This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ive been reading a lot about the rapid pace of change as if change itself is a new thing. The reality is that business has always been defined by rapid change, and change, by definition, is always disruptive to something. When I joined the workforce, desktop computing, the Blackberry, email, and the dot-com boom were the catalysts that disrupted workplace norms.
The database landscape has reached 394 ranked systems across multiple categoriesrelational, document, key-value, graph, search engine, time series, and the rapidly emerging vector databases. As AI applications multiply quickly, vector technologies have become a frontier that data engineers must explore. The essential questions to be answered are: When should you choose specialized vector solutions like Pinecone, Weaviate, or Qdrant over adding vector extensions to established databases like Post
The enterprise AI landscape is expanding all the time. With that expansion comes new challenges and new learning opportunities when it comes to GenAI development. Every day, the engineering team at Monte Carlo works with hundreds of customers across industries who are building AI in production today by monitoring the structured data and RAG pipelines that power their applications, from chatbots and cloud spend optimization to self-service analytics enablement and structuring unstructured data a
You want to learn data engineering, but dont know where to start? Here are the suggestions of five free online courses, with some additional resources for skill practicing.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Megan Blake, Usha Amrutha Nookala, Jeremy Browning, Sarah Tao, AJ Oxendine, SiddarthMalreddy Overview &Context The holiday shopping season presents a unique challenge: helping millions of Pinners discover and save perfect gifts across a vast sea of possibilities. While Pinterest has always been a destination for gift inspiration, our data showed that users were facing two key friction points: discovery overwhelm and fragmented wishlists.
Welcome to Snowflakes Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. By integrating AI agents, ROE AIs platform simplifies data processing, enabling organizations across industries to automate manual workflows and derive
We want to capture an accurate snapshot of software engineering, today – and need your help! Tell us about your tech stack and get early access to the final report, plus extra analysis We’d like to know what tools, languages, frameworks and platforms you are using today. Which tools/frameworks/languages are popular and why?
We want to capture an accurate snapshot of software engineering, today – and need your help! Tell us about your tech stack and get early access to the final report, plus extra analysis We’d like to know what tools, languages, frameworks and platforms you are using today. Which tools/frameworks/languages are popular and why?
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? Over the years of working with data analytics teams in large and small companies, we have been fortunate enough to observe hundreds of companies. We want to share our observations about data teams, how they work and think, and their challenges. We’ve identified two distinct types of data teams: process-centric and data-centric.
Explore how AI agents are transforming industries, from chatbots to autonomous vehicles, and learn what data scientists need to know to implement them effectively.
Since I started working in tech, one goal that kept coming up was workflow automation. Whether automating a report or setting up retraining pipelines for machine learning models, the idea was always the same: do less manual work and get more consistent results. But automation isnt just for analytics. RevOps teams want to streamline processes… Read more The post Best Automation Tools In 2025 for Data Pipelines, Integrations, and More appeared first on Seattle Data Guy.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
Apache Iceberg is a modern table format designed to overcome the limitations of traditional Hive tables, offering improved performance, consistency, and scalability. In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern data lakes. Well also dive into […] The post How to Use Apache Iceberg Tables?
In this episode of Unapologetically Technical, I interview Adrian Woodhead, a distinguished software engineer at Human and a true trailblazer in the European Hadoop ecosystem. Adrian, who even authored a chapter in the seminal work “Hadoop: The Definitive Guide,” shares his remarkable journey through the tech world, from his roots in South Africa to his current role pushing the boundaries of data engineering.
Many data engineers and analysts start their journey with Postgres. Postgres is powerful, reliable, and flexible enough to handle both transactional and basic analytical workloads. It’s the Swiss Army knife of databases, and for many applications, it’s more than sufficient. But data volumes grow, analytical demands become more complex, and Postgres stops being enough.
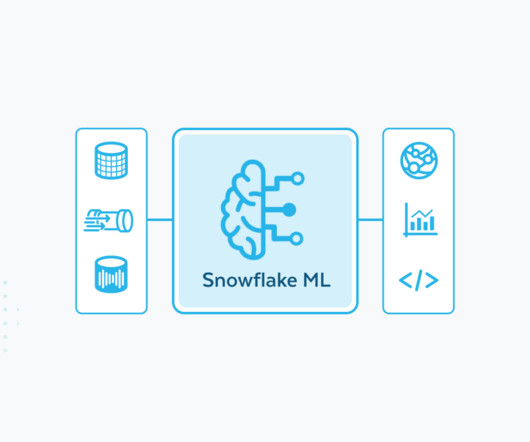
Despite the best efforts of many ML teams, most models still never make it to production due to disparate tooling, which often leads to fragmented data and ML pipelines and complex infrastructure management. Snowflake has continuously focused on making it easier and faster for customers to bring advanced models into production. In 2024, we launched over 200 AI features, including a full suite of end-to-end ML features in Snowflake ML , our integrated set of capabilities for machine learning mode
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
LLMs are not just limited by hallucinationsthey fundamentally lack awareness of their own capabilities, making them overconfident in executing tasks they dont fully understand. While vibe coding embraces AIs ability to generate quick solutions, true progress lies in models that can acknowledge ambiguity, seek clarification, and recognise when they are out of their depth.
