This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Gathering requirements 0. Understand the current state of the data pipeline 1. Think like the end user 2. Know the why 3. End user interviews 4. Reduce the scope 5. End user walkthrough for proposed solution 6. Timelines & deliverables Deliver iteratively Conclusion Further reading References Introduction As data engineers, you will have to re-engineer legacy data pipelines.
Today, I am delighted to announce an expanded partnership with Elastic. Together, we’re enabling our joint customers to set data in motion, and through that, deliver optimized search, real-time analytics, […].
Summary One of the biggest obstacles to success in delivering data products is cross-team collaboration. Part of the problem is the difference in the information that each role requires to do their job and where they expect to find it. This introduces a barrier to communication that is difficult to overcome, particularly in teams that have not reached a significant level of maturity in their data journey.
This is part 4 in this blog series. You can read part 1 here and part 2 here , and watch part 3 here. This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on Data Collection.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
The CFO’s broad remit & natural ownership of core financial data can provide the foundation for an enhanced role that leverages data analytics to enable new value opportunities.
Apache Superset is a very popular open-source project that provides users with an exploration and visualization platform for their (big or not-so-big) data. For instance, it can be used to create line charts, but also advanced geospatial charts and dashboards that support queries via SQL Lab.
Apache Superset is a very popular open-source project that provides users with an exploration and visualization platform for their (big or not-so-big) data. For instance, it can be used to create line charts, but also advanced geospatial charts and dashboards that support queries via SQL Lab.
Insurance carriers have a unique opportunity: They have access to powerful technologies and a wealth of information that can help them to better understand their customers and provide an enhanced customer experience. . Insurance companies recognize that customer service, communication, and personalization — key tenets of any customer experience — are major components of profitability and growth.
Editor’s note: This is the third post in a series by a Palantir Software Engineer on optimizing git’s merge and rename detection machinery. Click to read the first and second posts. This is the third in a series of blog posts on scaling git’s merge and rename detection machinery. In particular, the first also included some background information on how the merge machinery works, how we use git at Palantir, and why I have worked on optimizing and rewriting it.
Ever wondered what it’s like to work at Silectis? We’re spotlighting our employees to give you a peek into our lives in and outside of work. For our first spotlight, we hear from Brendan Freehart , a true Silectis veteran who’s been with the company for almost 3 years. Brendan is a Data Engineer at Silectis, meaning he partners with our clients to help them get productive with Magpie, our data engineering platform , faster.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Enterprise data warehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern data warehouse can address them. Multiplatform. A recent Harvard Business Review study confirmed that data is increasingly being spread across data centres, private clouds and public clouds.
Hub & Spoken podcast host Jason Foster interviews DataKitchen CEO Chris Bergh on how DataOps can help improve technical data teams' performance with shorter delivery time & continuous feedback. The post How to utilise DataOps to improve the performance of Data Teams first appeared on DataKitchen.
As a core component of Industry 4.0, the Smart Factory promises significant productivity increases. But connecting a factory to the cloud & collecting data does not necessarily make it "smart.
We’re happy to announce that Confluent Cloud, our cloud-native service for Apache Kafka®, now supports Azure Private Link for secure network connectivity, in addition to the existing Azure Virtual Network […].
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Cloudera is being acknowledged by CRN®, a brand of The Channel Company, in its 2021 Partner Program Guide. This annual guide provides a conclusive list of the most distinguished partner programs from leading technology companies that provide products and services through the IT Channel. The 5-Star rating is awarded to an exclusive group of companies that offer solution providers the best of the best, going above and beyond in their partner programs.
The objective of this blog Many businesses fail to recognize a vital concept: Adoption. No, we’re not talking about adopting a new family pet, we’re referring to software and product adoption— specifically of PowerBI. Here’s a definition I like, “Adoption is the process by which users become aware of a product, understand its value , and begin to use it.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
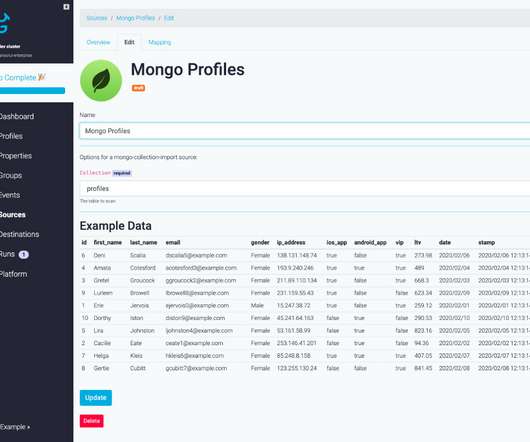
If you’re a data analyst, data scientist, developer, or DB administrator you may have used, at some point, a non-relational database with flexible schemas. Well, I could list several advantages of a NoSQL solution over SQL-based databases and vice versa. However, the main focus of this post is to discuss a particular downside of MongoDB and a possible solution to go through it.
The Data Stack Show podcast hosts Eric Dodds & Kostas Pardalis interview DataKitchen CEO Chris Bergh on why most data analytics projects fail, three things DataOps focuses on, comparing & contrasting DevOps & DataOps, & fixing problems at the source rather than downstream improvements. The post Cooking with DataOps first appeared on DataKitchen.
Data pipelines can break for a million different reasons, and there isn’t a one-size-fits all approach to understanding how or why. Here are five critical steps data engineers must take to conduct engineering root cause analysis for data quality issues. While I can’t know for sure, I’m confident many of us have been there. I’m talking about the frantic late afternoon Slack message that looks like: This exact scenario happened to me many times during my tenure at Segment.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Sequoia Capital is a venture capital firm that invests in a broad range of consumer and enterprise start-ups. To keep up with all the data around potential investment opportunities, they created a suite of internal data applications several years ago to better support their investment teams. More recently, they transitioned their internal apps from Elasticsearch to Rockset.
As you begin to read this article on Image Classification, I want you to look around and observe the things that you can see. Based on where you are sitting, the things that you see will be different. Almost 99% of the time, you can name these things, even if you don’t know the exact name, you know what it looks like. Walking on the road, you see a whole new species of a cat you have never seen before, but you still know it’s a cat, right?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content