This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part of our series of blog posts on recent enhancements to Impala. The entire collection is available here. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? What if our queries are very selective? The reality is that data warehousing contains a large variety of queries both small and large; there are many circumstances where Impala queries small amounts of data; when end users are iterating on a use case, filterin
Building data pipelines isn’t always straightforward. The gap between the shiny “hello world” examples of demos and the gritty reality of messy data and imperfect formats is sometimes all too […].
As a data scientist, I always felt a missing link between my developed models and putting them in the production process. Yes, I can create a pipeline, write a model, get results, and interpret the results, but if I cannot scale it, these all will sit on my Jupiter notebooks. This thought led me to my data engineering adventure. I am confident that learning data engineering will make me a better data scientist.
Introduction If you are looking for a simple, cheap data pipeline to pull small amounts of data from a stable API and store it in a cloud storage, then serverless functions are a good choice. This post aims to answer questions like the ones shown below My company does not have the budget to purchase a tool like fivetran, What should I use to pull data from an API ?
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Everyone slows to a crawl, sometimes for a minor issue or sometimes for no reason at all.
Summary The first stage of every good pipeline is to perform data integration. With the increasing pace of change and the need for up to date analytics the need to integrate that data in near real time is growing. With the improvements and increased variety of options for streaming data engines and improved tools for change data capture it is possible for data teams to make that goal a reality.
What a fantastic 24-hours it has been here at Cloudera. During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. Streamed to hundreds of people around the globe, we were able to come together to celebrate some incredible successes. . In a year marked by unusual events, and disruption to our “normal” lives, it was a pleasure to recognize our customers’ most impressive achievements.
What a fantastic 24-hours it has been here at Cloudera. During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. Streamed to hundreds of people around the globe, we were able to come together to celebrate some incredible successes. . In a year marked by unusual events, and disruption to our “normal” lives, it was a pleasure to recognize our customers’ most impressive achievements.
As a clothing retailer with more than 1.5 million customers worldwide, Boden is always looking to capitalise on business moments to drive sales. For example, when the Duchess of Cambridge […].
Currently, the big buzz about big data is probably apt with the number of technologies and tools available to build products and services. Uber, Google, Microsoft, and now Apple are implementing AI to their core business operations to provide real-time AI services in their ecosystem. I personally believe once due to this success of big data companies, the hype behind AI has blown out of proportions.
Big data's growth and its impact on business is undeniable. But how do you make the most of your data analytics to create real business value? Find out more.
Introducing gnmi-gateway: a modular, distributed, and highly available service for modern network telemetry via OpenConfig and gNMI By: Colin McIntosh, Michael Costello Netflix runs its own content delivery network, Open Connect , which delivers all streaming traffic to our members. A backbone network underlies a large portion of the CDN, and we also run the high capacity networks that support our studios and corporate offices.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Summary One of the oldest aphorisms about data is "garbage in, garbage out", which is why the current boom in data quality solutions is no surprise. With the growth in projects, platforms, and services that aim to help you establish and maintain control of the health and reliability of your data pipelines it can be overwhelming to stay up to date with how they all compare.
November 15-21 marks International Fraud Awareness Week – but for many in government, that’s every week. From bogus benefits claims to fraudulent network activity, fraud in all its forms represents a significant threat to government at all levels. Some experts estimate the U.S. government loses nearly 150 billion dollars due to potential fraud each year, McKinsey & Company reports.
I’m excited to announce a new strategic partnership with IBM. As part of this partnership, IBM will be reselling Confluent Platform, enabling its customers to leverage their existing IBM relationships […].
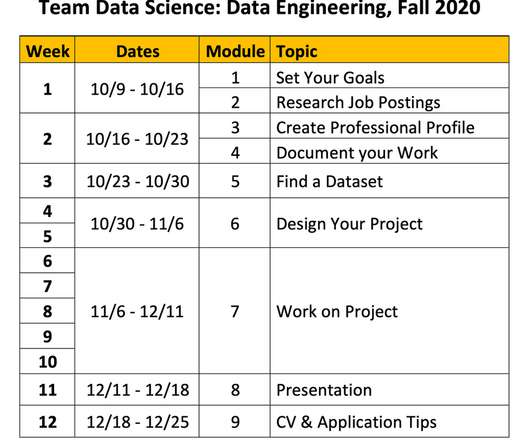
Week 1: 10/9/20 - 10/16/20 In my quest to further improve my overall data science skills, I pulled the trigger on October 9th, 2020, and enrolled in a Data Engineering boot camp lead by Andreas Kretz. First a little bit about myself. I have a background in Aerospace Engineering and have been in the industry for close to 15 years now. A little more than a year ago, I decided to pivot to Machine Learning and Data Science.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Product-centric processes degrade customer experience. Insurers must insulate consumers from internal & regulatory-driven controls by placing them in the center of the customer experience.
