This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Pythonistas at Netflix, coordinated by Amjith Ramanujam and edited by Ellen Livengood As many of us prepare to go to PyCon, we wanted to share a sampling of how Python is used at Netflix. We use Python through the full content lifecycle, from deciding which content to fund all the way to operating the CDN that serves the final video to 148 million members.
At Confluent, we see many of our customers are on AWS, and we’ve noticed that Amazon S3 plays a particularly significant role in AWS-based architectures. Unless a use case actively requires a specific database, companies use S3 for storage and process the data with Amazon Elastic MapReduce (EMR) or Amazon Athena. But even if a use case requires a specific database such as Amazon Redshift, data will still land to S3 first and only then load to Redshift.
Summary Kubernetes is a driving force in the renaissance around deploying and running applications. However, managing the database layer is still a separate concern. The KubeDB project was created as a way of providing a simple mechanism for running your storage system in the same platform as your application. In this episode Tamal Saha explains how the KubeDB project got started, why you might want to run your database with Kubernetes, and how to get started.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Last month at Strata, San Francisco, we made an announcement about two upcoming products – Cloudera Flow Management and Cloudera Edge Management. Today, we are super excited to announce that both the products are generally available for use. While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterp
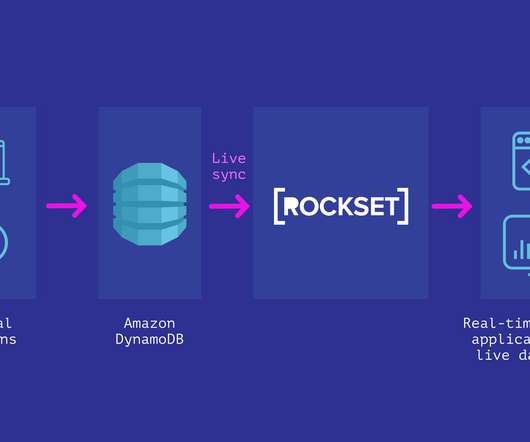
In this blog post I compare options for real-time analytics on DynamoDB - Elasticsearch , Athena, and Spark - in terms of ease of setup, maintenance, query capability, latency. There is limited support for SQL analytics with some of these options. I also evaluate which use cases each of them are best suited for. Developers often have a need to serve fast analytical queries over data in Amazon DynamoDB.
by Andrey Norkin, Joel Sole, Kyle Swanson, Mariana Afonso, Anush Moorthy, Anne Aaron Netflix Headquarters, Winchester Circle. Netflix headquarters circa 2014. It’s a nice building with good architecture! This was the primary home of Netflix for a number of years during the company’s growth, but at some point Netflix had outgrown its home and needed more space.
by Andrey Norkin, Joel Sole, Kyle Swanson, Mariana Afonso, Anush Moorthy, Anne Aaron Netflix Headquarters, Winchester Circle. Netflix headquarters circa 2014. It’s a nice building with good architecture! This was the primary home of Netflix for a number of years during the company’s growth, but at some point Netflix had outgrown its home and needed more space.
Includes free forever Confluent Platform on a single Apache Kafka ® broker, improved Control Center functionality at scale and hybrid cloud streaming. We are very excited to announce the general availability of Confluent Platform 5.2, the event streaming platform built by the original creators of Apache Kafka. Event streaming has become one of the few foundational technologies that sit at the heart of modern enterprises, redefining how you connect every existing application, while enabling you t
Summary One of the biggest challenges for any business trying to grow and reach customers globally is how to scale their data storage. FaunaDB is a cloud native database built by the engineers behind Twitter’s infrastructure and designed to serve the needs of modern systems. Evan Weaver is the co-founder and CEO of Fauna and in this episode he explains the unique capabilities of Fauna, compares the consensus and transaction algorithm to that used in other NewSQL systems, and describes the
Organizations in the financial services industry rely on data to make strategic decisions, drive their businesses, and maintain a competitive edge. The Bank of England was discovering that legacy tools were no longer sufficient to satisfy the growing demands of analysts and economists. The Bank of England is the central bank of the United Kingdom formed in 1694.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Project Highlights A new operator is added to Zalando’s list of Cloud Native Applications. Elasticsearch Operator - an operator for running Elasticsearch in Kubernetes with focus on operational aspects, like safe draining and offering auto-scaling capabilities for Elasticsearch data nodes, rather than just abstracting manifest definitions. To make things even simpler for developers, we also released a new framework that helps to build Kubernetes operators in Python.
Special thanks to Addison-Wesley Professional for permission to excerpt the following "Software Architecture" chapter from the book, Machine Learning in Production. This chapter excerpt provides data scientists with insights and tradeoffs to consider when moving machine learning models to production. Also, if you’re interested in learning about how Domino provides an API endpoint for your model, check out this video tutorial on the Domino Support site.
Event-driven architecture means just that: It’s all about the events. In a microservices architecture, events drive microservice actions. No event, no shoes, no service. In the most basic scenario, microservices that need to take action on a common stream of events all listen to that stream. In the Apache Kafka ® world, this means that each of those microservice client applications subscribes to a common Kafka topic.
