This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Uber delivers efficient and reliable transportation across the global marketplace, which is powered by hundreds of services, machine learning models, and tens of thousands of datasets. While growing rapidly, we’re also committed to maintaining data quality, as it can greatly … The post How Uber Achieves Operational Excellence in the Data Quality Experience appeared first on Uber Engineering Blog.
To effectively use ksqlDB, the streaming database for Apache Kafka®, you should of course be familiar with its features and syntax. However, a deeper understanding of what goes on underneath […].
Humans have been trying to make machines chat for decades. Alan Turing considered computers’ ability to generate natural speech a proof of their ability to think. Today, we converse with virtual companions all the time. But despite years of research and innovation, their unnatural responses remind us that no, we’re not yet at the HAL 9000-level of speech sophistication.
1. Introduction 2. Understanding your data engineering task 2.1. Data infrastructure overview 2.2. What exactly 2.3. Why exactly 2.4. Current state 2.5. Downstream impact 3. Delivering your data engineering task 3.1. How 3.2. Breakdown into sub-tasks 3.3. Delivering the finished task 4. Conclusion 5. Further reading 1. Introduction Congratulations! You are given a quick overview of the business and data architecture and are assigned your very first data engineering task.
Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.
Summary All of the fancy data platform tools and shiny dashboards that you use are pointless if the consumers of your analysis don’t have trust in the answers. Stemma helps you establish and maintain that trust by giving visibility into who is using what data, annotating the reports with useful context, and understanding who is responsible for keeping it up to date.
Dear Parents and Educators and Friends of Cloudera, If you are reading this blog, you know us at Cloudera as a group of self-described data geeks and data analysts. We believe data drives better decisions and moves businesses forward and for us, that’s exciting. We are innovating and helping Fortune 500 transform and grow because they can make better data-driven decisions at the accelerated pace we live and work in today.
Today, as part of our expanded partnership with Elastic, we are announcing an update to the fully managed Elasticsearch Sink Connector in Confluent Cloud. This update allows you to take […].
Below is our fourth post (4 of 5) on combining data mesh with DataOps to foster innovation while addressing the challenges of a decentralized architecture. We’ve covered the basic ideas behind data mesh and some of the difficulties that must be managed. Below is a discussion of a data mesh implementation in the pharmaceutical space. For those embarking on the data mesh journey, it may be helpful to discuss a real-world example and the lessons learned from an actual data mesh implementation.
Introduction Patterns 1. Batch Data Pipelines 1.1 Process => Data Warehouse 1.2 Process => Cloud Storage => Data Warehouse 2. Near Real-Time Data pipelines 2.1 Data Stream => Consumer => Data Warehouse 2.2 Cloud Storage => process => Data Warehouse Conclusion Further Reading Introduction Loading data into a data warehouse is a key component of most data pipelines.
Summary Data lake architectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis. Vinoth Chandar helped to create the Hudi project while at Uber to address this challenge.
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
We just announced Cloudera DataFlow for the Public Cloud (CDF-PC), the first cloud-native runtime for Apache NiFi data flows. CDF-PC enables Apache NiFi users to run their existing data flows on a managed, auto-scaling platform with a streamlined way to deploy NiFi data flows and a central monitoring dashboard making it easier than ever before to operate NiFi data flows at scale in the public cloud.
It is often difficult enough to build one application that talks to a single middleware or backend layer; e.g., a whole team of frontend engineers may build a web application […].
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
By Benson Ma , Alok Ahuja Introduction At Netflix, hundreds of different device types, from streaming sticks to smart TVs, are tested every day through automation to ensure that new software releases continue to deliver the quality of the Netflix experience that our customers enjoy. In addition, Netflix continuously works with its partners (such as Roku, Samsung, LG, Amazon) to port the Netflix SDK to their new and upcoming devices (TVs, smart boxes, etc), to ensure the quality bar is reached be
Summary The reason that so much time and energy is spent on data integration is because of how our applications are designed. By making the software be the owner of the data that it generates, we have to go through the trouble of extracting the information to then be used elsewhere. The team at Cinchy are working to bring about a new paradigm of software architecture that puts the data as the central element.
