This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To be proficient as a data engineer, you need to know various toolkitsfrom fundamental Linux commands to different virtual environments and optimizing efficiency as a data engineer. This article focuses on the building blocks of data engineering work, such as operating systems, development environments, and essential tools. We’ll start from the ground upexploring crucial Linux commands, containerization with Docker, and the development environments that make modern data engineering possibl
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? How does a self-driving car understand a chaotic street scene? The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
1. Introduction 2. Centralize Metric Definitions in Code Option A: Semantic Layer for On-the-Fly Queries Option B: Pre-Aggregated Tables for Consumers 3. Conclusion & Recap 4. Required Reading 1. Introduction If youve worked on a data team, youve likely encountered situations where multiple teams define metrics in slightly different ways, leaving you to untangle why discrepancies exist.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. This allows us to verify that our users everyday interactions are protected across our family of apps, such as their religious views in the Facebook Dating app, the example well walk through in this
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
If AI agents are going to deliver ROI, they need to move beyond chat and actually do things. But, turning a model into a reliable, secure workflow agent isn’t as simple as plugging in an API. In this new webinar, Alex Salazar and Nate Barbettini will break down the emerging AI architecture that makes action possible, and how it differs from traditional integration approaches.
Artificial Intelligence (AI) is all the rage, and rightly so. By now most of us have experienced how Gen AI and the LLMs (large language models) that fuel it are primed to transform the way we create, research, collaborate, engage, and much more. Yet along with the AI hype and excitement comes very appropriate sanity-checks asking whether AI is ready for prime-time.
Hi, this is Gergely with a bonus issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. This article is one out of five sections from The Pulse #119. Full subscribers received this issue a week and a half ago. To get articles like this in your inbox, subscribe here.
HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. There are multiple ways to start a new year, either with new projects, new ideas, new resolutions or by just keeping doing the same music. I hope you will enjoy 2025. The Data News are here to stay, the format might vary during the year, but here we are for another year. Thank you so much for your support through the years.
HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. There are multiple ways to start a new year, either with new projects, new ideas, new resolutions or by just keeping doing the same music. I hope you will enjoy 2025. The Data News are here to stay, the format might vary during the year, but here we are for another year. Thank you so much for your support through the years.
A few months ago I wrote a blog post about event skew and how dangerous it is for a stateful streaming job. Since it was a high-level explanation, I didn't cover Apache Spark Structured Streaming deeply at that moment. Now the watermark topic is back to my learning backlog and it's a good opportunity to return to the event skew topic and see the dangers it brings for Structured Streaming stateful jobs.
Though AI is (still) the hottest technology topic, its not the overriding issue for enterprise security in 2025. Advanced AI will open up new attack vectors and also deliver new tools for protecting an organizations data. But the underlying challenge is the sheer quantity of data that overworked cybersecurity teams face as they try to answer basic questions such as, Are we under attack?
Every once in a great while, the question comes up: “How do I test my Databricks codebase?” It’s a fair question, and if you’re new to testing your code, it can seem a little overwhelming on the surface. However, I assure you the opposite is the case. Testing your Databricks codebase is no different than […] The post Testing and Development for Databricks Environment and Code. appeared first on Confessions of a Data Guy.
PDF files are one of the most popular file formats today. Because they can preserve the visual layout of documents and are compatible with a wide range of devices and operating systems, PDFs are used for everything from business forms and educational material to creative designs. However, PDF files also present multiple challenges when it… Read more The post What Is PDFMiner And Should You Use It – How To Extract Data From PDFs appeared first on Seattle Data Guy.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Were sharing details about Strobelight, Metas profiling orchestrator. Strobelight combines several technologies, many open source, into a single service that helps engineers at Meta improve efficiency and utilization across our fleet. Using Strobelight, weve seen significant efficiency wins, including one that has resulted in an estimated 15,000 servers worth of annual capacity savings.
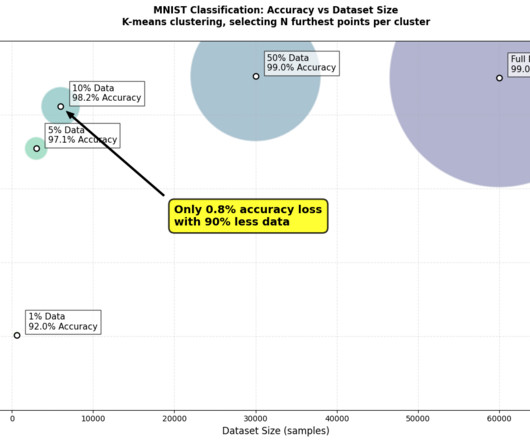
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. I experimented with data pruning on MNIST to classify handwritten digits. Best runs for furthest-from-centroid selection compared to full dataset. Image byauthor. What if I told you that using just 50% of your training data could achieve better results than using the fulldataset?
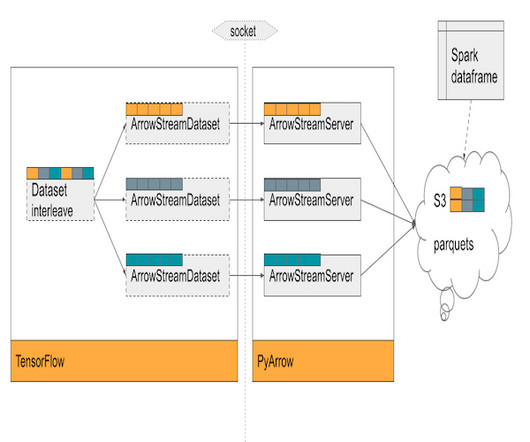
At Yelp, we encountered challenges that prompted us to enhance the training time of our ad-revenue generating models, which use a Wide and Deep Neural Network architecture for predicting ad click-through rates (pCTR). These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions. This blog post delves into our journey of optimizing training time using TensorFlow and Horovod, along with the development of ArrowStreamServer, our in-house library for lo
People often ask me, Why did you join Snowflake, and why did you choose to work on developer productivity? I joined Snowflake to learn from world-class engineers and be part of the highly collaborative culture. These have been the secret sauce to Snowflakes rocket-ship growth. Snowflake was embarking on a remarkable transformation of developer productivity, and I had to jump on the rocket ship as it was taking off!
