This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is an idempotent function Pre-requisites Why idempotency matters Making your data pipeline idempotent Conclusion Further reading References What is an idempotent function “Idempotence is the property of certain operations in mathematics and computer science whereby they can be applied multiple times without changing the result beyond the initial application” - wikipedia Defined as f(f(x)) = f(x) In the data engineering context, this can come to mean that: running a data pipeline
API gateways are an integral part of microservices architecture in recent years. An API gateway provides a single point of entry for all our apps and provides an interface to access data, logic, or functionality from back-end microservices. It also … The post The Architecture of Uber’s API gateway appeared first on Uber Engineering Blog.
Introduction. In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. This year, we expanded our partnership with NVIDIA , enabling your data teams to dramatically speed up compute processes for data engineering and data science workloads with no code changes using RAPIDS AI.
We are excited to announce that Confluent for Kubernetes is generally available! Today, we are enabling our customers to realize many of the benefits of our cloud service with the […].
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Summary The data warehouse has become the focal point of the modern data platform. With increased usage of data across businesses, and a diversity of locations and environments where data needs to be managed, the warehouse engine needs to be fast and easy to manage. Yellowbrick is a data warehouse platform that was built from the ground up for speed, and can work across clouds and all the way to the edge.
Catalog & Cocktails podcast hosts Tim Gasper & Juan Sequeda of data.world interview DataKitchen CEO Chris Bergh on how to create the right DataOps culture & measuring the value of your DataOps strategy. The post What’s the Secret Recipe for DataOps? first appeared on DataKitchen.
Part of our series on who works in Analytics at Netflix?—?and what the role entails By Sean Barnes, Studio Production Data Science & Engineering I am going to tell you a story about a person that works for Netflix. That person grew up dreaming of working in the entertainment industry. They attended the University of Southern California, double majored in data science and television & film production, and graduated summa cum laude.
Apache YuniKorn (Incubating) has just released 0.10.0 ( release announcement ). As part of this release, a new feature called Gang Scheduling has become available. By leveraging the Gang Scheduling feature, Spark jobs scheduling on Kubernetes becomes more efficient. What is Apache YuniKorn (Incubating)? Apache YuniKorn (Incubating) is a new Apache incubator project that offers rich scheduling capabilities on Kubernetes.
With so many technologies in the modern development ecosystem, a common complaint is having to go through the mental gymnastics of adopting new products and keeping up with ever-expanding feature […].
Summary Machine learning models use vectors as the natural mechanism for representing their internal state. The problem is that in order for the models to integrate with external systems their internal state has to be translated into a lower dimension. To eliminate this impedance mismatch Edo Liberty founded Pinecone to build database that works natively with vectors.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Data errors impact decision-making. When analytics and dashboards are inaccurate, business leaders may not be able to solve problems and pursue opportunities. Data errors infringe on work-life balance. They cause people to work long hours at the expense of personal and family time. Data errors also affect careers. If you have been in the data profession for any length of time, you probably know what it means to face a mob of stakeholders who are angry about inaccurate or late analytics.
Big Data enjoys the hype around it and for a reason. But the understanding of the essence of Big Data and ways to analyze it is still blurred. The truth is, there’s more to this term than just the size of information generated. Not only does Big Data apply to the huge volumes of continuously growing data that come in different formats, but it also refers to the range of processes, tools, and approaches used to gain insights from that data.
This blog post was written by Pedro Pereira as a guest author for Cloudera. . Right now, someone somewhere is writing the next fake news story or editing a deepfake video. An authoritarian regime is manipulating an artificial intelligence (AI) system to spy on technology users. No matter how good the intentions behind the development of a technology, someone is bound to corrupt and manipulate it.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
And that’s a wrap on Kafka Summit Europe 2021, the first of three global Kafka Summits this year. We’ve seen 17,000 registrations from over 7,000 companies and 137 different countries. […].
Summary Data governance is a phrase that means many different things to many different people. This is because it is actually a concept that encompasses the entire lifecycle of data, across all of the people in an organization who interact with it. Stijn Christiaens co-founded Collibra with the goal of addressing the wide variety of technological aspects that are necessary to realize such an important and expansive process.
A file and folder interface for Netflix Cloud Services Written by Vikram Krishnamurthy , Kishore Kasi , Abhishek Kapatkar , and Tejas Chopra In this post, we are introducing Netflix Drive, a Cloud drive for media assets and providing a high level overview of some of its features and interfaces. We intend this to be a first post in a series of posts covering Netflix Drive.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
After the shock of COVID exposed the brittle nature of many global supply chains, focus has shifted to resilience, a necessary consideration but not the only one.
The introduction of CDP Public Cloud has dramatically reduced the time in which you can be up and running with Cloudera’s latest technologies, be it with containerised Data Warehouse , Machine Learning , Operational Database or Data Engineering experiences or the multi-purpose VM-based Data Hub style of deployment. In CDP Private Cloud, the introduction of Cloudera Data Warehouse and Cloudera Machine Learning Experiences on RedHat OpenShift Kubernetes clusters means that we can deploy new
Our team was recently notified of unauthorized read-only access to Confluent’s Github account stemming from the recent Codecov incident (more information here). The security of our customers and their data […].
Summary Data lineage is the common thread that ties together all of your data pipelines, workflows, and systems. In order to get a holistic understanding of your data quality, where errors are occurring, or how a report was constructed you need to track the lineage of the data from beginning to end. The complicating factor is that every framework, platform, and product has its own concepts of how to store, represent, and expose that information.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Written by Colby Callahan , Megha Manohara , and Mike Azar. Managing and operating asynchronous workflows can be difficult without the proper tools and architecture that puts observability, debugging, and tracing at the forefront. Imagine getting paged outside normal work hours?—?users are having trouble with the application you’re responsible for, and you start diving into logs.
When integrating with Destinations , there are generally two main approaches made available by API providers: single or batched. With the "single" approach, one API request usually affects a single profile in the destination. The "batched" approach, which you can read more about here , allows you to affect multiple profiles in a single API request.
The sharing of client data in an Open Banking marketplace challenges banks to adopt a customer-centric approach & collaborate with new players to re-define their relevance.
Last year presented business and organizational challenges that hadn’t been seen in a century and the troubling fact is that the challenges applied pains and gains unequally across industry segments. While brick-and-mortar retail was crushed a year ago with mandated store closures, digital commerce retailers realized ten years of digital sales penetration in only three months.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
We’re pleased to announce ksqlDB 0.18.0! This release includes pull queries on table-table joins and support for variable substitution in the Java client and ksqlDB’s migration tool. We’ll step through […].
Summary There is a lot of attention on the database market and cloud data warehouses. While they provide a measure of convenience, they also require you to sacrifice a certain amount of control over your data. If you want to build a warehouse that gives you both control and flexibility then you might consider building on top of the venerable PostgreSQL project.
At Ripple , we are moving towards building complex business models out of raw data. To do this successfully, we need to automate our historically manual processes. Even with a digital-first approach, many of our internal processes were done by hand, making them great candidates to be automated. A prime example of this was the process of managing our data transformation workflows.
With Microsoft Build 2021 currently underway, what better time to take a beginner-friendly deep dive into Azure Data Factory. In this post, we’ll talk about what Azure Data Factory is, how to get started using it, and what you might use it for. Keep up with all things Azure in the ACG original series Azure […] The post What is Azure Data Factory?
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