Summary Database indexes are critical to ensure fast lookups of your data, but they are inherently tied to the database engine. Pilosa is rewriting that equation by providing a flexible, scalable, performant engine for building an index of your data to enable high-speed aggregate analysis. In this episode Seebs explains how Pilosa fits in the broader data landscape, how it is architected, and how you can start using it for your own analysis.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
At Teradata, we think a lot about our customers in the cloud, and continue on our promise to deliver choice and flexibility by adding new as-a-service options for Teradata Vantage.
Enterprises are moving to the cloud. In 2016, 60.9% of application workloads were still on-premises in enterprise data centers; by the end of 2017, less than half (47.2%) were on-premises. Enterprises plan to implement new apps primarily in the cloud while migrating 20.7% of existing apps to public cloud. Despite this trend to move to cloud, It will be rare for enterprises to deploy 100% of their apps in the cloud, let alone deploy all apps to a single cloud.
We all know that thread creation in Java is not free. The actual overhead varies across platforms, but thread creation takes time, introducing latency into request processing, and requires some processing activity by the JVM and OS. This is where the Thread Pool comes to the rescue. The thread pool reuses previously created threads to execute current tasks and offers a solution to the problem of thread cycle overhead and resource thrashing.
As the maintainers of dbt, and analytics consultants, at Fishtown Analytics (now dbt Labs) we build a lot of dbt projects. Over time, we’ve developed internal conventions on how we structure them. This article does not seek to instruct you on how to design a final model for your stakeholders — it won’t cover whether you should denormalize everything into one wide master table , or have many tables that need to be joined together in the BI layer.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
When it was first created, Apache Kafka ® had a client API for just Scala and Java. Since then, the Kafka client API has been developed for many other programming languages which enables you to pick the language you want. This freedom of choice ultimately allows you to build an event streaming platform with the language best suited to your business needs.
Summary How much time do you spend maintaining your data pipeline? How much end user value does that provide? Raghu Murthy founded DataCoral as a way to abstract the low level details of ETL so that you can focus on the actual problem that you are trying to solve. In this episode he explains his motivation for building the DataCoral platform, how it is leveraging serverless computing, the challenges of delivering software as a service to customer environments, and the architecture that he has de
Chris Twogood explains while large companies who utilize data need Pervasive Data Intelligence in order to leverage all of their data, all of the time.
All organizations, big or small, have a unique corporate culture that has been nurtured and mastered over the years. A company’s culture is its basic personality and the essence of how employees interact and work. It is the sum of company beliefs, ethics, expectations, goals, value and mission. The company culture is normally where brand promises are either kept or broken.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
In this post I explore how to support analytical queries without encountering prohibitive scan costs, by leveraging secondary indexes in DynamoDB. I also evaluate the pros and cons of this approach in contrast to extracting data to another system like Athena, Spark or Elastic. Rockset recently added support for DynamoDB - which basically means you can run fast SQL on DynamoDB tables without any ETL.
Black Friday is the busiest day of the year for us, with over 4,200 orders per minute during the event in 2018. We need to make sure we’re technically able to handle the huge influx of customers. As a part of our preparations we ask all of our teams to perform load tests to ensure their individual components will handle the expected load. In addition, and due to the distributed nature of our system's architecture , we also need to ensure it will handle the expected load once all components have
It seems like there’s a Kafka Summit every other month. Of course there’s not—it’s every fourth month—but hey, close enough. We now have the Kafka Summit New York in the books, and the session videos are available in record time. As I usually do, let me break the event down for you. We planned the New York event to be a bit smaller than last fall’s flagship San Francisco Summit.
I’m excited to announce that we’re partnering with Google Cloud to make Confluent Cloud, our fully managed offering of Apache Kafka ® , available as a native offering on Google Cloud Platform (GCP). This means you will have the ability to use Confluent Cloud’s managed Apache Kafka service with familiar Google tools and processes, including integration into the Google Cloud Console and GCP Marketplace to provide a seamless sign-up experience, and integrated billing and first-line support provided
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
KSQL enables you to write streaming applications expressed purely in SQL. There’s a ton of great new features in 5.2, many of which are a result of requests and support from the community—we use GitHub to track these, and I’ve indicated in each point below the corresponding issue. If you have suggestions for new features, please do be sure to search our GitHub issues page and upvote, or create a new issue as appropriate.
So you’ve convinced your friends and stakeholders about the benefits of event-driven systems. You have successfully piloted a few services backed by Apache Kafka ® , and it is now supporting business-critical dataflow. Each distinct service has a nice, pure data model with extensive unit tests, but now with new clients (and consequently new requirements) coming thick and fast, the number of these services is rapidly increasing.
With the release of Apache Kafka ® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. This framework opens the door for various optimization techniques from the existing data stream management system (DSMS) and data stream processing literature. In what follows, we provide some context around how a processor topology was generated inside Kafka Streams before 2.1, with a focus on stateful operations like aggregations and joins.
Enterprises run modern data systems and services across multiple cloud providers, private clouds and on-prem multi-datacenter deployments. Instead of having many point-to-point connections between sites, the Confluent Platform provides an integrated event streaming architecture with frictionless data replication between sites. Applications can publish streams of data to a self-hosted on-prem cluster, replicate them to another on-prem cluster or to different cloud providers, load them into data s
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content