This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1. Introduction 2. Run Data Pipelines 2.1. Run on codespaces 2.2. Run locally 3. Projects 3.1. Projects from least to most complex 3.2. Batch pipelines 3.3. Stream pipelines 3.4. Event-driven pipelines 3.5. LLM RAG pipelines 4. Conclusion 1. Introduction Whether you are new to data engineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up!
After 10 years of Data Engineering work, I think it’s time to hang up the proverbial hat and ride off into the sunset, never to be seen again. I wish. Everything has changed in 10 years, yet nothing has changed in 10 years, how is that even possible? Sometimes I wonder if I’ve learned anything […] The post What I’ve Learned After A Decade Of Data Engineering appeared first on Confessions of a Data Guy.
Summary Data lakehouse architectures have been gaining significant adoption. To accelerate adoption in the enterprise Microsoft has created the Fabric platform, based on their OneLake architecture. In this episode Dipti Borkar shares her experiences working on the product team at Fabric and explains the various use cases for the Fabric service. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
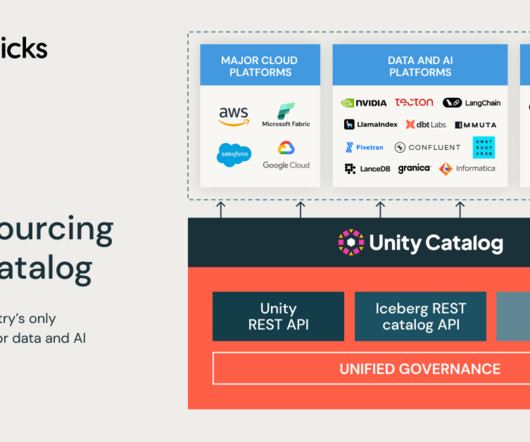
Welcome to the snow world ( credits ) Every year, the competition between Snowflake and Databricks intensifies, using their annual conferences as a platform for demonstrating their power. This year, the Snowflake Summit was held in San Francisco from June 2 to 5, while the Databricks Data+AI Summit took place 5 days later, from June 10 to 13, also in San Francisco.
This video covers the latest announcements from StreamNative, Confluent, and WarpStream. We discuss communication protocols, how they’re used, and what they mean for you. We also discuss the various systems using Kafka’s protocol. Finally, we discuss the announcements about writing to Iceberg and DeltaLake directly from the broker and what that means for costs and operational ease.
1. Introduction 2. Features crucial to building and maintaining data pipelines 2.1. Schedulers to run data pipelines at specified frequency 2.2. Orchestrators to define the order of execution of your pipeline tasks 2.2.1. Define the order of execution of pipeline tasks with a DAG 2.2.2. Define where to run your code 2.2.3. Use operators to connect to popular services 2.3.
1. Introduction 2. Features crucial to building and maintaining data pipelines 2.1. Schedulers to run data pipelines at specified frequency 2.2. Orchestrators to define the order of execution of your pipeline tasks 2.2.1. Define the order of execution of pipeline tasks with a DAG 2.2.2. Define where to run your code 2.2.3. Use operators to connect to popular services 2.3.
Summary This episode features an insightful conversation with Petr Janda, the CEO and founder of Synq. Petr shares his journey from being an engineer to founding Synq, emphasizing the importance of treating data systems with the same rigor as engineering systems. He discusses the challenges and solutions in data reliability, including the need for transparency and ownership in data systems.
I’m excited to share that OpenAI has completed the acquisition of Rockset. We are thrilled to join the OpenAI team and bring our technology and expertise to building safe and beneficial AGI. From the start, our vision at Rockset was to fundamentally transform the way data-driven applications were built. We developed our search and analytics database, taking full advantage of the cloud, to eliminate the complexity inherent in the data infrastructure needed for these apps.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Open source file and table formats have garnered much interest in the data industry because of their potential for interoperability — unlocking the ability for many technologies to safely operate over a single copy of data. Greater interoperability not only reduces the complexity and costs associated with using many tools and processing engines in parallel, but it would also reduce potential risks associated with vendor lock-in.
This acquisition will bring Bitstamp’s globally-scaled crypto exchange to Robinhood, with retail and institutional customers across the EU, UK, US and Asia. This strategic combination better positions Robinhood to expand outside of the US and will bring a trusted and reputable institutional business to Robinhood. Expected to close in the first half of 2025, subject to customary closing conditions, including regulatory approvals.
Over the last year, we have seen a surge of commercial and open-source foundation models showing strong reasoning abilities on general knowledge tasks.
