This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There are plenty of statistics about the speed at which we are creating data in today’s modern world. On the flip side of all that data creation is a need to manage all of that data and thats where data teams come in. But leading these data teams is challenging and yet many new data… Read more The post From IC to Data Leader: Key Strategies for Managing and Growing Data Teams appeared first on Seattle Data Guy.
According to industry experts, 2024 was destined to be a banner year for generative AI. Operational use cases were rising to the surface, technology was reducing barriers to entry, and general artificial intelligence was obviously right around the corner. So… did any of that happen? Well, sort of. Here at the end of 2024, some of those predictions have come out piping hot.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction. This counting service, built on top of the TimeSeries Abstraction, enables distributed counting at scale while maintaining similar low latency performance.
For years, companies have operated under the prevailing notion that AI is reserved only for the corporate giants — the ones with the resources to make it work for them. But as technology speeds forward, organizations of all sizes are realizing that generative AI isn’t just aspirational: It’s accessible and applicable now. With Snowflake’s easy-to-use, unified AI and data platform, businesses are removing the manual drudgery, bottlenecks and error-prone labor that stymie productivity, and are usi
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
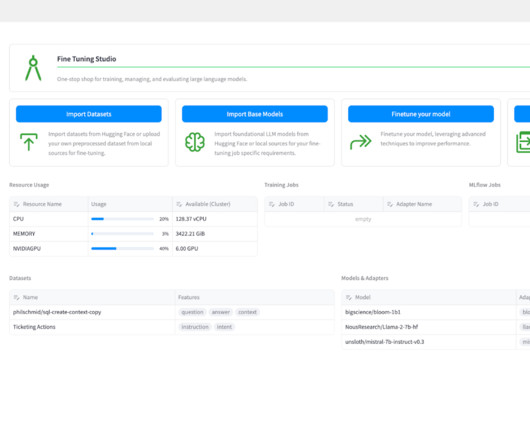
Large Language Models (LLMs) will be at the core of many groundbreaking AI solutions for enterprise organizations. Here are just a few examples of the benefits of using LLMs in the enterprise for both internal and external use cases: Optimize Costs. LLMs deployed as customer-facing chatbots can respond to frequently asked questions and simple queries.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold.
Scraping data from PDFs is a right of passage if you work in data. Someone somewhere always needs help getting invoices parsed, contracts read through, or dozens of other use cases. Most of us will turn to Python and our trusty list of Python libraries and start plugging away. Of course, there are many challenges… Read more The post Challenges You Will Face When Parsing PDFs With Python – How To Parse PDFs With Python appeared first on Seattle Data Guy.
Scraping data from PDFs is a right of passage if you work in data. Someone somewhere always needs help getting invoices parsed, contracts read through, or dozens of other use cases. Most of us will turn to Python and our trusty list of Python libraries and start plugging away. Of course, there are many challenges… Read more The post Challenges You Will Face When Parsing PDFs With Python – How To Parse PDFs With Python appeared first on Seattle Data Guy.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights. Before building your own data architecture from scratch though, why not steal – er, learn from – what industry leaders have already figured out?
Scrum is a quality-driven process for producing excellent business outcomes. Organizations are looking for professional product owners that grasp this notion and can use it in the real world. Employers use many credentialing services to certify levels of comprehension and application by level, which are referred to as belts. Scrum training sessions, along with resources like a PSPO study guide, assist you in learning PSPO I principles, studying efficiently and effectively to pass your exam, adva
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. For organizations considering moving from a legacy data warehouse to Snowflake, looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or assessing new options if your current cloud data warehouse just isn’t scaling anymore, it helps to see how others have done it.
We are excited to announce the acquisition of Octopai , a leading data lineage and catalog platform that provides data discovery and governance for enterprises to enhance their data-driven decision making. Cloudera’s mission since its inception has been to empower organizations to transform all their data to deliver trusted, valuable, and predictive insights.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Key Takeaways: Data integrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Data quality and data governance are the top data integrity challenges, and priorities. A long-term approach to your data strategy is key to success as business environments and technologies continue to evolve. The rapid pace of technological change has made data-driven initiatives more crucial than ever within modern business strategies.
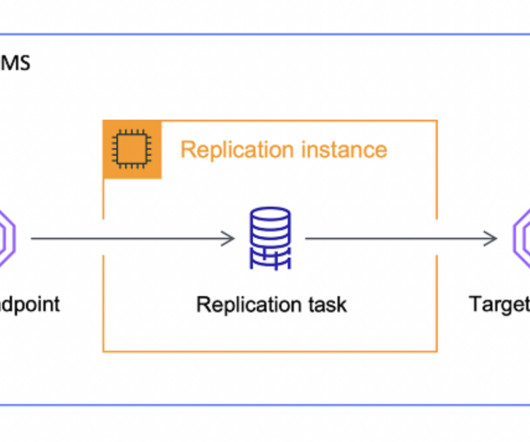
Recently, I’ve encountered a few projects that used AWS DMS, which is almost like an ELT solution. Whether it was moving data from a local database instance to S3 or some other data storage layer. It was interesting to see AWS DMS used in this manner. But it’s not what DMS was built for. As… Read more The post What Is AWS DMS And Why You Shouldn’t Use It As An ELT appeared first on Seattle Data Guy.
