This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today marks the beginning of an exciting new chapter for Cloudera. Cloudera will become a private company with the flexibility and resources to accelerate product innovation, cloud transformation and customer growth. Cloudera will benefit from the operating capabilities, capital support and expertise of Clayton, Dubilier & Rice (CD&R) and KKR – two of the most experienced and successful global investment firms in the world recognized for supporting the growth strategies of the businesses
As a recap from the last article , Uber’s API Gateway provides an interface and acts as a single point of access for all of our back-end services to expose features and data to Mobile and 3rd party partners. Two … The post Scaling of Uber’s API gateway appeared first on Uber Engineering Blog.
Managing Apache Kafka® clusters can be tricky sometimes. To solve this problem, Confluent Control Center helps you easily manage and monitor your clusters and interact with other Confluent components, such […].
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. At much less than 1% of CPU and memory on the instance, this highly performant sidecar provides flow data at scale for network insight.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Introduction Objective Setup Pre-requisites Project 1. ETL Code 2. Test 3. Scheduler 4. Presentation 4.1. Formatting, Linting, and Type checks 4.2. Architecture Diagram 4.3. README.md 5. Adding Dashboard to your Profile Future Work Tear down infra Conclusion Further Reading References Introduction Building a data project for your portfolio is hard. Getting hiring managers to read through your Github code is even harder.
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machine learning. For example, Netflix takes advantage of ML algorithms to personalize and recommend movies for clients, saving the tech giant billions. Google, in turn, uses the Google Neural Machine Translation (GNMT) system, powered by ML, reducing error rates by up to 60 percent.
At the end of March, we released the first version of Cloudera SQL StreamBuilder as part of CSA 1.3. It enabled users to easily write, run and manage real-time SQL queries on streams from Apache Kafka with an exceptionally smooth user experience. . Since then, we have been working hard to expose the full power of Apache Flink SQL and the existing Data Warehousing tools in CDP to combine it into a state-of-the-art real-time analytics platform.
At the end of March, we released the first version of Cloudera SQL StreamBuilder as part of CSA 1.3. It enabled users to easily write, run and manage real-time SQL queries on streams from Apache Kafka with an exceptionally smooth user experience. . Since then, we have been working hard to expose the full power of Apache Flink SQL and the existing Data Warehousing tools in CDP to combine it into a state-of-the-art real-time analytics platform.
Introduction. Uber relies on a containerized microservice architecture. Our need for computational resources has grown significantly over the years, as a consequence of business’ growth. It is an important goal now to increase the efficiency of our computing resources. Broadly … The post Efficient and Reliable Compute Cluster Management at Scale appeared first on Uber Engineering Blog.
Making changes to a database schema is a natural part of software development. Often, it’s important to carefully manage the timing of changes and keep track of them over time. […].
Summary While the overall concept of timeseries data is uniform, its usage and applications are far from it. One of the most demanding applications of timeseries data is for application and server monitoring due to the problem of high cardinality. In his quest to build a generalized platform for managing timeseries Paul Dix keeps getting pulled back into the monitoring arena.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Hadoop and Spark are the two most popular platforms for Big Data processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. But which one of the celebrities should you entrust your information assets to? To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop?
Cloudera has been named as a Strong Performer in the Forrester Wave for Streaming Analytics, Q2 2021. We are excited to be recognized in this wave at, what we consider to be, such a strong position. We are proud to have been named as one of “ The 14 providers that matter most ” in streaming analytics. The report states that richness of analytics, development tool options and near-effortless scalability are what streaming analytics customers should look for in a provider. .
Introduction to Flaky Tests. Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns software engineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability. It also … The post Handling Flaky Unit Tests in Java appeared first on Uber Engineering Blog.
Al data til folket (all data to the people) is a compelling proposition in an enterprise context. Yet the ability to quickly address integration challenges and deliver data to those […].
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Summary Data Engineering is a broad and constantly evolving topic, which makes it difficult to teach in a concise and effective manner. Despite that, Daniel Molnar and Peter Fabian started the Pipeline Academy to do exactly that. In this episode they reflect on the lessons that they learned while teaching the first cohort of their bootcamp how to be effective data engineers.
In May 2021 at the CDO & Data Leaders Global Summit, DataKitchen sat down with the following data leaders to learn how to use DataOps to drive agility and business value. Kurt Zimmer, Head of Data Engineering for Data Enablement at AstraZeneca. Ryan Chapin, Former Executive Manager, Advanced Additive Design, Chief Product and Portfolio Manager, GE Aviation.