Data integration is critical for organizations of all sizes and industriesand one of the leading providers of data integration tools is Talend, which offers the flagship product Talend Studio. In 2023, Talend was acquired by Qlik, combining the two companies data integration and analytics tools under one roof. In January 2024, Talend discontinued Talend Open… Read more The post Alternatives to Talend How To Migrate Away From Talend For Your Data Pipelines appeared first on Seattle Data Gu
Data is at the core of everything, from business decisions to machine learning. But processing large-scale data across different systems is often slow. Constant format conversions add processing time and memory overhead. Traditional row-based storage formats struggle to keep up with modern analytics. This leads to slower computations, higher memory usage, and performance bottlenecks.
The blog post reviews an Apache Incubating project called Apache XTable, which aims to provide cross-format interoperability among Delta Lake, Apache Hudi, and Apache Iceberg. Below is a concise breakdown from some time I spend playing around this this new tool and some technical observations: 1. What is Apache XTable? Not a New Format: Its […] The post Apache XTable.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. (Refer to our recent overview for more details). However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly.
Welcome to Snowflakes Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. In this edition, find out how Evan Powell, founder and CEO of DeepTempo , is harnessing AI alongside a team of skilled security experts to protect the digital world from increasingly sophisticated cyberattacks. Describe your company in one sentence.
Compared to large language models (LLMs), which are limited in size, speed, and ease of customization, small language models (SLMs) would be a more economical, efficient, and space-saving AI technology for users with limited resources. With fewer parameters (usually less than 10 billion), SLMs are assumed to have lower computational and energy costs.
Real-time data access is critical in e-commerce, ensuring accurate pricing and availability. At Zalando, our event-driven architecture for Price and Stock updates became a bottleneck, introducing delays and scaling challenges. This post covers how we redesigned our approach and built a blazingly fast API capable of serving millions of requests per second with single-digit-millisecond latency.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Is your data AI-ready? That was a consistent theme at this years Gartner Data & Analytics Summit in Orlando, Florida. There were many Gartner keynotes and analyst-led sessions that had titles like: Scale Data and Analytics on Your AI Journeys” What Everyone in D&A Needs to Know About (Generative) AI: The Foundations AI Governance: Design an Effective AI Governance Operating Model The advice offered during the event was relevant, valuable, and actionable.
Context and Motivation dbt (Data Build Tool): A popular open-source framework that organizes SQL transformations in a modular, version-controlled, and testable way. Databricks: A platform that unifies data engineering and data science pipelines, typically with Spark (PySpark, Scala) or SparkSQL. The post explores whether a Databricks environmentoften used for Lakehouse architecturesbenefits from dbt, especially if […] The post dbt on Databricks. appeared first on Confessions of a Data Guy.
Nearly nine out of 10 business leaders say their organizations data ecosystems are ready to build and deploy AI, according to a recent survey. But 84% of the IT practitioners surveyed spend at least one hour a day fixing data problems. Seventy percent spend one to four hours a day remediating data issues, while 14% spend more than four hours each day.
Apache Airflow® is the open-source standard to manage workflows as code. It is a versatile tool used in companies across the world from agile startups to tech giants to flagship enterprises across all industries. Due to its widespread adoption, Airflow knowledge is paramount to success in the field of data engineering.
Multimodal AI models capable of processing multiple different types of inputs like speech, text, and images have been transforming user experiences in the wearables space. With our Ray-Ban Meta glasses, multimodal AI helps the glasses see what the wearer is seeing. This means anyone wearing Ray-Ban Meta glasses can ask them questions about what theyre looking at.
The modern data stack constantly evolves, with new technologies promising to solve age-old problems like scalability, cost, and data silos. Apache Iceberg, an open table format, has recently generated significant buzz. But is it truly revolutionary, or is it destined to repeat the pitfalls of past solutions like Hadoop? In a recent episode of the Data Engineering Weekly podcast, we delved into this question with Daniel Palma, Head of Marketing at Estuary and a seasoned data engineer with over a
In today’s fast-paced digital world, maintaining high standards and addressing contemporary requirements is crucial for any company. One of our customers, a leading automotive manufacturer, relies on the IBM Z for its computing power and rock-solid reliability. However, they faced a growing challenge: integrating and accessing data across a complex environment.
Speaker: Jay Allardyce, Deepak Vittal, Terrence Sheflin, and Mahyar Ghasemali
As we look ahead to 2025, business intelligence and data analytics are set to play pivotal roles in shaping success. Organizations are already starting to face a host of transformative trends as the year comes to a close, including the integration of AI in data analytics, an increased emphasis on real-time data insights, and the growing importance of user experience in BI solutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content