Once upon an IT time, everything was a “point product,” a specific application designed to do a single job inside a desktop PC, server, storage array, network, or mobile device. Point solutions are still used every day in many enterprise systems, but as IT continues to evolve, the platform approach beats point solutions in almost every use case.
For both analysts and data scientists, identifying paths and patterns in data is a valuable way to gain insight into the occurrences leading to or from any event of interest. Read more.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
When companies need help with their vehicle fleets—including transport, storage, or renewing expired registrations—they don’t want to have to deal with multiple vehicle logistics providers. For these companies, ACERTUS provides […].
DataOps has become an essential methodology in pharmaceutical enterprise data organizations, especially for commercial operations. Companies that implement it well derive significant competitive advantage from their superior ability to manage and create value from data. They will be able to produce high-quality, on-demand insight that consistently leads to successful business decisions.
B2B sales strategies can be roughly divided into two activities: lead generation and lead conversion. It’s clear how each works. The former, attracting visitors to your website and then helping them take certain actions, is almost automated and works through carefully placed calls to action. The latter, supporting a lead to make the purchasing decision, is done by professional sales people with their arsenal of personalized tactics.
Summary The technological and social ecosystem of data engineering and data management has been reaching a stage of maturity recently. As part of this stage in our collective journey the focus has been shifting toward operation and automation of the infrastructure and workflows that power our analytical workloads. It is an encouraging sign for the industry, but it is still a complex and challenging undertaking.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Recently, I worked with a large fortune 500 customer on their migration from Apache Storm to Apache NiFi. If you’re asking yourself, “Isn’t Storm for complex event processing and NiFi for simple event processing?”, you’re correct. A few customers chose a complex event engine like Apache Storm for their simple event processing, even when Apache NiFi is the more practical choice, cutting drastically down on SDLC (software development lifecycle) time.
As Back to School promotions hit the shelves, Christmas & New Year offers are already locked in. Are these long-lead cycles still effective in today’s dynamic Retail & CPG environment?
The Confluent Q3 ‘21 release is here and packed full of new features that enable the world’s most innovative businesses to continue building what keeps them on top: real-time, mission-critical […].
A drug company tests 50,000 molecules and spends a billion dollars or more to find a single safe and effective medicine that addresses a substantial market. Figure 1 shows the 15-year cycle from screening to government agency approval and phase IV trials. Drug companies desperately look for ways to compress this lengthy time frame and to demonstrate the competitive advantage of their intellectual property.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Imagine you run a candy store. Some sweets are presented on your display cases for quick access while the rest is kept in the storeroom. Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a data warehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
Summary Data lakes have been gaining popularity alongside an increase in their sophistication and usability. Despite improvements in performance and data architecture they still require significant knowledge and experience to deploy and manage. In this episode Vikrant Dubey discusses his work on the Cuelake project which allows data analysts to build a lakehouse with SQL queries.
In our previous blog, we talked about the four paths to Cloudera Data Platform. . In-place Upgrade. Sidecar Migration. Rolling Sidecar Migration. Migrating to Cloud. If you haven’t read that yet, we invite you to take a moment and run through the scenarios in that blog. The four strategies will be relevant throughout the rest of this discussion. Today, we’ll discuss an example of how you might make this decision for a cluster using a “round of elimination” process based on our decision workflow.
As 5G puts data analytics at the heart of the next wave of sustainable growth, telcos must ensure their existing investments in data infrastructure can be leveraged to enable that growth.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















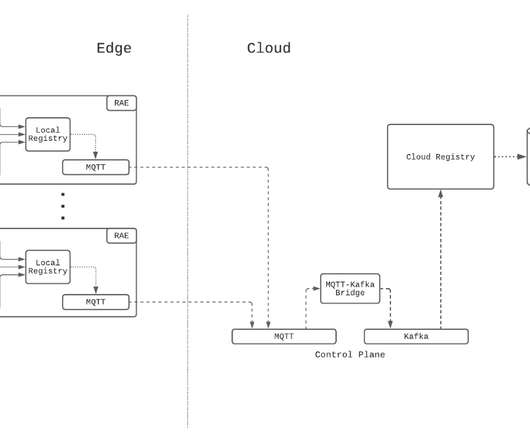
























Let's personalize your content