This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
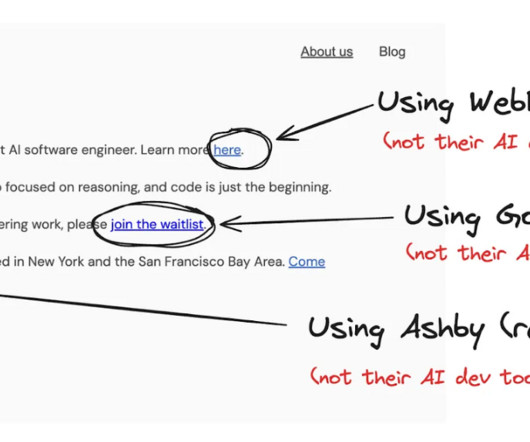
This article was published on 14 March 2024 in The Pragmatic Engineer, for subscribers. I'm sharing this piece in public more than a month later, as it provides important context and analysis for the AI dev tools space. Subscribe to The Pragmatic Engineer to stay up-to-date on what is happening with software engineering, Big Tech, and startups.
1. Introduction 2. Project demo 3. TL;DR 4. Building efficient data pipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Use DuckDB 4.4. Distributed systems are scalable, resilient to failures, & designed for high availability 4.5.
Of all the duties that Data Engineers take on during the regular humdrum of business and work, it’s usually filled with the same old, same old. Build new pipeline, update pipeline, new data model, fix bug, etc, etc. It’s never-ending. It’s a constant stream of data, new and old, spilling into our Data Warehouses and […] The post Building Data Platforms (from scratch) appeared first on Confessions of a Data Guy.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Summary Building a data platform is a substrantial engineering endeavor. Once it is running, the next challenge is figuring out how to address release management for all of the different component parts. The services and systems need to be kept up to date, but so does the code that controls their behavior. In this episode your host Tobias Macey reflects on his current challenges in this area and some of the factors that contribute to the complexity of the problem.
Discover the exciting new features of ArcGIS Pro 3.3. From water flow modeling to direct PDF support, this release has it all. Read our blog to learn more.
Discover the exciting new features of ArcGIS Pro 3.3. From water flow modeling to direct PDF support, this release has it all. Read our blog to learn more.
1. Introduction 2. TL;DR 3. Enabling Stakeholder data access with RAGs 3.1. Set up 3.1.1. Pre-requisite 3.1.2. Demo 3.1.3. Key terminology 3.2. Loading: Read raw data and convert them into LlamaIndex data structures 3.2.1. Read data from structured and unstructured sources 3.2.2. Transform data into LlamaIndex data structures 3.3. Indexing: Generate & store numerical representation of your data 3.
I’m still amazed to this day how many folks hold onto stuff they love, they just can’t let it go. I get it, sorta, I’m the same way. There are reasons why people do the things they do, even if they are hard for us to understand. It blows my mind when I see something […] The post Why You Should Replace Pandas with Polars appeared first on Confessions of a Data Guy.
Summary Artificial intelligence has dominated the headlines for several months due to the successes of large language models. This has prompted numerous debates about the possibility of, and timeline for, artificial general intelligence (AGI). Peter Voss has dedicated decades of his life to the pursuit of truly intelligent software through the approach of cognitive AI.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
We are excited to introduce Databricks Assistant Autocomplete now in Public Preview. This feature brings the AI-powered assistant to you in real-time, providing.
Robinhood Crypto customers in the United States can now use our API to view crypto market data, manage portfolios and account information, and place crypto orders programmatically Today, we are excited to announce the Robinhood Crypto trading API , ushering in a new era of convenience, efficiency, and strategy for our most seasoned crypto traders. Robinhood Crypto customers in the United States can use our new trading API to set up advanced and automated trading strategies that allow them to st
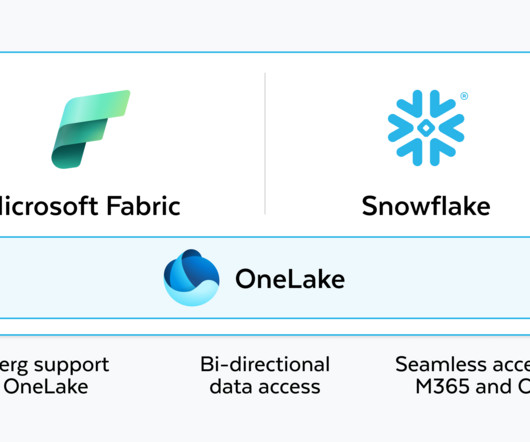
Today we’re excited to announce an expansion of our partnership with Microsoft to deliver a seamless and efficient interoperability experience between Snowflake and Microsoft Fabric OneLake, in preview later this year. This will enable our joint customers to experience bidirectional data access between Snowflake and Microsoft Fabric, with a single copy of data with OneLake in Fabric.
by Herbert Kateu 1. Introduction This article is a follow-up to the websocket article that was published previously. To recap, we created an in-memory chat application using WebSockets with the help of the Http4s library. The chat application had a variety of features implemented through commands directly in the chat window such as the ability to create users, create chat rooms, and switch between chat rooms.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
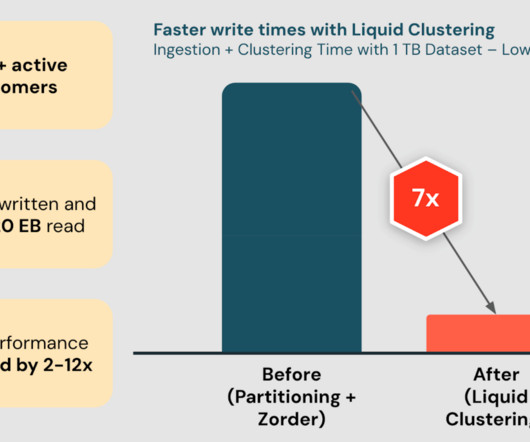
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.
