This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction. Recently there has been substantial discussion around the downsides of service oriented architectures and microservice architectures in particular. While only a few years ago, many people readily adopted microservice architectures due to the numerous benefits they provide such as … The post Introducing Domain-Oriented Microservice Architecture appeared first on Uber Engineering Blog.
To help our customers navigate the world's new normal, our teams have created a business-centric, execution-focused tool – we call it the Resiliency Dashboard.
With billions of Internet of Things (IoT) devices, achieving real-time interoperability has become a major challenge. Together, Confluent, Waterstream, and MQTT are accelerating Industry 4.0 with new Industrial IoT (IIoT) […].
What is data quality As the name suggest, it refers to the quality of our data. Quality should be defined based on your project requirements. It can be as simple as ensuring a certain column has only the allowed values present or falls within a given range of values to more complex cases like, when a certain column must match a specific regex pattern, fall within a standard deviation range, etc.
Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.
Summary A majority of the scalable data processing platforms that we rely on are built as distributed systems. This brings with it a vast number of subtle ways that errors can creep in. Kyle Kingsbury created the Jepsen framework for testing the guarantees of distributed data processing systems and identifying when and why they break. In this episode he shares his approach to testing complex systems, the common challenges that are faced by engineers who build them, and why it is important to und
Today’s retailers face an abundance of data scattered across their organizations. The way forward is as much about having a strategic approach to data as it is about technology.
In the article Should You Put Several Event Types in the Same Kafka Topic?, Martin Kleppmann discusses when to combine several event types in the same topic and introduces new […].
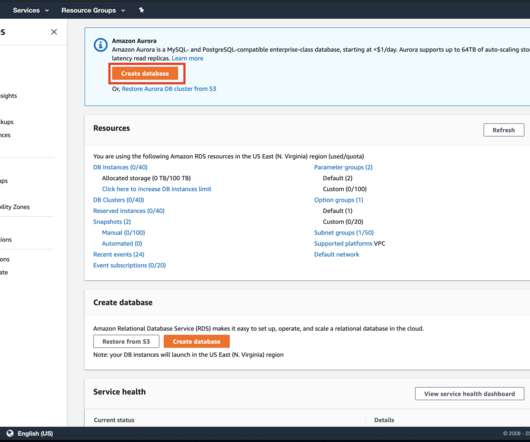
RDS AWS RDS is a managed service provided by AWS to run a relational database. We will see how to setup a postgres instance using AWS RDS. Log in to your AWS account. Go to Services -> RDS Click on Create Database, In the Create Database prompt, choose Standard Create option with PostgreSQL as engine type. In the Template section choose Free Tier and type in a DB Identifier, Master username and Master password.
Stanislav Kirdey , William High Imagine having to go through 2.5GB of log entries from a failed software build?—?3 million lines?—?to search for a bug or a regression that happened on line 1M. It’s probably not even doable manually! However, one smart approach to make it tractable might be to diff the lines against a recent successful build, with the hope that the bug produces unusual lines in the logs.
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
Summary Wind energy is an important component of an ecologically friendly power system, but there are a number of variables that can affect the overall efficiency of the turbines. Michael Tegtmeier founded Turbit Systems to help operators of wind farms identify and correct problems that contribute to suboptimal power outputs. In this episode he shares the story of how he got started working with wind energy, the system that he has built to collect data from the individual turbines, and how he is
The days are gone when defining a user experience was limited to the choice of designers. Now data plays a more important role in the design process than ever before.
The first-ever virtual Kafka Summit 2020 kicks off next month in the comfort of your home office, couch, spare bedroom, living room, outbuilding, lanai, veranda, or in-home portico, featuring an […].
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Given Source S3 path and file delimiter data warehouse connection details (endpoint, port, username, password and database name) data warehouse schema name and table name Run frequency Steps Log into your stitch account, here Click on the Destination tab and use the data warehouse connection details to establish a destination database. Click on Add Integration button on your dashboard.
