This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We examine the growth of coronavirus daily cases in most affected countries, and show evidence that social distancing works in reducing the rate of spread. We also analyze KDnuggets Poll results - the scale of change to online and how Data Science work is likely to increase or drop in different regions. Stay Healthy and practice social distancing!
The performance of Uber’s services relies on our ability to quickly and stably launch new features on our platform , regardless of where the corresponding service lives in our tech stack. Foundational to our platform’s power is its microservice-based architecture … The post Why We Leverage Multi-tenancy in Uber’s Microservice Architecture appeared first on Uber Engineering Blog.
Advanced analytics and AI can significantly accelerate data processing required to get the insights, answers and recommendations to handle and address the COVID-19 pandemic.
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. Our wider Studio Engineering Organization has built more than 30 apps that help content progress from pitch (aka screenplay) to playback: ranging from script content acquisition, deal negotiations and vendor management to scheduling, streamlining production workflows, and so on.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
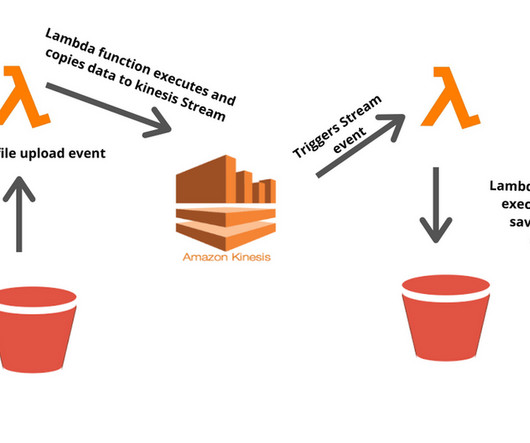
I built a serverless architecture for my simulated credit card complaints stream using, AWS S3 AWS Lambda AWS Kinesis the above picture gives a high-level view of the data flow. I assume uploading the CSV file as a data producer, so once you upload a file, it generates object created event and the Lambda function is invoked asynchronously. The file data content will be written to the Kinesis stream as a record (record = data + partition key), which triggers another Lambda function and persist th
One of the most common use cases for Apache Airflow is to run scheduled SQL scripts. Developers who start with Airflow often ask the following questions “How to use airflow to orchestrate sql?
Many cloud providers, and other third-party services, see the value of a Jupyter notebook environment which is why many companies now offer cloud hosted notebooks that are hosted on the cloud. Let's have a look at 3 such environments.
Many cloud providers, and other third-party services, see the value of a Jupyter notebook environment which is why many companies now offer cloud hosted notebooks that are hosted on the cloud. Let's have a look at 3 such environments.
The Elasticsearch sink connector helps you integrate Apache Kafka® and Elasticsearch with minimum effort. You can take data you’ve stored in Kafka and stream it into Elasticsearch to then be […].
With the lack of available tests & uncertainty around the true number of COVID-19 cases, Teradata Epidemiologist Daniel Ulatowski & Data Scientist Jack McCush hypothesize how symptomatic data & the Vantage ML Engine can be utilized to predict cases.
Summary Building and maintaining a system that integrates and analyzes all of the data for your organization is a complex endeavor. Operating on a shoe-string budget makes it even more challenging. In this episode Tyler Colby shares his experiences working as a data professional in the non-profit sector. From managing Salesforce data models to wrangling a multitude of data sources and compliance challenges, he describes the biggest challenges that he is facing.
I am taking you through my recent experience to find a dataset for my project. Industry Search To work with data, I need to narrow down the industry like health care, finance, insurance or other. I defined a few sources in my earlier blog post, which will give a sneak peek of techniques to extract industries. For Instance, most of the job listings introduce their job description as, One of the top insurance client looking for Data Engineer which exposes the industry.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
This article gives you an overview of the 10 key skills you need to become a better data engineer. If you are struggling to get started on what to learn, start with the first topic and proceed through the list.
Single-cluster deployments of Apache Kafka® are rare. Most medium to large deployments employ more than one Kafka cluster, and even the smallest use cases include development, testing, and production clusters. […].
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Summary There are a number of platforms available for object storage, including self-managed open source projects. But what goes on behind the scenes of the companies that run these systems at scale so you don’t have to? In this episode Will Smith shares the journey that he and his team at Linode recently completed to bring a fast and reliable S3 compatible object storage to production for your benefit.
With the COVID-19 epidemic in full swing, the countries that are faring the best are employing large-scale testing and electronic surveillance. But what does this mean for our civil liberties?
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
As enterprises move more and more of their applications to the cloud, they are also moving their on-prem ETL (extract, transform, load) pipelines to the cloud, as well as building […].
By Kevin Glisson, Marc Vilanova, Forest Monsen Netflix is pleased to announce the open-source release of our crisis management orchestration framework: Dispatch! Okay, but what is Dispatch? Put simply, Dispatch is: All of the ad-hoc things you’re doing to manage incidents today, done for you, and a bunch of other things you should’ve been doing, but have not had the time!
Summary CouchDB is a distributed document database built for scale and ease of operation. With a built-in synchronization protocol and a HTTP interface it has become popular as a backend for web and mobile applications. Created 15 years ago, it has accrued some technical debt which is being addressed with a refactored architecture based on FoundationDB.
Check out this curated reading list of books on customer experience. From updated classics to new research and insights into how large enterprises can drive business outcomes from a CX initiative.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Upgrading your machine learning, AI, and Data Science skills requires practice. To practice, you need to develop models with a large amount of data. Finding good datasets to work with can be challenging, so this article discusses more than 20 great datasets along with machine learning project ideas for you to tackle today.
In the Apache Kafka® ecosystem, ksqlDB and Kafka Streams are two popular tools for building event streaming applications that are tightly integrated with Apache Kafka. While ksqlDB and Kafka Streams […].
Netflix has a program in our Information Security department for quantifying the risk of deliberate (attacker-driven) and accidental… Continue reading on Netflix TechBlog ».
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Summary Data governance is a complex endeavor, but scaling it to meet the needs of a complex or globally distributed organization requires a well considered and coherent strategy. In this episode Tim Ward describes an architecture that he has used successfully with multiple organizations to scale compliance. By treating it as a graph problem, where each hub in the network has localized control with inheritance of higher level controls it reduces overhead and provides greater flexibility.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content