Summary Stripe is a company that relies on data to power their products and business. To support that functionality they have invested in Trino and Iceberg for their analytical workloads. In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
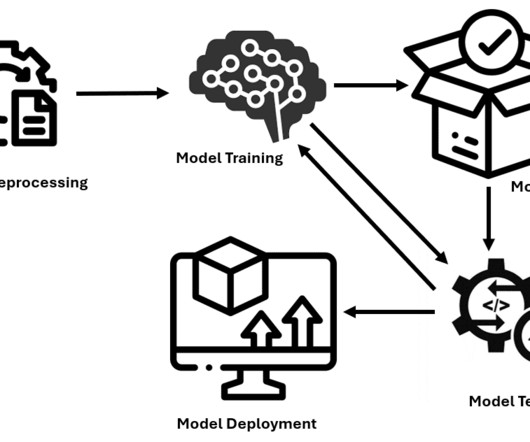
Image by author Model deployment is the process of trained models being integrated into practical applications. This includes defining the necessary environment, specifying how input data is introduced into the model and the output produced, and the capacity to analyze new data and provide relevant predictions or categorizations.
As we continue to focus our AI research and development on solving increasingly complex problems, one of the most significant and challenging shifts we’ve experienced is the sheer scale of computation required to train large language models (LLMs). Traditionally, our AI model training has involved a training massive number of models that required a comparatively smaller number of GPUs.
Last May I gave a talk about stream processing fallacies at Infoshare in Gdansk. Besides this speaking experience, I was also - and maybe among others - an attendee who enjoyed several talks in software and data engineering areas. I'm writing this blog post to remember them and why not, share the knowledge with you!
Nothing will raise the hackles on the backs of hairy and pale programmers who’ve been stuck in their mom’s basement for a decade like bringing up OOP (Object Oriented Programming), especially in the context of Python. It’s like two fattened calves prepared for slaughter, sharpen your knives, and take your place, it’s time to feast […] The post Is Python OOP the Devil?
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Summary Streaming data processing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. To address this shortcoming Datorios created an observability platform for Flink that brings visibility to the internals of this popular stream processing system. In this episode Ronen Korman and Stav Elkayam discuss how the increased understanding provided by purpose built observability improves the usefulness
Meta is currently operating many data centers with GPU training clusters across the world. Our data centers are the backbone of our operations, meticulously designed to support the scaling demands of compute and storage. A year ago, however, as the industry reached a critical inflection point due to the rise of artificial intelligence (AI), we recognized that to lead in the generative AI space we’d need to transform our fleet.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
One of the big challenges in streaming Delta Lake is the inability to handle in-place changes, like updates, deletes, or merges. There is good news, though. With a little bit of effort on your data provider's side, you can process a Delta Lake table as you would process Apache Kafka topics, hence without in-place changes.
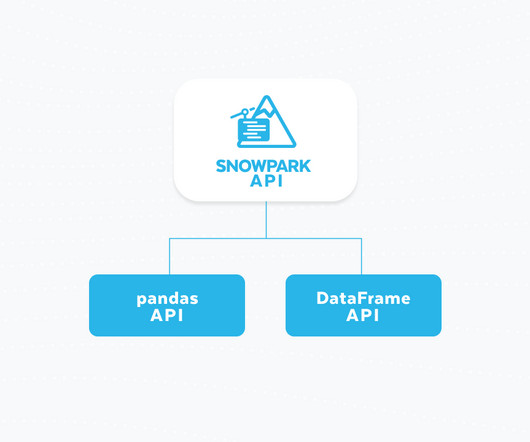
Python’s popularity has grown significantly, quickly becoming the preferred language for development across machine learning, application development, pipelines and more. At Snowflake we are deeply committed to delivering a best-in-class platform for Python developers. In line with this commitment, we’re thrilled to announce the public preview support of Snowpark pandas API, enabling seamless execution of distributed pandas at scale in Snowflake.
Summary Modern businesses aspire to be data driven, and technologists enjoy working through the challenge of building data systems to support that goal. Data governance is the binding force between these two parts of the organization. Nicola Askham found her way into data governance by accident, and stayed because of the benefit that she was able to provide by serving as a bridge between the technology and business.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Each year, we are humbled and honored to look back on the contributions from the Snowflake Partner Network (SPN) and recognize their hard work with the Snowflake Partner Awards. Our partners help drive customer success and build an ever-expanding open ecosystem of solutions built on the AI Data Cloud. In the midst of this year’s AI Data Cloud Summit , we announced the 2024 Snowflake Partner Awards, recognizing 36 partners that are winning together with Snowflake and honoring them for their conti
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content