The cloud-based platform allows vendors, artists and creators to connect and collaborate on visual effects (VFX) from anywhere in the… Continue reading on Netflix TechBlog ».
Summary The first stage of every data pipeline is extracting the information from source systems. There are a number of platforms for managing data integration, but there is a notable lack of a robust and easy to use open source option. The Meltano project is aiming to provide a solution to that situation. In this episode, project lead Douwe Maan shares the history of how Meltano got started, the motivation for the recent shift in focus, and how it is implemented.
The Challenges of Medical Data In recent times, there have been several developments in applications of machine learning to the medical industry. We have heard news of machine learning systems outperforming seasoned physicians on diagnosis accuracy, chatbots that present recommendations depending on your symptoms , or algorithms that can identify body parts from transversal image slices , just to name a few.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Don't impose an unnecessary lockdown on your data consumers by choosing the wrong data analytics platform. Choose Teradata Vantage to set them free. Read more.
ksqlDB 0.10 includes significant changes and improvements to how keys are handled. This is part of a series of enhancements that began with support for non-VARCHAR keys and will ultimately […].
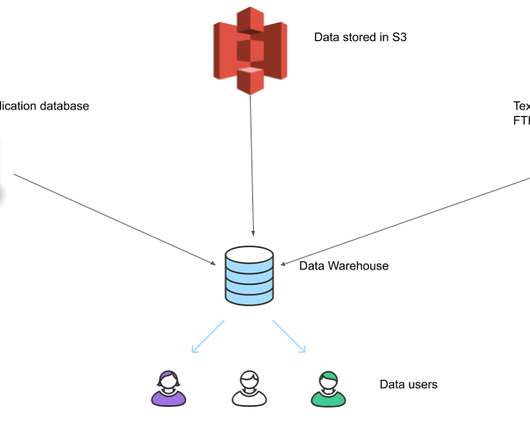
Intro A very common use case in data engineering is to build a ETL system for a data warehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application performance and the source data is disconnected as shown below.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Summary There are an increasing number of use cases for real time data, and the systems to power them are becoming more mature. Once you have a streaming platform up and running you need a way to keep an eye on it, including observability, discovery, and governance of your data. That’s what the Lenses.io DataOps platform is built for. In this episode CTO Andrew Stevenson discusses the challenges that arise from building decoupled systems, the benefits of using SQL as the common interface f
The objective of this blog To give you the tools and the skills to connect to Xero Accounting from the Power BI Desktop and to have immediate access to the categorized data that drives each of the built-in reports in Xero. What you need to get started To get quick immediate access to the data that drives the Xero Reports and push them into Power BI, you’ll need 3 tools : Power BI Desktop : Download here>> ‘Quick Reports’ Power BI Custom Connector for Xero AND Power BI Quick Reports Templ
For today's Telco providers, new products & services are all driven by the end consumer's experience. That's where Teradata's Network Experience Analytics comes to play.
This is the third month of Project Metamorphosis, where we discuss new features in Confluent’s offerings that bring together event streams and the best characteristics of modern cloud data systems. […].
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Given Source database connection details (endpoint, port, username, password and database name) Source table to replicate destination schema name run frequency can be set to 10min We are assuming the destination data warehouse is already setup in stitch. Steps Log into your stitch account. here Click on Add Integration button on your dashboard. Choose PostgreSQL option as the integration in the next page.
Read performance is crucial for databases. If it takes too long to read a record from a database, this can stall the request for data from the client application, which could result in unexpected behavior and adversely impact user experience. For these reasons, the read operation on your database should last no more than a fraction of a second. There are a number of ways to improve database read performance, though not all of these methods will work for every type of application.
At Grouparoo, our front-end website is built using React and Next.js. Next.js is an excellent tool made by Vercel that handles all the hard parts of making a React app for you - Routing, Server-side Rendering, Page Hydration and more. It includes a simple starting place to build your routes and pages, based on the file system. If you want a /about page, just make an /pages/about.tsx file!
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content