This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Change data capture is a software design pattern used to capture changes to data and take corresponding action based on that change. The change to data is usually one of read, update or delete. The corresponding action usually is supposed to occur in another system in response to the change that was made in the source system.
Currently, Apache Kafka® uses Apache ZooKeeper™ to store its metadata. Data such as the location of partitions and the configuration of topics are stored outside of Kafka itself, in a […].
Should you do a masters degree in data science in Germany? Why not, but keep the following in mind! In general, it is very, very practical in Germany because it doesn't cost a lot of money to study. Not like for example in the USA or something like that. So if you are interested in it, you should first think about what the corresponding Master's programme is about.
Advanced analytics & AI techniques can help in curtailing the COVID-19 pandemic. This post describes an analytics prototype to build an early warning system for COVID-19.
Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.
Summary Gaining a complete view of the customer journey is especially difficult in B2B companies. This is due to the number of different individuals involved and the myriad ways that they interface with the business. Dreamdata integrates data from the multitude of platforms that are used by these organizations so that they can get a comprehensive view of their customer lifecycle.
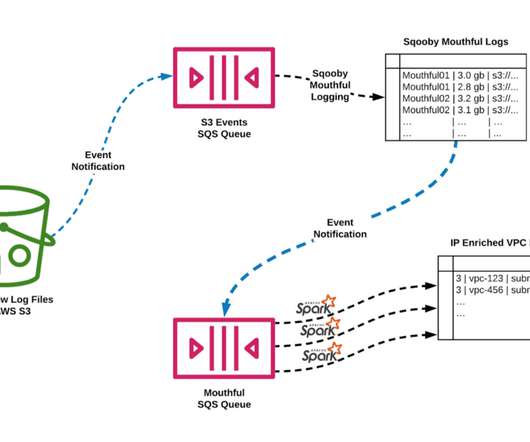
How Netflix is able to enrich VPC Flow Logs at Hyper Scale to provide Network Insight By Hariharan Ananthakrishnan and Angela Ho The Cloud Network Infrastructure that Netflix utilizes today is a large distributed ecosystem that consists of specialized functional tiers and services such as DirectConnect, VPC Peering, Transit Gateways, NAT Gateways, etc.
Introduction Approach Project overview Engineering Design Airflow Primer: Setup Code and explanation Stage 1. pg -> file -> s3 Stage 2. file -> s3 -> EMR -> s3 Stage 3. movie_review_stage, user_purchase_stage -> Redshift table -> quality Check data Monitoring ETL Design Review Common Scenarios Next Steps Conclusion Introduction Starting out in data engineering can be a little intimidating, especially because data engineering involves a lot of moving parts.
Introduction Approach Project overview Engineering Design Airflow Primer: Setup Code and explanation Stage 1. pg -> file -> s3 Stage 2. file -> s3 -> EMR -> s3 Stage 3. movie_review_stage, user_purchase_stage -> Redshift table -> quality Check data Monitoring ETL Design Review Common Scenarios Next Steps Conclusion Introduction Starting out in data engineering can be a little intimidating, especially because data engineering involves a lot of moving parts.
Imagine you’ve got a stream of data; it’s not “big data,” but it’s certainly a lot. Within the data, you’ve got some bits you’re interested in, and of those bits, […].
Lot's of people like notebooks and so do I. Jupyter Notebooks for instance, are great to quickly explore some data or try something out. If you want to bring code into production however, you should or most likely, have to write standalone scripts. If you want to create something for production and then do it in production, Jupiter notebooks are not ideal.
Supply Chain organizations need visibility now to leverage data for making decisions and taking action, both in times of crisis and in relative stability.
Summary The PostgreSQL database is massively popular due to its flexibility and extensive ecosystem of extensions, but it is still not the first choice for high performance analytics. Swarm64 aims to change that by adding support for advanced hardware capabilities like FPGAs and optimized usage of modern SSDs. In this episode CEO and co-founder Thomas Richter discusses his motivation for creating an extension to optimize Postgres hardware usage, the benefits of running your analytics on the same
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
A few weeks ago when we talked about our new fundraising, we also announced we’d be kicking off Project Metamorphosis. What is Project Metamorphosis? Let me try to explain. I […].
I love working with Zeppelin notebooks. Its so simple and you can just try something out. Especially working with dataframes and SparkSQL is a blast. What is a Zeppelin? A Zeppelin is a tool, a notebook tool, just like Jupiter. You can run it on a server and you can run it on your Hadoop cluster or whatever. And it can run Spark jobs in the background.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Teradata's Board of Directors has selected the company's next President and Chief Executive Officer: Steve McMillan. Read more from interim President and CEO, Vic Lund.
Summary There have been several generations of platforms for managing streaming data, each with their own strengths and weaknesses, and different areas of focus. Pulsar is one of the recent entrants which has quickly gained adoption and an impressive set of capabilities. In this episode Sijie Guo discusses his motivations for spending so much of his time and energy on contributing to the project and growing the community.
There’s an underlying pattern prevalent today in many digital marketing tools that is causing problems. Wasted time, overpaying, slow velocity, and privacy issues for your customers are some of the results of this pattern. The problem is the over-reliance on Events. Specifically, the problem is that many marketing tools live in a world where they expect to be “pushed” data, when it would be so much better if they were “pulling” data when they needed it.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Recently, I’ve been looking at what’s possible with streams of Wi-Fi packet capture (pcap) data. I was prompted after initially setting up my Raspberry Pi to capture pcap data and […].
Should companies go full blowing big data/data science platform right away? In my opinion, you should first look at the different stages you are in. Are you in the Proof-of-Concept phase, where you are just working with offline data, where you are proving your concepts? Or are you in the MVP phase or in the creation of an MVP, where you are bringing in the first users, the first customers?
Operationalizing world class analytics into day-to-day processes can help solve some of the greatest challenges in the telecommunications industry. Find out more.
Summary Data management is hard at any scale, but working in the context of an enterprise organization adds even greater complexity. Infoworks is a platform built to provide a unified set of tooling for managing the full lifecycle of data in large businesses. By reducing the barrier to entry with a graphical interface for defining data transformations and analysis, it makes it easier to bring the domain experts into the process.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Python programming is a critical skill for data engineers. When it comes to working with data, there’s a powerful library that can increase your code’s efficiency dramatically, especially when you’re working with large datasets: NumPy. That’s why we’ve added a NumPy for Data Engineers course to our Data Engineering path !
Using a powerful, event-driven application can help you unlock insights contained in the event streams of your business. Before we get into the technology, let’s go over some questions you […].
What are the job opportunities in the field of Data Science? Several, of course! Based on the 4 phases of a Data Science project, the possibilities can be worked out well. In this blog post only two of the four phases will be discussed. But now from the beginning. The four phases are: Proof-of-Concept, MVP, Validation and Scaling. The Proof of Concept Phase (PoC) Starting at the PoC phase, you could say: okay, I'm getting a research data scientist here.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
The COVID-19 pandemic has brought with it a Perfect Storm of disruption that impacts all of us -- from our health to the economy to the supply chain. Read more.
Today’s the day! There’s much buzz & excitement as we FINALLY get to see Azure Synapse Analytics in public preview, ready for us all to get our hands on it. There’s a raft of other announcements that come hand & hand with it too. What’s that? You thought Azure Synapse Analytics was already available? You’ve been using all year and don’t see what the fuss is about??
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content