This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The sample data used for training has to be as close a representation of the real scenario as possible. There are many factors that can bias a sample from the beginning and those reasons differ from each domain (i.e. business, security, medical, education etc.).
As Uber Freight marked its second anniversary, we went back to the drawing board to redesign its app. The original carrier app was successful for owner-operators with one or two drivers, but it wasn’t optimized for larger fleets—feedback we … The post Building the New Uber Freight App as Lists of Modular, Reusable Components appeared first on Uber Engineering Blog.
Summary Data engineers are responsible for building tools and platforms to power the workflows of other members of the business. Each group of users has their own set of requirements for the way that they access and interact with those platforms depending on the insights they are trying to gather. Benn Stancil is the chief analyst at Mode Analytics and in this episode he explains the set of considerations and requirements that data analysts need in their tools and.
Baking Windows with Packer By Justin Phelps and Manuel Correa Customizing Windows images at Netflix was a manual, error-prone, and time consuming process. In this blog post, we describe how we improved the methodology, which technologies we leveraged, and how this has improved service deployment and consistency. Artisan Crafted Images In the Netflix full cycle DevOps culture the team responsible for building a service is also responsible for deploying, testing, infrastructure, and operation of t
Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.
Contrary to popular belief, in today's technology-enabled, digitally-disrupted world, it's the human element that matters the most in business. Read more!
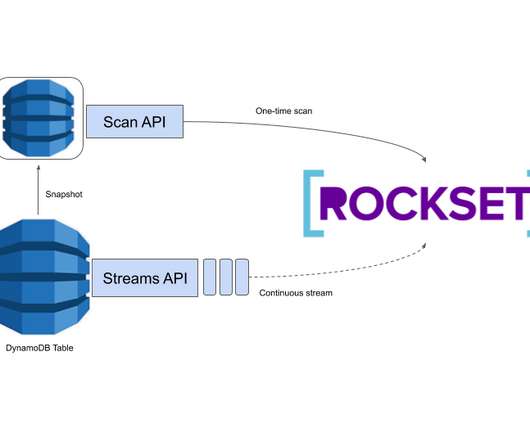
Many of our users implement operational reporting and analytics on DynamoDB using Rockset as a SQL intelligence layer to serve live dashboards and applications. As an engineering team, we are constantly searching for opportunities to improve their SQL-on-DynamoDB experience. For the past few weeks, we have been hard at work tuning the performance of our DynamoDB ingestion process.
Entirely implemented with NumPy, this extensive tutorial provides a detailed review of neural networks followed by guided code for creating one from scratch with computational graphs.
Entirely implemented with NumPy, this extensive tutorial provides a detailed review of neural networks followed by guided code for creating one from scratch with computational graphs.
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility? Once identified, … The post Less is More: Engineering Data Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog.
Summary Managing big data projects at scale is a perennial problem, with a wide variety of solutions that have evolved over the past 20 years. One of the early entrants that predates Hadoop and has since been open sourced is the HPCC (High Performance Computing Cluster) system. Designed as a fully integrated platform to meet the needs of enterprise grade analytics it provides a solution for the full lifecycle of data at massive scale.
An Android Multiple Backstack Bottom Navigation Library Pandora’s latest mobile redesign brings the bottom navigation pattern to our apps. Bottom navigation has become a popular design choice for many apps due to its many advantages including easy one-handed use and enhanced discoverability of top app destinations. When Pandora embarked on this project our designers had a clear vision of how navigation should work, a vision that in many ways is familiar to users of other popular apps like Instag
Find out how the early architectural decisions surrounding the Teradata Database are still making a critical contribution to performance today. Read more!
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
This post will walk you through the process of how to turn this awesome chat tool into a handy monitoring & alerting tool for your application. All this without any 3rd party modules and minimal code to keep the footprint small. Note: This post is using now outmoded integration method. Slack has introduced new ways to manage and send messages via Apps.
As a data scientist, you are in high demand. So, how can you increase your marketability even more? Check out these current trends in skills most desired by employers in 2019.
