This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The purpose of business intelligence systems is to allow anyone in the business to access and decode data to help them make informed decisions. Unfortunately this often turns into an exercise in frustration for everyone involved due to complex workflows and hard-to-understand dashboards. The team at Zenlytic have leaned on the promise of large language models to build an AI agent that lets you converse with your data.
1. Introduction 2. Project demo 3. TL;DR 4. Building efficient data pipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Use DuckDB 4.4. Distributed systems are scalable, resilient to failures, & designed for high availability 4.5.
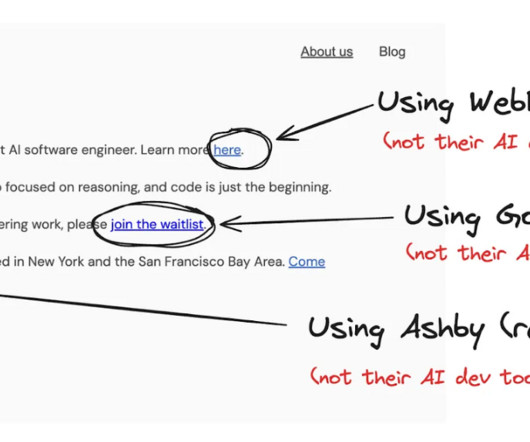
This article was published on 14 March 2024 in The Pragmatic Engineer, for subscribers. I'm sharing this piece in public more than a month later, as it provides important context and analysis for the AI dev tools space. Subscribe to The Pragmatic Engineer to stay up-to-date on what is happening with software engineering, Big Tech, and startups.
Of all the duties that Data Engineers take on during the regular humdrum of business and work, it’s usually filled with the same old, same old. Build new pipeline, update pipeline, new data model, fix bug, etc, etc. It’s never-ending. It’s a constant stream of data, new and old, spilling into our Data Warehouses and […] The post Building Data Platforms (from scratch) appeared first on Confessions of a Data Guy.
With over 30 million monthly downloads, Apache Airflow is the tool of choice for programmatically authoring, scheduling, and monitoring data pipelines. Airflow enables you to define workflows as Python code, allowing for dynamic and scalable pipelines suitable to any use case from ETL/ELT to running ML/AI operations in production. This introductory tutorial provides a crash course for writing and deploying your first Airflow pipeline.
Summary Building a data platform is a substrantial engineering endeavor. Once it is running, the next challenge is figuring out how to address release management for all of the different component parts. The services and systems need to be kept up to date, but so does the code that controls their behavior. In this episode your host Tobias Macey reflects on his current challenges in this area and some of the factors that contribute to the complexity of the problem.
Summary Building a data platform is a substrantial engineering endeavor. Once it is running, the next challenge is figuring out how to address release management for all of the different component parts. The services and systems need to be kept up to date, but so does the code that controls their behavior. In this episode your host Tobias Macey reflects on his current challenges in this area and some of the factors that contribute to the complexity of the problem.
1. Introduction 2. TL;DR 3. Enabling Stakeholder data access with RAGs 3.1. Set up 3.1.1. Pre-requisite 3.1.2. Demo 3.1.3. Key terminology 3.2. Loading: Read raw data and convert them into LlamaIndex data structures 3.2.1. Read data from structured and unstructured sources 3.2.2. Transform data into LlamaIndex data structures 3.3. Indexing: Generate & store numerical representation of your data 3.
Discover the exciting new features of ArcGIS Pro 3.3. From water flow modeling to direct PDF support, this release has it all. Read our blog to learn more.
I’m still amazed to this day how many folks hold onto stuff they love, they just can’t let it go. I get it, sorta, I’m the same way. There are reasons why people do the things they do, even if they are hard for us to understand. It blows my mind when I see something […] The post Why You Should Replace Pandas with Polars appeared first on Confessions of a Data Guy.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Robinhood Crypto customers in the United States can now use our API to view crypto market data, manage portfolios and account information, and place crypto orders programmatically Today, we are excited to announce the Robinhood Crypto trading API , ushering in a new era of convenience, efficiency, and strategy for our most seasoned crypto traders. Robinhood Crypto customers in the United States can use our new trading API to set up advanced and automated trading strategies that allow them to st
Summary Artificial intelligence has dominated the headlines for several months due to the successes of large language models. This has prompted numerous debates about the possibility of, and timeline for, artificial general intelligence (AGI). Peter Voss has dedicated decades of his life to the pursuit of truly intelligent software through the approach of cognitive AI.