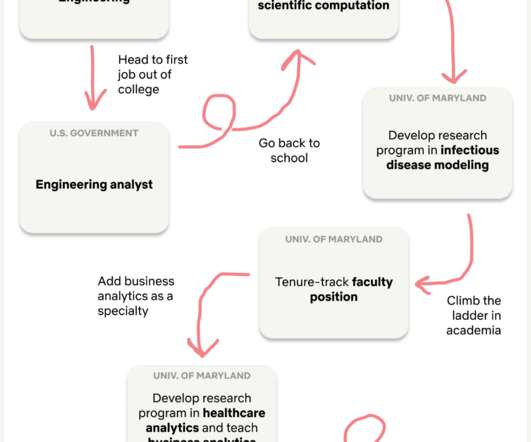


























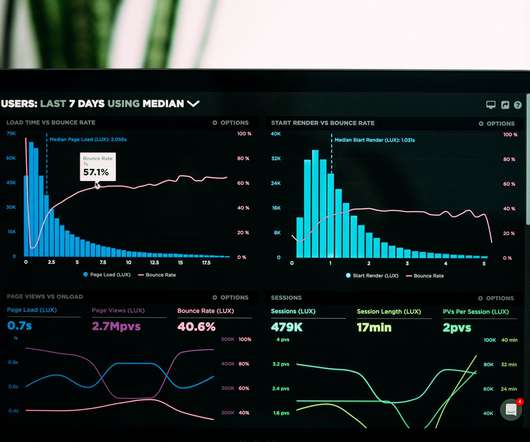








Let's personalize your content