How companies data model varies widely. They might say they use Kimball dimensional modeling. However, when you look in their data warehouse the only part you recognize is the word fact and dim. Over the past near decade, I have worked for and with different companies that have used various methods to capture this data.… Read more The post How To Data Model – Real Life Examples Of How Companies Model Their Data appeared first on Seattle Data Guy.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Accelerating enterprise AI use cases into production is now a board-level priority for most companies. However, one of the key challenges in AI today is ensuring that those use cases are ready for real-life use and continue to perform at a high level in production. Not only must enterprises ensure accurate, reliable, and valuable results they must also address and mitigate critical issues like bias, hallucinations, and toxicity.
Last week I was speaking in Gdansk on the DataMass track at Infoshare. As it often happens, the talk time slot impacted what I wanted to share but maybe it's for good. Otherwise, you wouldn't read stream processing fallacies!
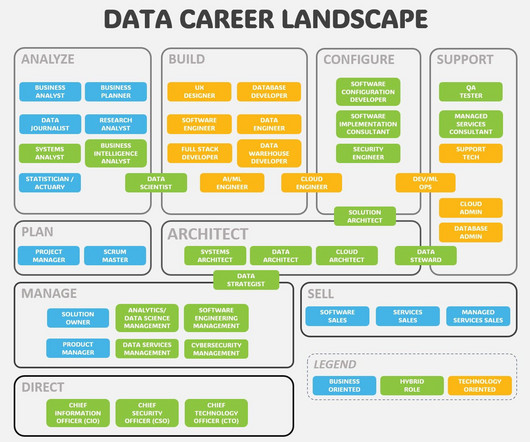
We are all looking for the right opportunities in our career. In the landscape of data-related careers, the roles can be grouped into classes, and future opportunities tend to follow natural migration paths between the class groups.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
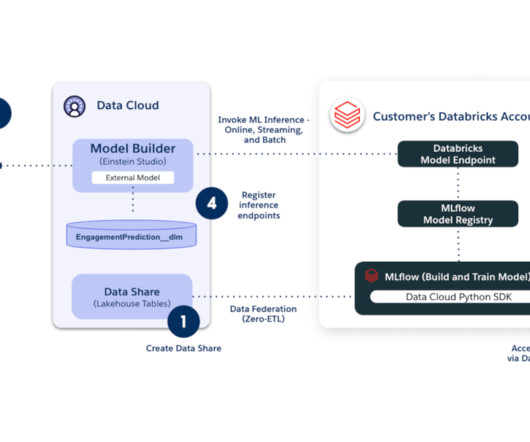
Salesforce and Databricks are excited to announce an expanded strategic partnership that delivers a powerful new integration - Salesforce Bring Your Own Model.
Many data engineers and analysts don’t realize how valuable the knowledge they have is. They’ve spent hours upon hours learning SQL, Python, how to properly analyze data, build data warehouses, and understand the differences between eight different ETL solutions. Even what they might think is basic knowledge could be worth $10,000 to $100,000+ for a… Read more The post Why Data Analysts And Engineers Make Great Consultants appeared first on Seattle Data Guy.
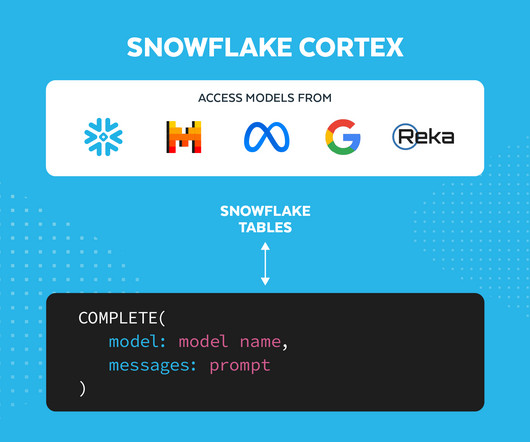
Snowflake Cortex is a fully-managed service that enables access to industry-leading large language models (LLMs) is now generally available. You can use these LLMs in select regions directly via LLM Functions on Cortex so you can bring generative AI securely to your governed data. Your team can focus on building AI applications, while we handle model optimization and GPU infrastructure to deliver cost-effective performance.
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. Sriram Panyam has been involved in several projects that required migration of large volumes of data in high traffic environments. In this episode he shares some of the valuable lessons that he learned about how to make those projects successful.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
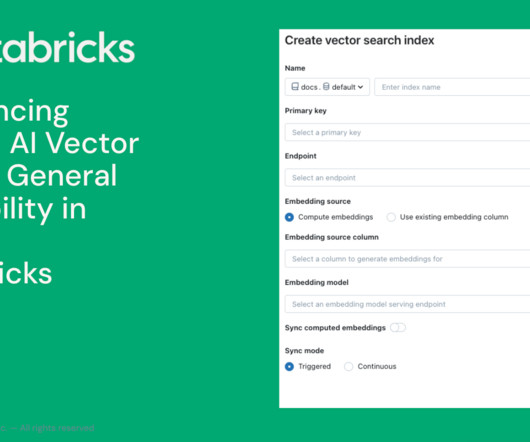
Following the announcement we made around a suite of tools for Retrieval Augmented Generation, today we are thrilled to announce the general availability.
Lights on ( credits ) Hello you. The sun is out, the days are getting longer and Data News is still here. Next week marks 3 years of this newsletter/blog (yay 🎉 ). It'll be a time for looking back, reflecting and celebrating, but next week. This week, we reached 5000 members. Yes, 5000 of you read my content periodically. Just thank you ❤️ In the recent days I've been working on a new side project.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content