This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The below was originally published in The Pragmatic Engineer. To get timely analysis on the tech industry like this, on a weekly basis: sign up to The Pragmatic Engineer Newsletter. If you are into podcasts, check out The Pragmatic Engineer Podcast. Imagine Apple decided Spotify was a big enough business threat that it had to take unfair measures to limit Spotify’s growth on the App Store.
Unapologetically Technical’s newest episode is now live! In this episode of Unapologetically Technical, I interview Cliff Crosland, the co-founder and CEO of Scanner.dev. Cliff Crosland is a data engineer passionate about helping people wrangle massive log volumes. He sees logs as a treasure trove of insights and believes effective log analysis is critical in today’s complex systems.
Key Takeaways: Data mesh is a decentralized approach to data management, designed to shift creation and ownership of data products to domain-specific teams. Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. Both approaches empower your organization to be more agile, data-driven, and responsive so you can make informed decisions in real time.
I am a glutton for punishment, a harbinger of tidings, a storm crow, a prophet of the data land, my sole purpose is to plumb the depths of the tools we use every day in Data Engineering. I find the good, the bad, the ugly, and splay them out before you, string ’em up and […] The post Testing DuckDB’s Large Than Memory Processing Capabilities. appeared first on Confessions of a Data Guy.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Demystifying Azure Storage Account Network Access Service endpoints and private endpoints hands-on: including Azure Backbone, storage account firewall, DNS, VNET and NSGs Connected Network — image by Nastya Dulhiier on Unsplash 1. Introduction Storage accounts play a vital role in a medallion architecture for establishing an enterprise data lake. They act as a centralized repository, enabling seamless data exchange between producers and consumers.
Introduction Today, data systems evolve quickly, demanding efficient monitoring and response. Real-time change detection is essential to keeping systems stable, preventing failures, and ensuring business continuity. Microsoft’s open-source tool, Drasi, addresses this need by effortlessly detecting, monitoring, and responding to data changes across platforms, including relational and graph databases.
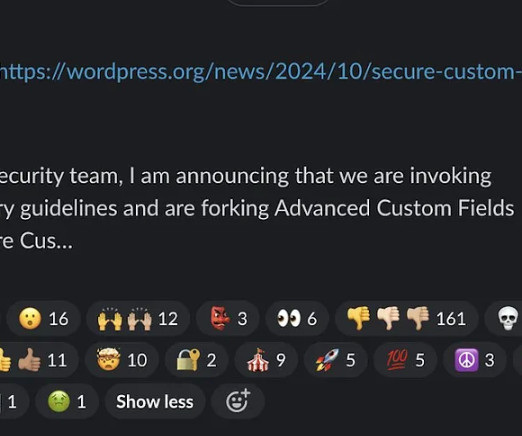
Automattic, creator of Wordpress, is being sued by one of the largest WordPress hosting providers. The conflict fits into a trend of billion-dollar companies struggling to effectively monetize open source, and are changing tactics to limit their competition and increase their revenue. This article was originally published a week ago, on 3 October 2024, in The Pragmatic Engineer.
Automattic, creator of Wordpress, is being sued by one of the largest WordPress hosting providers. The conflict fits into a trend of billion-dollar companies struggling to effectively monetize open source, and are changing tactics to limit their competition and increase their revenue. This article was originally published a week ago, on 3 October 2024, in The Pragmatic Engineer.
Where can you find projects dealing with advanced ML topics? GitHub is a perfect source with its many repositories. I’ve selected ten to talk about in this article.
Astasia Myers: The three components of the unstructured data stack LLMs and vector databases significantly improved the ability to process and understand unstructured data. I never thought of PDF as a self-contained document database, but that seems a reality that we can’t deny. The blog is an excellent summary of the existing unstructured data landscape.
The rise of AI and GenAI has brought about the rise of new questions in the data ecosystem – and new roles. One job that has become increasingly popular across enterprise data teams is the role of the AI data engineer. Demand for AI data engineers has grown rapidly in data-driven organizations. But what does an AI data engineer do? What are they responsible for?
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. Data transformation is key for data-driven decision-making, allowing organizations to derive meaningful insights from varied data sources.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the data lake.
Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one section from this week’s from last week’s The Pulse issue. To get full issues twice a week, subscribe here.
Each project, from beginner tasks like Image Classification to advanced ones like Anomaly Detection, includes a link to the dataset and source code for easy access and implementation.