Running analytics on real-time data is a challenge many data engineers are facing today. But not all analytics can be done in real time! Many are dependent on the volume of the data and the processing requirements. Even logic conditions are becoming a bottleneck. For example, think about join operations on huge tables with more […] The post 5 things you should know about Real-Time Analytics appeared first on A Cloud Guru.
Summary The core mission of data engineers is to provide the business with a way to ask and answer questions of their data. This often takes the form of business intelligence dashboards, machine learning models, or APIs on top of a cleaned and curated data set. Despite the rapid progression of impressive tools and products built to fulfill this mission, it is still an uphill battle to tie everything together into a cohesive and reliable platform.
It’s all about the Customer. Customers today expect services to be highly personalized. In a digital world tuned to understand your likes, dislikes, interests and preferences we expect a similar level of customization in all aspects of our lives. Insurance is no different. Insurance is not something the average consumer thinks about every day but when a life changing event happens, insurance becomes extremely important.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
This blog post presents the use cases and architectures of REST APIs and Confluent REST Proxy, and explores a new management API and improved integrations into Confluent Server and Confluent […].
Week 2: 10/16/20 - 10/23/20 Week 2 of the course consists of Modules 3 & 4. If you have not read my first blog go here. Module 3 focuses on creating a professional LinkedIn profile. Your LinkedIn profile is the world's access to you and how you want to be seen professionally. Below is a screenshot. So here, I have a professionally taken photograph, what I am interested in below, and the 'About' section that summarizes Me.in a professional sense.
With digital payments on the rise, payment processing has become more complex. Fortunately, advanced data technologies can create better customer experience via streamlined payment processes.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Summary A data catalog is a critical piece of infrastructure for any organization who wants to build analytics products, whether internal or external. While there are a number of platforms available for building that catalog, many of them are either difficult to deploy and integrate, or expensive to use at scale. In this episode Grant Seward explains how he built Tree Schema to be an easy to use and cost effective option for organizations to build their data catalogs.
One of the many areas where machine learning has made a large difference for enterprise business is in the ability to make accurate predictions in the realm of fraud detection. Knowing that a transaction is fraudulent is a critical requirement for financial services companies, but knowing that a transaction that was flagged by a rules-based system as fraudulent is a valid transaction, can be equally important.
Software engineering memes are in vogue, and nothing is more fashionable than joking about how complicated distributed systems can be. Despite the ribbing, many people adopt them. Why? Distributed systems […].
Part 2 — A New Gold Standard Authors: Vaughn Quoss, Jonathan Parks, Paul Ellwood Introduction At Airbnb, we’ve always had a data-driven culture. We’ve assembled top-notch data science and engineering teams, built industry-leading data infrastructure, and launched numerous successful open source projects, including Apache Airflow and Apache Superset.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
This "how-to" guide will help you to connect Teradata Vantage using the Native Object Store feature to query Salesforce data sourced by Microsoft Azure Data Factory.
Photo by Markus Winkler on Unsplash By Jose Picado , Qiao Wang , and Yi Li Context Our Shop Directory is used by our consumers to discover stores, brands, and products. It is incredibly valuable for our retail partners: Almost 20 million referrals per month in the 2020 July - Sept quarter. The Shop Directory, available on the Web and our mobile app, contains nearly 64,000 stores, and each store sells 1000s of products.
Summary Data lakes are gaining popularity due to their flexibility and reduced cost of storage. Along with the benefits there are some additional complexities to consider, including how to safely integrate new data sources or test out changes to existing pipelines. In order to address these challenges the team at Treeverse created LakeFS to introduce version control capabilities to your storage layer.
Two of the more painful things in your everyday life as an analyst or SQL worker are not getting easy access to data when you need it, or not having easy to use, useful tools available to you that don’t get in your way! As one of my dear customers, a data worker in Pharma, said to me: “I really don’t care about bells and whistles, I just want to get my task done.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content