In today’s society, insurers can no longer ignore the mounting expectations of customers. Clients now expect insurers to provide different levels of personalization that are fast, adaptable, and up to date. That is why some insurers have gone further to provide insurance and risk management services that can be adjusted and rewritten in real-time depending on the changing risk in the consumer’s life.
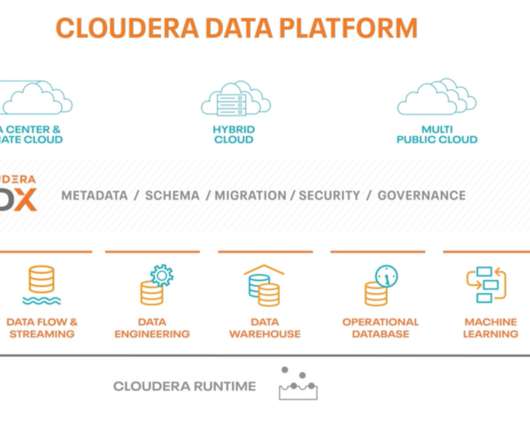
How to optimize an enterprise data architecture with private cloud and multiple public cloud options? As the inexorable drive to cloud continues, telecommunications service providers (CSPs) around the world – often laggards in adopting disruptive technologies – are embracing virtualization. Not only that, but service providers have been deploying their own clouds, some developing IaaS offerings, and partnering with cloud native content providers like Netflix and Spotify to enhance core telco bun
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
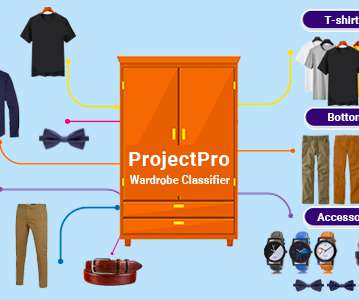
This blog will help you master the fundamentals of classification machine learning algorithms with their pros and cons. You will also explore some exciting machine learning project ideas that implement different types of classification algorithms. So, without much ado, let's dive in. Imagine that the pandemic is over and today is a weekday. All the schools, colleges, and offices are open, and you should reach your institution by 8 A.M.
One of the canonical examples of streaming data is tracking location data over time. Whether it’s ride-sharing vehicles, the position of trains on the rail network, or tracking airplanes waking […].
Summary The database is the core of any system because it holds the data that drives your entire experience. We spend countless hours designing the data model, updating engine versions, and tuning performance. But how confident are you that you have configured it to be as performant as possible, given the dozens of parameters and how they interact with each other?
A Script Authoring Specification By: Bhanu Srikanth, Andy Swan, Casey Wilms, Patrick Pearson The Art of Dubbing and Subtitling Dubbing and subtitling are inherently creative processes. At Netflix, we strive to make shows as joyful to watch in every language as in the original language, whether a member watches with original or dubbed audio, closed captions, forced narratives, subtitles or any combination they prefer.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Cloudera Support’s cluster validations proactively identify known problem signatures contained in customers’ diagnostic data with the goal of increasing cluster health, performance, and overall stability. Cluster validations are included in a customer’s enterprise subscription at no additional cost. All customers with access to the Support case portal will also be able to take advantage of cluster validations.
As banks learn to adjust to the changes enforced by the COVID pandemic, the attention of customers, regulators & shareholders is returning to another global crisis – climate change.
What if I told you there is a query your database can’t answer? That would probably surprise you. With decades of effort behind them, databases are one of the most […].
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Summary Working with unstructured data has typically been a motivation for a data lake. The challenge is imposing enough order on the platform to make it useful. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
By Gim Mahasintunan on behalf of Data Platform Engineering. Supporting a rapidly growing base of engineers of varied backgrounds using different data stores can be challenging in any organization. Netflix’s internal teams strive to provide leverage by investing in easy-to-use tooling that streamlines the user experience and incorporates best practices.
In this five-module course, Mike Lampa & Chris Bergh teach data professionals to plan their organization's DataOps program for low errors & fast deployment. The post Standing Up a DataOps Program for Practitioners first appeared on DataKitchen.
Apache Ozone is a distributed object store built on top of Hadoop Distributed Data Store service. It can manage billions of small and large files that are difficult to handle by other distributed file systems. As an important part of achieving better scalability, Ozone separates the metadata management among different services: . Ozone Manager (OM) service manages the metadata of the namespace such as volume, bucket and keys.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content