This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The below article was originally published in The Pragmatic Engineer , on 29 February 2024. I am re-publishing it 6 months later as a free-to-read article. This is because the below case is a good example on hype versus reality with GenAI. To get timely analysis like this in your inbox, subscribe to The Pragmatic Engineer. Klarna launched its AI chatbot, built in collaboration with OpenAI, which the company wants to use to eliminate 2/3rds of customer support positions.
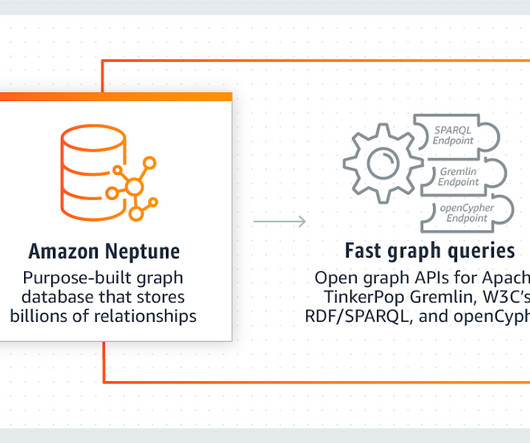
Introduction Managing complicated, interrelated information is more important than ever in today’s data-driven society. Traditional databases, while still valuable, often falter when it comes to handling highly connected data. Enter the unsung heroes of the data world: graph databases. These powerful tools are designed to manage and query intricate data relationships effortlessly.
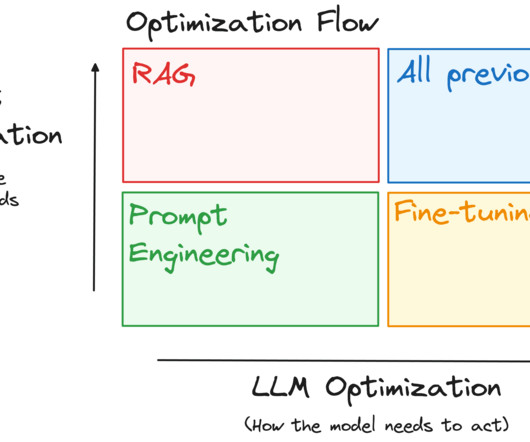
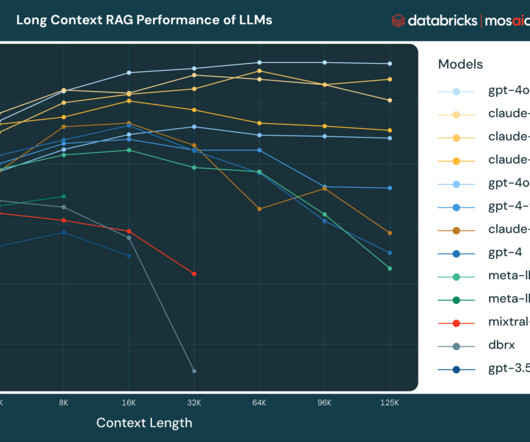
Optimize LLM performance and scalability using techniques like prompt engineering, retrieval augmentation, fine-tuning, model pruning, quantization, distillation, load balancing, sharding, and caching.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
I still remember the good ole days when Apache Spark was fresh and hot, hardly anyone was using it, except a few poor AWS Glue and EMR users … Lord have mercy on their ragged souls. It’s funny how that GOAT of a tool went from being used by a few companies for extremely large […] The post Apache Spark’s Most Annoying Use Case appeared first on Confessions of a Data Guy.
In the spring of 2024, I ran a new survey to gather more data for my Data Teams book and update my 2023 and 2020 surveys. In total, we had 81 respondents. This survey was designed to get information about how management uses data teams, the value they’re creating, and how they’re creating it. The survey asked about the best and worst practices that teams are using or experiencing.
Introduction Apache Airflow is a crucial component in data orchestration and is known for its capability to handle intricate workflows and automate data pipelines. Many organizations have chosen it due to its flexibility and strong scheduling capabilities. Yet, as data requirements change, Airflow’s lack of scalability, real-time processing capabilities, and setup complexity may lead to […] The post Airflow Alternatives for Data Orchestration appeared first on Analytics Vidhya.
I (Gergely) sometimes get reachouts to do talks at events in Amsterdam (where I am based,) the Netherlands, or somewhere in Europe. Unfortunately, rarely do talks – I do one conference per year. However, I asked around in the community about tech professionals who do paid talks that software engineers find interesting, engaging, and educational.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
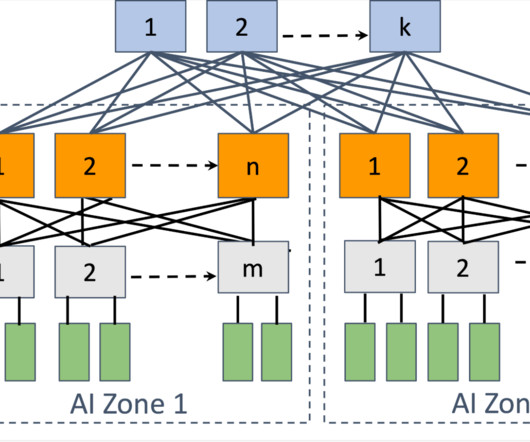
AI networks play an important role in interconnecting tens of thousands of GPUs together, forming the foundational infrastructure for training, enabling large models with hundreds of billions of parameters such as LLAMA 3.1 405B. This week at ACM SIGCOMM 2024 in Sydney, Australia, we are sharing details on the network we have built at Meta over the past few years to support our large-scale distributed AI training workload.
