This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I remember those days, oh so long ago, it seems like another lifetime. I haven’t used Pandas in many a year, decades, or whatever. We’ve all been there, done that. Pandas I mean. I would dare say it’s a rite of passage for most data folk. For those using Python, it’s probably one of the […] The post Replacing Pandas with Polars.
Introduction Big data is revolutionizing the healthcare industry and changing how we think about patient care. In this case, big data refers to the vast amounts of data generated by healthcare systems and patients, including electronic health records, claims data, and patient-generated data. With the ability to collect, manage, and analyze vast amounts of data, […] The post The Impact of Big Data on Healthcare Decision Making appeared first on Analytics Vidhya.
With all the recent data events I have put together I inevitably run into new data engineers who are either finishing up college or looking to transition into a data engineer or data scientist position. In fact I have talked to several newly graduated engineers who are struggling to find work. A few told me… Read more The post How To Hire Junior Data Engineers appeared first on Seattle Data Guy.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
I used VS Code, Sublime, Notepad++, TextMate, and others, but the shortcut with cmd(+shift)+end, jumping with option+arrow-keys from word to word, needed to be faster at some point. I was hitting my limits. Everything I was doing I did decently fast, but I didn’t get any faster. Vim is the only editor you get faster with time. Vim is based solely on shortcuts.
Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of Data Warehouses, Data Lakes, and Lake Houses … the merging of the old relational database functionality with TB and PB level cloud-based file storage systems. Tools like […] The post Simplify Delta Lake Complexity with mack. appeared first on Confessions of a Data Guy.
Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of Data Warehouses, Data Lakes, and Lake Houses … the merging of the old relational database functionality with TB and PB level cloud-based file storage systems. Tools like […] The post Simplify Delta Lake Complexity with mack. appeared first on Confessions of a Data Guy.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. We cover one and a half out of eight topics in today’s subscriber-only issue, Inside Pollen's Transparent Compensation Data. If you’re not yet a subscriber, you also missed this week’s deep-dive on Becoming a Fractional CTO. To get this newsletter every week, subscribe here.
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
2022 is coming to an end. What is the state of data infra? Are Snowflake and Databricks still fighting over total cost of ownership? Is everyone switching to DuckDB? Are data engineers all learning Rust? Let’s try to answer these questions. Our team is putting together an all day event focused on helping answer some… Read more The post What Is The State Of Data Engineering And Infrastructure In 2023 appeared first on Seattle Data Guy.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Rust has been on my mind a lot lately, probably because of Data Engineering boredom, watching Spark clusters chug along like some medieval farm worker endlessly trudging through the muck and mire of life. Maybe Rust has breathed some life back into my stagnant soul, reminding me there is a big world out there, […] The post Using Rust to write a Data Pipeline.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. We cover one out of five topics in today’s subscriber-only The Scoop issue. To get the full issues, twice a week: subscribe here. Update on 20 January: less than a day after publishing this article, Google announced historic layoffs that will impact ~12,000 positions.
Introduction In today’s world, machine learning and artificial intelligence are widely used in almost every sector to improve performance and results. But are they still useful without the data? The answer is No. The machine learning algorithms heavily rely on data that we feed to them. The quality of data we feed to the algorithms […] The post Practicing Machine Learning with Imbalanced Dataset appeared first on Analytics Vidhya.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
If you haven’t heard, Confluent announced they’re buying Immerok. This purchase represents a significant shift in strategy for Confluent. I started a Twitter thread with some of my initial thoughts, but I want to write a post giving more analysis and opinions. In short, I still echo the sentiment from my original tweet “This was always the way it should have been.
Introducing fully managed Apache Kafka® + Flink for the most robust, cloud-native data streaming platform with stream processing, integration, and streaming analytics in one.
Effective solutions exist when you don't have enough data for your models. While there is no perfect approach, five proven ways will get your model to production.
This is a collaborative post from Databricks and wisecube.ai. We thank Vishnu Vettrivel, Founder, and Alex Thomas, Principal Data Scientist, for their contributions.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Managing network solutions amidst a growing scale inherently brings challenges around performance, deployment, and operational complexities. At Meta, we’ve found that these challenges broadly fall into three themes: 1.) Data center networking: Over the past decade, on the physical front, we have seen a rise in vendor-specific hardware that comes with heterogeneous feature and architecture sets (e.g., non-blocking architecture).