Introduction Data is stored on disk and processed in memory Running the code Run on Codespaces Run on your laptop Using python REPL Python basics Python is used for extracting data from sources, transforming it, & loading it into a destination [Extract & Load] Read and write data to any system [Transform] Process data in Python or instruct the database to process it [Data Quality] Define what you expect of your data and check if your data confirms it [Code Testing] Ensure your code does
by Herbert Kateu 1. Introduction This article is a follow-up to the websocket article that was published previously. To recap, we created an in-memory chat application using WebSockets with the help of the Http4s library. The chat application had a variety of features implemented through commands directly in the chat window such as the ability to create users, create chat rooms, and switch between chat rooms.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
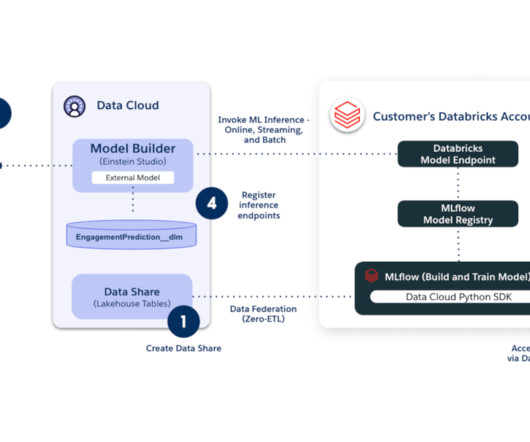
Salesforce and Databricks are excited to announce an expanded strategic partnership that delivers a powerful new integration - Salesforce Bring Your Own Model.
How companies data model varies widely. They might say they use Kimball dimensional modeling. However, when you look in their data warehouse the only part you recognize is the word fact and dim. Over the past near decade, I have worked for and with different companies that have used various methods to capture this data.… Read more The post How To Data Model – Real Life Examples Of How Companies Model Their Data appeared first on Seattle Data Guy.
Last week I was speaking in Gdansk on the DataMass track at Infoshare. As it often happens, the talk time slot impacted what I wanted to share but maybe it's for good. Otherwise, you wouldn't read stream processing fallacies!
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. Sriram Panyam has been involved in several projects that required migration of large volumes of data in high traffic environments. In this episode he shares some of the valuable lessons that he learned about how to make those projects successful.
Lights on ( credits ) Hello you. The sun is out, the days are getting longer and Data News is still here. Next week marks 3 years of this newsletter/blog (yay 🎉 ). It'll be a time for looking back, reflecting and celebrating, but next week. This week, we reached 5000 members. Yes, 5000 of you read my content periodically. Just thank you ❤️ In the recent days I've been working on a new side project.
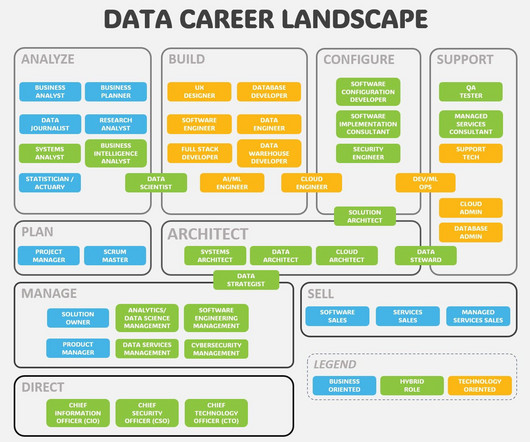
We are all looking for the right opportunities in our career. In the landscape of data-related careers, the roles can be grouped into classes, and future opportunities tend to follow natural migration paths between the class groups.
Speaker: Jay Allardyce, Deepak Vittal, Terrence Sheflin, and Mahyar Ghasemali
As we look ahead to 2025, business intelligence and data analytics are set to play pivotal roles in shaping success. Organizations are already starting to face a host of transformative trends as the year comes to a close, including the integration of AI in data analytics, an increased emphasis on real-time data insights, and the growing importance of user experience in BI solutions.
Many data engineers and analysts don’t realize how valuable the knowledge they have is. They’ve spent hours upon hours learning SQL, Python, how to properly analyze data, build data warehouses, and understand the differences between eight different ETL solutions. Even what they might think is basic knowledge could be worth $10,000 to $100,000+ for a… Read more The post Why Data Analysts And Engineers Make Great Consultants appeared first on Seattle Data Guy.
A question that comes up often … “How do I develop Production Level Databricks Pipelines?” Or maybe someone just has a feeling that using Notebooks all day long is expensive and ends up being an unreliable way to produce Databricks Spark + Delta Lake pipelines that run well … without error. It isn’t really that […] The post Developing Production Level Databricks Pipelines. appeared first on Confessions of a Data Guy.
That's one of my recent surprises. While I have been exploring arbitrary stateful processing, hence the mapGroupsWithState among others, I mistakenly created a batch DataFrame and applied the mapping function on top of it. Turns out, it worked! Well, not really but I let you discover why in this blog post.
Speaker: Nikhil Joshi, Founder & President of Snic Solutions
Is your manufacturing operation reaching its efficiency potential? A Manufacturing Execution System (MES) could be the game-changer, helping you reduce waste, cut costs, and lower your carbon footprint. Join Nikhil Joshi, Founder & President of Snic Solutions, in this value-packed webinar as he breaks down how MES can drive operational excellence and sustainability.
Getting data out of source systems and into a data warehouse or data lake is one of the first steps in making it usable by analysts and data scientists. The question is how will your team do that? Will they write custom data connectors, pay for a data connector out of the box or perhaps… Read more The post 4 ELT Alternatives To Airbyte – How To Ingest Your Data appeared first on Seattle Data Guy.
Whether you’re creating complex dashboards or fine-tuning large language models, your data must be extracted, transformed, and loaded. ETL and ELT pipelines form the foundation of any data product, and Airflow is the open-source data orchestrator specifically designed for moving and transforming data in ETL and ELT pipelines. This eBook covers: An overview of ETL vs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content