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Building fun things is a real part of Data Engineering. Using your creative side when building a Lake House is possible, and using tools that are outside the normal box can sometimes be preferable. Checkout this video where I dive into how I build just such a Lake House using Modern Data Stack tools like […] The post Building a Fast, Light, and CHEAP Lake House with DuckDB, Delta Lake, and AWS Lambda appeared first on Confessions of a Data Guy.
Key Takeaways: Prioritize metadata maturity as the foundation for scalable, impactful data governance. Recognize that artificial intelligence is a data governance accelerator and a process that must be governed to monitor ethical considerations and risk. Integrate data governance and data quality practices to create a seamless user experience and build trust in your data.
Do types actually make developers more productive? Or is it just more typing on the keyboard? To answer that question were revisiting Diff Authoring Time (DAT) how Meta measures how long it takes to submit changes to a codebase. DAT is just one of the ways e measure developer productivity and this latest episode of the Meta Tech Podcast takes a look at two concrete use cases for DAT, including a type-safe mocking framework in Hack.
In todays dynamic digital landscape, multi-cloud strategies have become vital for organizations aiming to leverage the best of both cloud and on-premises environments. As enterprises navigate complex data-driven transformations, hybrid and multi-cloud models offer unmatched flexibility and resilience. Heres a deep dive into why and how enterprises master multi-cloud deployments to enhance their data and AI initiatives.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Part 2: Navigating Ambiguity By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques Building on the foundation laid in Part 1 , where we explored the what behind the challenges of title launch observability at Netflix, this post shifts focus to the how. How do we ensure every title launches seamlessly and remains discoverable by the right audience?
Y Combinator founder Paul Graham advises startup founders to live in the future, then build whats missing. I had the privilege of glimpsing the future through a series of interviews with investors on the bleeding edge of the AI landscape. Insights from these candid conversations laid the foundation for Startup 2025: Building a Business in the Age of AI, the AI startup report that Snowflake is publishing today.
A Deep Dive into Databricks Labs’ DQX: The Data Quality Game Changer for PySpark DataFrames Recently, a LinkedIn announcement caught my eyeand honestly, it had me on the edge of my seat. Databricks Labs has unveiled DQX, a Python-based Data Quality framework explicitly designed for PySpark DataFrames. Finally, a Dedicated Data Quality Tool for PySpark […] The post PySpark Data Quality on Databricks with DQX. appeared first on Confessions of a Data Guy.
Ever since dbt Labs acquired SDF Labs last week , I've been head-down diving into their technology and making sense of it all. The main thing I knew going in was "SDF understands SQL". It's a nice pithy quote, but the specifics are fascinating. For the next era of Analytics Engineering to be as transformative as the last, dbt needs to move beyond being a string preprocessor and into fully comprehending SQL.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
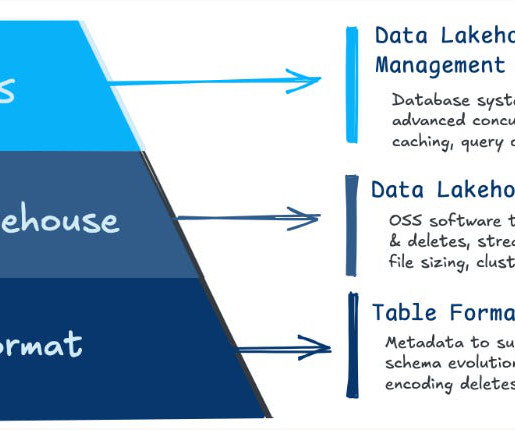
What if your data lake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data. To explore this future, I recently sat down with Vinoth Chandar, founder of Onehouse and creator of Apache Hudi, for a fireside chat about the trends shaping the data landscape.
Airports are an interconnected system where one unforeseen event can tip the scale into chaos. For a smaller airport in Canada, data has grown to be its North Star in an industry full of surprises. In order for data to bring true value to operationsand ultimately customer experiencesthose data insights must be grounded in trust. Ryan Garnett, Senior Manager Business Solutions of Halifax International Airport Authority, joined The AI Forecast to share how the airport revamped its approach to data
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need to catch up? Check out Part 1. In this article, we highlight a few exciting analytic business applications, and in our final article well go into aspects of the technical craft.
Across all industries, generative AI is driving innovation and transforming how we work. Use cases range from getting immediate insights from unstructured data such as images, documents and videos, to automating routine tasks so you can focus on higher-value work. Gen AI makes this all easy and accessible because anyone in an enterprise can simply interact with data by using natural language.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
You know, for all the hoards of content, books, and videos produced in the “Data Space” over the last few years, famous or others, it seems I find there are volumes of information on the pieces and parts of working in Data. It could be Data Quality, Data Modeling, Data Pipelines, Data Storage, Compute, and […] The post What is a Data Platform?
A Name That Matches the Moment For years, Clouderas platform has helped the worlds most innovative organizations turn data into action. As the AI landscape evolves from experiments into strategic, enterprise-wide initiatives, its clear that our naming should reflect that shift. Thats why were moving from Cloudera Machine Learning to Cloudera AI. This isnt just a new label or even AI washing.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content