Introduction We are all aware of the Internet’s explosive expansion as a primary source of information and a platform for opinion expression. It has now become essential to gather and analyze the ever-expanding data that follows. While in the past, manual analysis of data has been possible and even served us well, the same cannot […] The post Top 10 Applications of Sentiment Analysis in Business appeared first on Analytics Vidhya.
Summary Business intelligence has gone through many generational shifts, but each generation has largely maintained the same workflow. Data analysts create reports that are used by the business to understand and direct the business, but the process is very labor and time intensive. The team at Omni have taken a new approach by automatically building models based on the queries that are executed.
My view from the train window ( credits ) Dear Data News readers it's a joy every week to write this newsletter, we are slowly approaching the second birthday of this newsletter. In order to celebrate this together I'd love to receive your stories about data —can be short or long, anonymous or not. This is an open box, just write me with what you have on the mind and I'll bundle an edition with it.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Modern data stack consultant plays an important role in companies looking to become data-driven. They help companies design and deploy centralized data sets that are easy to use and reliable. They do so by using cloud based solutions that help automate data pipelines and processes with less code than in the past. But in order… Read more The post Do You Need A Modern Data Stack Consultant appeared first on Seattle Data Guy.
In part I, The Open Data Stack Distilled into Four Core Tools, we discussed how to quickly set up a data stack, tackling end-to-end data analytics challenges. As a manager or developer working with data at a mid- to large-sized enterprise, you might ask why aren’t we using any of these tools. In this article, we dive into what mid-to-large-sized companies are using instead, the struggle of setting up a Modern Data Stack (MDS) for an enterprise size, and the opportunities of a free-of-charge and
Introduction YARN stands for Yet Another Resource Negotiator. It is a powerful resource management system for a horizontal server environment. It is designed to be more flexible and generic than the original Hadoop MapReduce system, making it an attractive choice for companies looking to implement Hadoop. It allows companies to process data types and run […] The post YARN for Large Scale Computing: Beginner’s Edition appeared first on Analytics Vidhya.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Summary The most interesting and challenging bugs always happen in production, but recreating them is a constant challenge due to differences in the data that you are working with. Building your own scripts to replicate data from production is time consuming and error-prone. Tonic is a platform designed to solve the problem of having reliable, production-like data available for developing and testing your software, analytics, and machine learning projects.
Summer in coming ( credits ) Hey, new Friday, new Data News edition. I'm so happy to see new people coming every week. Thank you for every recommendation you do about the blog or the Data News. This kindness for my content gives me wings. This week I don't want to be late, so let's start the weekly wrap-up. I got less inspired this week, it means shorter edition.
Is ChatGPT useful for Python programmers, specifically those of us who use Python for data processing, data cleaning, and building machine learning models? Let's give it a try and find out.
Good Design Is Easier to Change Than Bad Design – The Pragmatic Programmer Programming is just one aspect of the difficulties of tech work for data engineers. Creating simple yet robust systems that help manage your data infrastructure is equally important. This challenge of building a simple yet robust data infrastructure remains even with no-code/low-code solutions.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








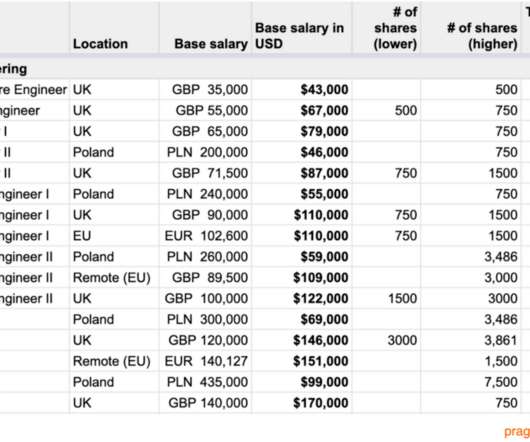



































Let's personalize your content