This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1. Introduction 2. TL;DR 3. Enabling Stakeholder data access with RAGs 3.1. Set up 3.1.1. Pre-requisite 3.1.2. Demo 3.1.3. Key terminology 3.2. Loading: Read raw data and convert them into LlamaIndex data structures 3.2.1. Read data from structured and unstructured sources 3.2.2. Transform data into LlamaIndex data structures 3.3. Indexing: Generate & store numerical representation of your data 3.
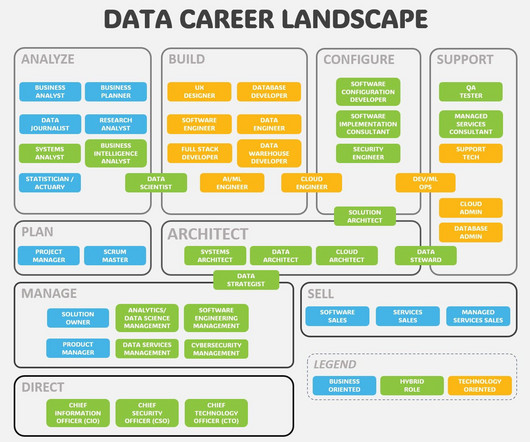
We are all looking for the right opportunities in our career. In the landscape of data-related careers, the roles can be grouped into classes, and future opportunities tend to follow natural migration paths between the class groups.
We are excited to introduce Databricks Assistant Autocomplete now in Public Preview. This feature brings the AI-powered assistant to you in real-time, providing.
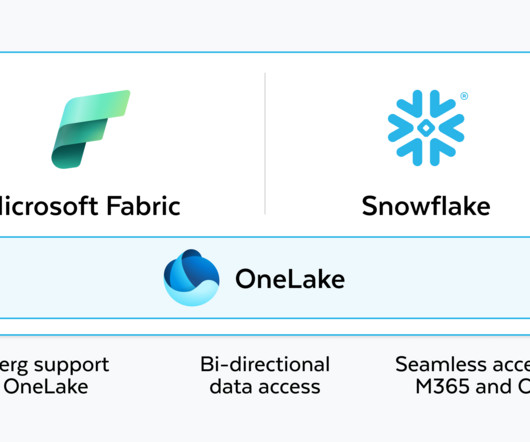
Today we’re excited to announce an expansion of our partnership with Microsoft to deliver a seamless and efficient interoperability experience between Snowflake and Microsoft Fabric OneLake, in preview later this year. This will enable our joint customers to experience bidirectional data access between Snowflake and Microsoft Fabric, with a single copy of data with OneLake in Fabric.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
by Herbert Kateu 1. Introduction This article is a follow-up to the websocket article that was published previously. To recap, we created an in-memory chat application using WebSockets with the help of the Http4s library. The chat application had a variety of features implemented through commands directly in the chat window such as the ability to create users, create chat rooms, and switch between chat rooms.
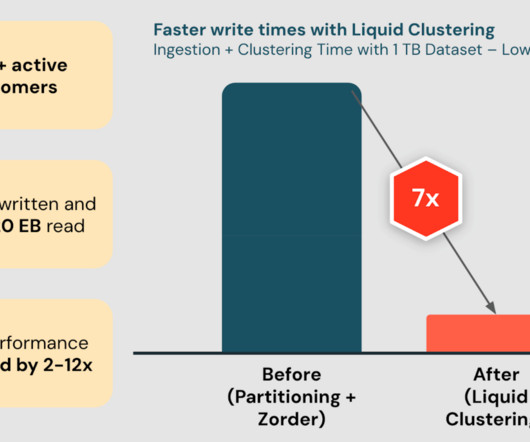
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.
Accelerating enterprise AI use cases into production is now a board-level priority for most companies. However, one of the key challenges in AI today is ensuring that those use cases are ready for real-life use and continue to perform at a high level in production. Not only must enterprises ensure accurate, reliable, and valuable results they must also address and mitigate critical issues like bias, hallucinations, and toxicity.
Today, the internet (like most digital infrastructure in general) relies heavily on the security offered by public-key cryptosystems such as RSA, Diffie-Hellman (DH), and elliptic curve cryptography (ECC). But the advent of quantum computers has raised real questions about the long-term privacy of data exchanged over the internet. In the future, significant advances in quantum computing will make it possible for adversaries to decrypt stored data that was encrypted using today’s cryptosystems.
Following the announcement we made around a suite of tools for Retrieval Augmented Generation, today we are thrilled to announce the general availability.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
With the accelerated pace of AI innovation, cybersecurity organizations are looking for new ways to empower their team members and automate security operations. Cybersecurity teams increasingly use the Data Cloud to unify security data in a scalable analytics platform to improve threat detection and response. At the same time, most enterprises have invested in monolithic security information and event management (SIEM) platforms that they can’t easily move away from without a major disruption of
If you’ve ever been in the market for a Data Engineering job, or you’re alive and on Linkedin, you’ve probably been constantly inundated with job postings and requests pounding on your emails like a constant mountain stream even bubbling down a hill. If that’s not the case, then head over to the quarterly salary discussion […] The post Why Data Engineering Pays So Well … For Some, and Poor For Others appeared first on Confessions of a Data Guy.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Welcome to Snowflake’s Startup Spotlight, where we ask startup founders about the problems they’re solving, the apps they’re building and the lessons they’ve learned during their startup journey. In this edition, we’ll learn why the founders of data tools company TDAA, Andrew Curran and Jon Farr, chose Snowflake as the platform to deliver their app Pancake , as well as the ways they’re effectively leveraging the Snowflake Native App model.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
You can find the online PMP exam application on the Project Management Institute (PMI)® website. It is essential you have the prerequisites for PMP application ready before you start the process. Demonstration that you are qualified to take the examination and that your expertise has covered all necessary domains is required. Do not let any discrepancy creep in at this stage to prevent you from obtaining your PMP credential.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
In recent years, Meta’s data management systems have evolved into a composable architecture that creates interoperability, promotes reusability, and improves engineering efficiency. We’re sharing how we’ve achieved this, in part, by leveraging Velox , Meta’s open source execution engine, as well as work ahead as we continue to rethink our data management systems.
When starting your career, it may seem like a daunting task to choose which path to take. Do you become a data scientist or Full stack developer? Both options have their benefits, but it can be tough to decide which is the right choice for you. In this blog post, we will help you to make that decision by highlighting the key differences between data science and Full stack development by comparing data scientist vs full stack developer.
In today's digital landscape, secure data sharing is critical to operational efficiency and innovation. Databricks and the Linux Foundation developed Delta Sharing as.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
In the CIA Triad in Cyber Security, you may picture a man in a black suit solving crime and running behind criminals; we are not talking about that. Our CIA triad is a fundamental cybersecurity model that acts as a foundation for developing security policies designed to protect data. Confidentiality, integrity, and availability are the three letters upon which the CIA triad stands.
The Data Team Awards annually recognize the indispensable roles of enterprise data teams across industries, celebrating their resilience and innovation from around the.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content