There are some things you don’t need until you need them. I ran into that situation recently with needing to process some CSV / Flatfiles on short notice. At first, it appeared to be easy, but then I realized, as usual, there was a little monkey wrench thrown into the middle of it. It is […] The post Skip Lines of CSV files with DuckDB and Polars appeared first on Confessions of a Data Guy.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
When Robinhood was founded, we set out to build a platform that gives everyone access to the financial markets. Over the last decade, we’ve disrupted and changed the industry for the better, becoming the first U.S. retail broker to offer commission-free trading, and saving investors billions in the process. In recent years, we’ve expanded our offering, ushering in a number of new cutting-edge products and services that help everyone – regardless of income – trade, invest, and earn.
The Yelp Reservations service (yelp_res) is the service that powers reservations on Yelp. It was acquired along with Seatme in 2013, and is a Django service and webapp. It powers the reservation backend and logic for Yelp Guest Manager, our iPad app for restaurants, and handles diner and partner flows that create reservations. Along with that, it serves a web UI and backend API for our Yelp Reservations app, which has been superseded by Yelp Guest Manager but is still used by many of our restaur
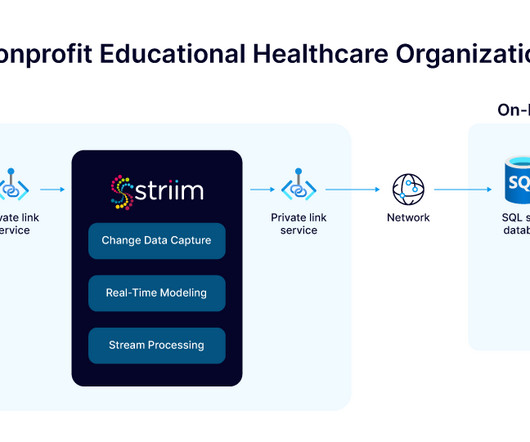
A nonprofit educational healthcare organization is faced with the challenge of modernizing its critical systems while ensuring uninterrupted access to essential services. With Striim’s real-time data integration solution, the institution successfully transitioned to a cloud infrastructure, maintaining seamless operations and paving the way for future advancements.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Introduction Setup SQL tips 1. Handy functions for common data processing scenarios 1.1. Need to filter on WINDOW function without CTE/Subquery use QUALIFY 1.2. Need the first/last row in a partition, use DISTINCT ON 1.3. STRUCT data types are sorted based on their keys from left to right 1.4. Get the first/last element with ROW_NUMBER() + QUALIFY 1.5.
Data stacks have come a long way, evolving from monolithic, one-fits-all systems like Oracle/SAP to today’s modular open data stacks. This begs the question, what’s next? Or why is the current not meeting our needs? As we see more analytics engineering and software best practices, embracing codeful, Git-based, and more CLI-based workflows, the future looks more code-first.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
I.f you work in data, then at some point in your career, you’ll likely need to parse data from a PDF. You might need to parse thousands of PDFs in order to pull out invoice information. Or maybe you need to parse financial filing documents such as 10-Ks. This can seem challenging at first. Afterall,… Read more The post How To Automate PDF Data Extraction – 3 Different Methods To Parse PDFs For Analytics appeared first on Seattle Data Guy.
“That should take two hours, not two months. Can’t your Data & Analytics Team go any faster?” “The executives’ dashboard broke! The data’s wrong! Can I ever trust our data?” If you’ve ever heard (or had) these complaints about speed-to-insight or data reliability, you should watch our webinar, DataOps for Beginners, on demand. DataKitchen’s VP Gil Benghiat breaks down what DataOps is (spoiler: it’s not just DevOps for data) and how DataOps can take your Data & Analytics factory fro
1. Introduction 2. Code & Data 3. Using nested data types effectively 3.1. Use STRUCT for one-to-one & hierarchical relationships 3.2. Use ARRAY[STRUCT] for one-to-many relationships 3.3. Using nested data types in data processing 3.3.1. STRUCT enables more straightforward data schema and data access 3.3.2. Nested data types can be sorted 3.3.3.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
DuckDB has a significant share and is frequently featured in the latest data engineering news. However, it’s still in its early adopter phase and has yet to be adopted by larger enterprises. Sure, all data creators and startups have used and potentially grown to love DuckDB, but is it also suitable for enterprises? What about scaling out and sharing it with others in the organization?
At Meta, React and React Native are more than just tools; they are integral to our product development and innovation. With over five thousand people at Meta building products and experiences with React every month, these technologies are fundamental to our engineering culture and our ability to quickly build and ship high quality products. In this post, we will dive into the development experiences of some of the product teams who leveraged React and React Native to deliver exciting projects sh
“As he lay awake in his Bay Area apartment, the data leader couldn’t shake the feeling that something wasn’t right. He tried to shut his eyes—to force them closed—but the more the data engineer tried, the more convinced he became. Suddenly, a light appeared from the darkness. It was a Slack from the CEO. She was working late. And the data…it couldn’t be…it looked wrong.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content