This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction to Flaky Tests. Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns software engineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability. It also … The post Handling Flaky Unit Tests in Java appeared first on Uber Engineering Blog.
Summary Working with unstructured data has typically been a motivation for a data lake. The challenge is imposing enough order on the platform to make it useful. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
How to optimize an enterprise data architecture with private cloud and multiple public cloud options? As the inexorable drive to cloud continues, telecommunications service providers (CSPs) around the world – often laggards in adopting disruptive technologies – are embracing virtualization. Not only that, but service providers have been deploying their own clouds, some developing IaaS offerings, and partnering with cloud native content providers like Netflix and Spotify to enhance core telco bun
In today’s society, insurers can no longer ignore the mounting expectations of customers. Clients now expect insurers to provide different levels of personalization that are fast, adaptable, and up to date. That is why some insurers have gone further to provide insurance and risk management services that can be adjusted and rewritten in real-time depending on the changing risk in the consumer’s life.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Stream processing has become an important part of the big data landscape, a new programming paradigm bringing asynchronous, long-lived computations to unbounded data in motion. But many people still think […].
Summary When you build a machine learning model, the first step is always to load your data. Typically this means downloading files from object storage, or querying a database. To speed up the process, why not build the model inside the database so that you don’t have to move the information? In this episode Paige Roberts explains the benefits of pushing the machine learning processing into the database layer and the approach that Vertica has taken for their implementation.
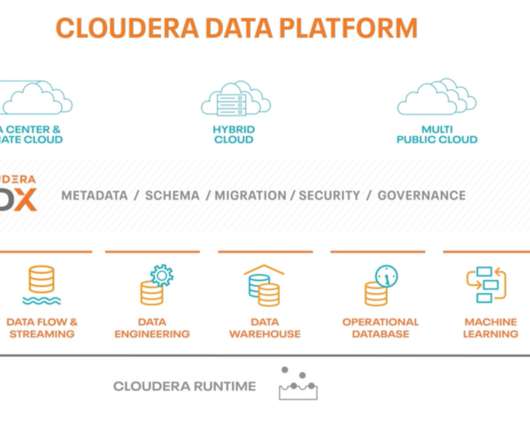
At Cloudera, we have long believed that automation is key to delivering secure, ready-to-use, and well-configured platforms. Hence, we were pleased to announce the public release of Ansible-based automation to deploy CDP Private Cloud Base. By automating cluster deployment this way, you reduce the risk of misconfiguration, promote consistent deployments across multiple clusters in your environment, and help to deliver business value more quickly. .
At Cloudera, we have long believed that automation is key to delivering secure, ready-to-use, and well-configured platforms. Hence, we were pleased to announce the public release of Ansible-based automation to deploy CDP Private Cloud Base. By automating cluster deployment this way, you reduce the risk of misconfiguration, promote consistent deployments across multiple clusters in your environment, and help to deliver business value more quickly. .
This blog post is the fourth in a four-part series that discusses a few new Confluent Control Center features that are introduced with Confluent Platform 6.2.0. It focuses on removing […].
To achieve the personalisation demanded by today’s customers, banks must look to automation. The only way to replace 1:1 branch relationships is to automate conversations with every customer.
This Pride month, we’re excited to introduce Katelynn Cusanelli. She’s a 5-year Clouderan working as a Senior Premier Support Engineer, dedicated to supporting our largest accounts. As the first openly transgender cast member of The Real World, Katelynn has spent a considerable amount of time advocating for LGBTQ rights and promoting diversity and inclusion.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? These are the most common questions that our ProjectAdvisors get asked a lot from beginners getting started with a data science career. This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
This blog post is the third in a four-part series that discusses a few new Confluent Control Center features that are introduced with Confluent Platform 6.2.0. It focuses on inspecting […].
The cloud is the design model for the Retail & CPG of the future. Simply getting to the cloud is not enough to be successful. It’s about both how you get there & what you do once you arrive.
Cambridge, Mass. – June 16, 2021. Today, DataKitchen announced the release of the latest book in its groundbreaking DataOps series, Recipes for DataOps Success: The Complete Guide to An Enterprise DataOps Transformation. This book follows on the heels of its successful precursor, The DataOps Cookbook , which has been downloaded more than 14,000 times and counting.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Data Science replicates human behavior. We have designed machine learning to imitate how we behave as humans. Think of a model in Data Science as one way to learn. Human beings have a bias when they make a choice. The way one person lives their life cannot be scaled across the human race. Instead, when multiple people share their experiences and learnings, it is possible to develop a generalized approach.
This blog post is the second in a four-part series that discusses a few new Confluent Control Center features that are introduced with Confluent Platform 6.2.0. This blog post focuses […].
Introduction to Flaky Tests. Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns software engineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability. It also … The post Handling flaky unit tests in Java appeared first on Uber Engineering Blog.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
-A mostly complete chart of neural networks is here- Understand the idea behind the neural network algorithm, the definition of a neural network, the mathematics behind the neural network algorithm, and the different types of neural networks to become a neural network pro. Let's Have Some Fun Before That.Game Time! Instead of starting with a mostly complete neural network chart, let us play a fun game first.
Learn about DataOps from data leaders Jim Tyo, Invesco CDO; Kurt Zimmer, AstraZeneca Head of Engineering for Data Enablement & Ryan Chapin, former GE exec. The post Using DataOps to Drive Agility & Business Value first appeared on DataKitchen.
Intro I first met Rockset at the 2018 Greylock Techfair. Rockset had a unique approach for attracting interest: handing out printed copies of a C program and offering a job to anyone who could figure out what the program was doing. Though I wasn’t able to solve the code puzzle, I had more luck with the interview process. I joined Rockset after graduating from UCLA in 2019.
Today, I’m excited to announce the availability of Monte Carlo’s integration partnership with PagerDuty to bring greater visibility to data pipelines and foster greater collaboration across data teams. With Monte Carlo joining PagerDuty’s Integration Partner Program, PagerDuty customers can now achieve Data Observability across every stage of the data lifecycle, from ingestion to analytics.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We experience real-time analytics everyday. The content displayed in the Instagram newsfeed, the personalized recommendations on Amazon, the promotional offers from Uber Eats are all examples of real-time analytics. The emergence of real-time analytics encourages consumers to take desired actions from reading more content, to adding items to our cart to using takeout and delivery services for more of our meals.
As more companies rely on more data to drive their product development and strategic decision making, it’s never been more important for this data to be trusted and accurate. With Monte Carlo and PagerDuty’s integration , data teams can achieve reliable data through automated lineage, real-time monitoring and alerting, and, ultimately, end-to-end data observability.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Leading companies are pioneering a shift into greater data democracy through decentralized data platforms—but without the right governance and visibility in place, data quality can suffer and trust in data can erode. That’s where data observability comes in. Here’s how the Data Engineering team at Auto Trader achieves automated monitoring and alerting while decentralizing responsibility and increasing data reliability with Monte Carlo.
“ We have a service-level agreement (SLA) for our Key Metrics table, which powers our executive dashboards. It needs to be updated every day by 7:00 am. When we miss the SLA , we have to be proactive or else we get lots of frustrated emails. Can Monte Carlo alert us if we ever miss this deadline? ” I’ve heard versions of this story dozens of times from customers over the past year.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content