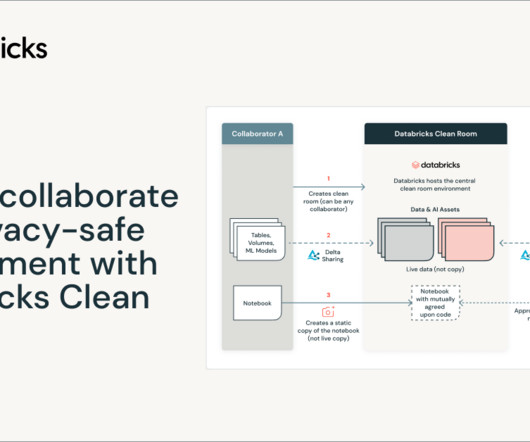
Fueled by the exponential growth in external data and AI for innovation, organizations across all industries are looking for effective ways to collaborate.
Code organization and assertions flow are both important but even them, they can't guarantee your colleagues' adherence to the unit tests. There are other user-facing attributes to consider as well.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
The AI and ML complexity results in a growing number and diversity of jobs that require AI & ML expertise. We’ll give you a rundown of these jobs regarding the technical skills they need and the tools they employ.
I (Gergely) sometimes get reachouts to do talks at events in Amsterdam (where I am based,) the Netherlands, or somewhere in Europe. Unfortunately, rarely do talks – I do one conference per year. However, I asked around in the community about tech professionals who do paid talks that software engineers find interesting, engaging, and educational.
If you work in data, then AI is everywhere at this point. But whether AI is hype or reality doesn’t change the fact that data engineers will play a major role in ensuring that the data sets that are utilized for the growing use cases are usable both by machines and humans. Whether that data… Read more The post Essential Skills for Data Engineers in the Age of AI appeared first on Seattle Data Guy.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Testing batch jobs is not the same as testing streaming ones. Although the transformation (the WHAT from the previous article) is similar in both cases, more complete validation tests on the job logic are not. After all, streaming jobs often iteratively build the final outcome while the batch ones generate it in a single pass.
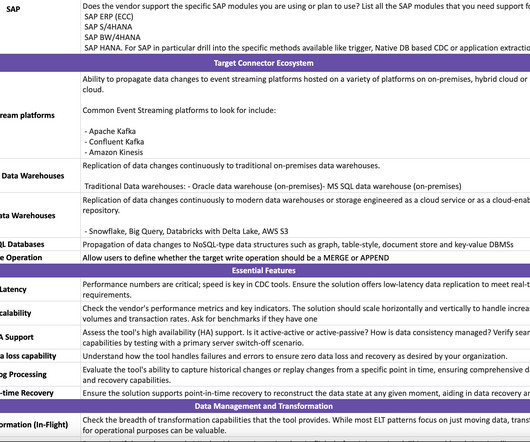
TL;DR Aswin and I are thrilled to announce the release of the first version of our comprehensive guide for evaluating Change Data Capture. CDC Evaluation Guide Google Sheet Link: [link] CDC Evaluation Guide Github Link: [link] Change Data Capture (CDC) is a powerful technology in data engineering that allows for continuously capturing changes (inserts, updates, and deletes) made to source systems.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
What would you do if you became the head or director of data for a 1,000-person company? Yesterday, you were plugging along as an analyst, and now, suddenly, you have all these new responsibilities. Figuring out where to start is part of the job. You’d probably feel a strong temptation to freak out. Who wouldn’t?… Read more The post How To Run A Data Team As A New Head Of Data appeared first on Seattle Data Guy.
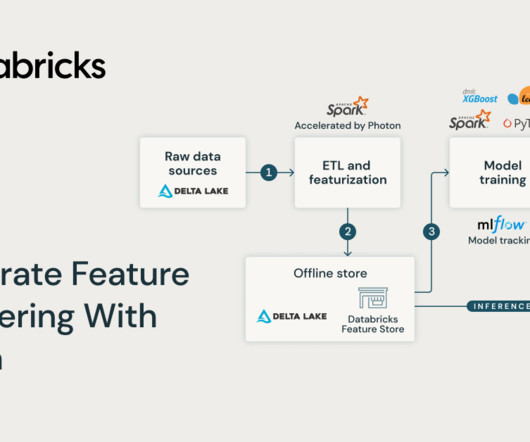
Training a high-quality machine learning model requires careful data and feature preparation. To fully utilize raw data stored as tables in Databricks, running.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
At Meta, we’ve been diligently working to incorporate privacy into different systems of our software stack over the past few years. Today, we’re excited to share some cutting-edge technologies that are part of our Privacy Aware Infrastructure (PAI) initiative. These innovations mark a major milestone in our ongoing commitment to honoring user privacy.
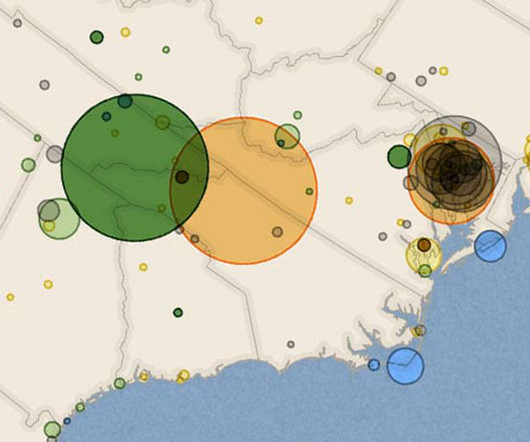
Welcome to Snowflake’s Startup Spotlight, where we learn about companies building their businesses on Snowflake. In this edition, we talk to Brent Lane, Co-founder and CEO of BigGeo, about the world of geospatial data and learn how BigGeo is turning 15 years of research into advanced technology that knocks down traditional barriers to using rich, complex location-based data throughout an organization.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content