A common axiom among Uber engineers states that building new features is like fixing a car’s engine while driving it. As we scaled up to our present level of support for 14 million trips per day, the car in that … The post Migrating Functionality Between Large-scale Production Systems Seamlessly appeared first on Uber Engineering Blog.
Summary The extract and load pattern of data replication is the most commonly needed process in data engineering workflows. Because of the myriad sources and destinations that are available, it is also among the most difficult tasks that we encounter. Fivetran is a platform that does the hard work for you and replicates information from your source systems into whichever data warehouse you use.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
In this blog, we examine DynamoDB reporting and analytics, which can be challenging given the lack of SQL and the difficulty running analytical queries in DynamoDB. We will demonstrate how you can build an interactive dashboard with Tableau, using SQL on data from DynamoDB, in a series of easy steps, with no ETL involved. DynamoDB is a widely popular transactional primary data store.
How can a Digital CFO break down the silos in the Bank and support the digital agenda in transforming the customer journey? Read more from our experts!
We know that Apache Kafka ® is great when you’re dealing with streams, allowing you to conveniently look at streams as tables. Stream processing engines like KSQL furthermore give you the ability to manipulate all of this fluently. But what about when the relationships between items dominate your application? For example, in a social network, understanding the network means we need to look at the friend relationships between people.
Check out this list of NLP researchers, practitioners and innovators you should be following, including academics, practitioners, developers, entrepreneurs, and more.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
As Uber Freight marked its second anniversary, we went back to the drawing board to redesign its app. The original carrier app was successful for owner-operators with one or two drivers, but it wasn’t optimized for larger fleets—feedback we … The post Building the New Uber Freight App as Lists of Modular, Reusable Components appeared first on Uber Engineering Blog.
Summary Data is only valuable if you use it for something, and the first step is knowing that it is available. As organizations grow and data sources proliferate it becomes difficult to keep track of everything, particularly for analysts and data scientists who are not involved with the collection and management of that information. Lyft has build the Amundsen platform to address the problem of data discovery and in this episode Tao Feng and Mark Grover explain how it works, why they built it, a
Amazon DynamoDB is a managed NoSQL database in the AWS cloud that delivers a key piece of infrastructure for use cases ranging from mobile application back-ends to ad tech. DynamoDB is optimized for transactional applications that need to read and write individual keys but do not need joins or other RDBMS features. For this subset of requirements, DynamoDB offers a way to have a virtually infinitely scalable datastore that requires minimal maintenance.
What is the value of self-service analytics in your organization? What personas provide the most value & where should a business focus its resources? Read more.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
We’re excited to announce Tutorials for Apache Kafka ® , a new area of our website for learning event streaming. Kafka Tutorials is a collection of common event streaming use cases, with each tutorial featuring an example scenario and several complete code solutions. It’s the fastest way to learn how to use Kafka with confidence. We’re building this because we know that event streaming is a radically different way of thinking.
Graph Machine Learning uses the network structure of the underlying data to improve predictive outcomes. Learn how to use this modern machine learning method to solve challenges with connected data.
Visually-displayed data is much more accessible, and it’s criticalto promptly identify the weaknesses of an organization, accurately forecasttrading volumes and sale prices, or make the right business choices.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
With the pervasive important of NLP in so many of today's applications of deep learning, find out how advanced translation techniques can be further enhanced by transformers and attention mechanisms.
Kaggle Learn is "Faster Data Science Education," featuring micro-courses covering an array of data skills for immediate application. Courses may be made with newcomers in mind, but the platform and its content is proving useful as a review for more seasoned practitioners as well.
If you are diving into AI and machine learning, Andrew Ng's book is a great place to start. Learn about six important concepts covered to better understand how to use these tools from one of the field's best practitioners and teachers.
At times it may seem Machine Learning can be done these days without a sound statistical background but those people are not really understanding the different nuances. Code written to make it easier does not negate the need for an in-depth understanding of the problem.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content