.g. rows in a database table. Once data is in Z-order it is possible to efficiently search against more columns. This article reveals how Z-ordering works and how one can use it with Apache Impala. In a previous blog post , we demonstrated the power of Parquet page indexes, which can greatly improve the performance of selective queries.

KDnuggets
AUGUST 19, 2022
Explaining the approach to solving a few complex SQL queries.

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri

Netflix Tech
AUGUST 24, 2022
by Ehtsham Elahi with James McInerney , Nathan Kallus , Dario Garcia Garcia and Justin Basilico Introduction This writeup is about using reinforcement learning to construct an optimal list of recommendations when the user has a finite time budget to make a decision from the list of recommendations. Working within the time budget introduces an extra resource constraint for the recommender system.

Data Engineering Podcast
AUGUST 21, 2022
Summary The position of Chief Data Officer (CDO) is relatively new in the business world and has not been universally adopted. As a result, not everyone understands what the responsibilities of the role are, when you need one, and how to hire for it. In this episode Tracy Daniels, CDO of Truist, shares her journey into the position, her responsibilities, and her relationship to the data professionals in her organization.

Teradata
AUGUST 17, 2022
In conversations with c-level execs at banks & financial institutions, one theme always crops up. How do we change our operating model to be more agile & customer focused in a digital first world?

Confluent
AUGUST 16, 2022
Learn how you can integrate data streams into your environment, and enrich data across your existing data pipelines using Confluent Cloud.

Advertisement
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.

Cloudera
AUGUST 11, 2022
We’ve come a long way since 1778 when George Washington’s spies gathered and shared military intelligence on the British Army’s tactical operations in occupied New York. But information broadly, and the management of data specifically, is still “the” critical factor for situational awareness, streamlined operations, and a host of other use cases across today’s tech-driven battlefields. .

KDnuggets
AUGUST 15, 2022
ETL during the process of producing effective machine learning algorithms is found at the base - the foundation. Let’s go through the steps on how ETL is important to machine learning.

dbt Developer Hub
AUGUST 17, 2022
When running a job that has over 1,700 models, how do you know what a “good” runtime is? If the total process takes 3 hours, is that fantastic or terrible? While there are many possible answers depending on dataset size, complexity of modeling, and historical run times, the crux of the matter is normally “did you hit your SLAs”? However, in the cloud computing world where bills are based on usage, the question is really “did you hit your SLAs and stay within budget ”?

Data Engineering Podcast
AUGUST 13, 2022
Summary Data is useless if it isn’t being used, and you can’t use it if you don’t know where it is. Data catalogs were the first solution to this problem, but they are only helpful if you know what you are looking for. In this episode Shinji Kim discusses the challenges of data discovery and how to collect and preserve additional context about each piece of information so that you can find what you need when you don’t even know what you’re looking for yet.

Advertisement
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?

Teradata
AUGUST 10, 2022
Retail and CPG businesses are trapped by the disconnect between today’s digital customers and long-established demand forecasting and supply-chain processes. Find out more.

Confluent
AUGUST 31, 2022
Kafka Raft lets you use Apache Kafka without ZooKeeper by consolidating metadata management. Here’s how you can learn and do more with KRaft.

Cloudera
AUGUST 8, 2022
In June 2022, Cloudera announced the general availability of Apache Iceberg in the Cloudera Data Platform (CDP). Iceberg is a 100% open-table format, developed through the Apache Software Foundation , which helps users avoid vendor lock-in and implement an open lakehouse. . The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera Data Warehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ).

KDnuggets
AUGUST 12, 2022
Increasing accuracy in your models is often obtained through the first steps of data transformations. This guide explains the difference between the key feature scaling methods of standardization and normalization, and demonstrates when and how to apply each approach.

Advertisement
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you

Expert insights. Personalized for you.





Let's personalize your content