In my never-ending quest to plumb the most boring depths of every single data tool on the market, I found myself annoyed when recently using DuckDB for a benchmark that was reading parquet files from s3. What was not clear, or easy, was trying to figure out how DuckDB would LIKE to read default AWS […] The post DuckDB … reading from s3 … with AWS Credentials and more. appeared first on Confessions of a Data Guy.
BI-as-Code and the New Era of GenBI Imagine creating business dashboards by simply describing what you want to see. No more clicking through complex interfaces or writing SQL queries - just have a conversation with AI about your data needs. This is the promise of Generative Business Intelligence (GenBI). At its core, GenBI delivers an unreasonably effective human interface , where we iterate quickly, based on BI-as-Code.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These new tools streamline workflows, deliver insights at scale, and get AI apps into production quickly. Customers such as Skai have used these capabilities to bring their generative AI solution into production in just two days instead of months.
How we use a shared Spark server to make our Spark infrastructure more efficient Image by Kanenori from Pixabay Spark Connect is a relatively new component in the Spark ecosystem that allows thin clients to run Spark applications on a remote Spark cluster. This technology can offer some benefits to Spark applications that use the DataFrame API. Spark has long allowed to run SQL queries on a remote Thrift JDBC server.
We are excited to share our latest research paper Retrieve, Annotate, Evaluate, Repeat — Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation. We introduce a novel approach to large-scale product retrieval evaluation using Multimodal Large Language Models (MLLMs). Evaluated on 20,000 examples, our method shows how MLLMs can help automate the relevance assessment of retrieved products, achieving levels of accuracy comparable to human annotators and enabling scalable evaluation
Much of the data we have used for analysis in traditional enterprises has been structured data. It’s easy for humans to break down, understand, and, in turn, find insights from it. However, much of the data that is being created and will be created comes in some form of unstructured format. However, the digital era… Read more The post What is Unstructured Data?
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Editor’s Note: Launching Data & Gen-AI courses in 2025 I can’t believe DEW will reach almost its 200th edition soon. What I started as a fun hobby has become one of the top-rated newsletters in the data engineering industry. All credit goes to the incredible data engineering community, where people are constantly writing and sharing their knowledge with the community.
Key Takeaways: Harness automation and data integrity unlock the full potential of your data, powering sustainable digital transformation and growth. Data and processes are deeply interconnected. Successful digital transformation requires you to optimize both so that they work together seamlessly. Simplify complex SAP® processes with automation solutions that drive efficiency, reduce costs, and empower your teams to act quickly.
Today’s business landscape is increasingly competitive — and the right data platform can be the difference between teams that feel empowered or impaired. I love talking with leaders across industries and organizations to hear about what’s top of mind for them as they evaluate various data platforms. In these conversations, there are a number of questions that I hear time and time again: Will my data platform be scalable and reliable enough?
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. But when data processes fail to match the increased demand for insights, organizations face bottlenecks and missed opportunities.
The telecommunication industry is transforming greatly in this modern time and age because of changes in the digital revolution. The scope of telecom services is growing in size and complexity, owing to technologies such as 5G, the Internet of Things (IoT), and cloud technology. And one technology that has potential to transform the telecom sector is Generative AI , or GAI, which lies in the focus of creating new things, be it content, ideas or solutions.
Key Takeaways: Data used for personalization must be of high quality—accurate, up-to-date, and free of redundancies. 4 Practical Tips for Implementing Data-Driven Personalization in your organization. Many organizations struggle with siloed communication channels, which create fragmented customer experiences. How do you convert the everyday customers into loyal brand enthusiasts?
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
You’ve heard about Snowflake’s new capabilities, our fresh products and innovations that help bring AI and apps to life. Now, it’s time to BUILD. Join us for BUILD 2024, a three-day global virtual conference taking place Nov. 12-15, to hear major Snowflake product announcements firsthand and to learn how to build with our latest innovations through dozens of technical sessions and hands-on labs.
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. The author narrates that multiple agents working together achieve better results than one.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. Any delays in metadata retrieval can negatively impact user experience, resulting in decreased productivity and satisfaction.
Large Vision Models (LVMs) have transformed the field of computer vision, setting new benchmarks in image recognition, image segmentation, and object detection. Historically, convolutional neural networks (CNNs) have dominated computer vision tasks. However, with the introduction of the Transformer architecture—initially successful in Natural Language Processing (NLP)—the landscape has shifted.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content