This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
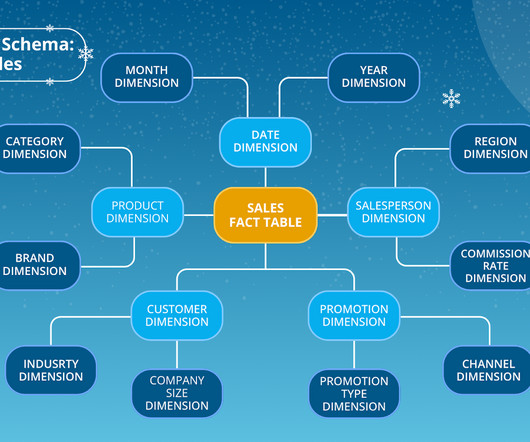
Think of your data warehouse like a well-organized library. The right setup makes finding information a breeze. The wrong one? Total chaos. Thats where data warehouse schemas come in. A data warehouse schema is a blueprint for how your data is structured and linkedusually with fact tables (for measurable data) and dimension tables (for descriptive attributes).
Charles Wu, Software Engineer | Isabel Tallam, Software Engineer | Franklin Shiao, Software Engineer | Kapil Bajaj, Engineering Manager Overview Suppose you just saw an interesting rise or drop in one of your key metrics. Why did that happen? Its an easy question to ask, but much harder toanswer. One of the key difficulties in finding root causes for metric movements is that these causes can come in all shapes and sizes.
An innovative artificial intelligence model, Stable Diffusion, can turn plain text into beautiful, high-quality pictures. This open-source application has revolutionized AI-driven creativity with its powerful deep-learning techniques. Stable Diffusion makes it easy and efficient—even on consumer-grade hardware—to generate original artwork, improve current photos, or investigate novel applications.
AI agents, autonomous systems that perform tasks using AI, can enhance business productivity by handling complex, multi-step operations in minutes. Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
In 2024, our bug bounty program awarded more than $2.3 million in bounties, bringing our total bounties since the creation of our program in 2011 to over $20 million. As part of our defense-in-depth strategy , we continued to collaborate with the security research community in the areas of GenAI, AR/VR, ads tools, and more. We also celebrated the security research done by our bug bounty community as part of our annual bug bounty summit and many other industry events.
The large model is officially a commodity. In just two short years, API-based LLMs have gone from incomprehensible to smartphone accessible. The pace of AI innovation is slowing. Real world use cases are coming into focus. Going forward, the value of your genAI applications will exist solely in the fitnessand reliabilityof your own first-party data.
If you know a lot about computers or are just starting, you have probably come across Full Stack Developer and Software Engineer roles. At first look, they may appear extremely similar. Of course, they aren’t synonymous. But what separates them? More importantly, which one do your goals better align with? In this blog on Full Stack Developers vs Software Engineers, we’ll look at their main differences.
If you know a lot about computers or are just starting, you have probably come across Full Stack Developer and Software Engineer roles. At first look, they may appear extremely similar. Of course, they aren’t synonymous. But what separates them? More importantly, which one do your goals better align with? In this blog on Full Stack Developers vs Software Engineers, we’ll look at their main differences.
A decade ago, Picnic set out to reinvent grocery shopping with a tech-first, customer-centric approach. What began as a bold experiment quickly grew into a high-scale operation, powered by continuous innovation and a willingness to challenge conventions. Along the way, weve learned invaluable lessons about scaling technology, fostering culture, and driving innovation.
Data scientists and Machine Learning engineers are both hot careers to follow with the recent advancement in technology. Both of these domains, data scientist vs machine learning engineer, are in high demand in any data-driven organization. Although data scientists and ML engineers share common ground in building models and handling data, they have differences in […] The post Data Scientist vs Machine Learning Engineer appeared first on WeCloudData.
AI is proving that its here to stay. While 2023 brought wonder and 2024 saw widespread experimentation, 2025 will be the year that the advertising, media and entertainment industry gets serious about AI's applications. But its complicated: AI proofs of concept are graduating from the sandbox to production, just as some of AIs biggest cheerleaders are turning a bit dour.
In this episode of Unapologetically Technical, I interview Semih Salihoglu, Associate Professor at the University of Waterloo and co-founder and CEO of Kuzu. Semih is a researcher and entrepreneur with a background in distributed systems and databases. He shares his journey from a small city in Turkey to the hallowed halls of Yale University, where he studied computer science and economics.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Part 1: Creating the Source of Truth for Impressions By: TulikaBhatt Imagine scrolling through Netflix, where each movie poster or promotional banner competes for your attention. Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. At Netflix, we call these images impressions, and they play a pivotal role in transforming your interaction from simple browsing into an immersive binge-watching experience, all tailo
Introduction Using Playwright snapshots with mocked data can significantly improve the speed at which UI regression is carried out. It facilitates rapid automated inspection of UI elements across the three main browsers (Chromium, Firefox, Webkit). You can tie multiple assertions to one snapshot, which greatly increases efficiency for UI testing. This type of efficiency is pivotal in a rapidly scaling GUI application.
As analytics steps into the era of enterprise AI, customers requirements for a robust platform that is easy to use, connected and trusted for their current and future data needs remain unchanged. "Serverless computing" has enabled customers to use cloud capabilities without provisioning, deploying and managing either hardware or software resources.
Read Time: 2 Minute, 55 Second Monitoring and optimizing cloud costs is a key challenge for businesses operating in cloud environments. Snowflake provides detailed usage insights, but integrating this data with AWS CloudWatch using External Functions allows organizations to track cost in real-time, set up alerts, and optimize warehouse utilization. What if we could integrate Snowflake warehouse cost tracking with AWS CloudWatch?
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
After publishing a release of my blog post about the insertInto trap, I got an intriguing question in the comments. The alternative to the insertInto, the saveAsTable method, doesn't work well on partitioned data in overwrite mode while the insertInto does. True, but is there an alternative to it that doesn't require using this position-based function?
1. Introduction 2. Data transformations as functions lead to maintainable code 3. Objects help track things (aka state) 3.1. Track connections & configs when connecting to external systems 3.2. Track pipeline progress (logging, Observer) with objects 3.3. Use objects to store configurations of data systems (e.g., Spark, etc.) 4. Class lets you define reusable code and pipeline patterns 4.1.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
At Robinhood, were committed to providing our customers with the tools they need to navigate the financial markets, no matter where they are. Thats why were excited to announce the launch of options trading for our UK customers. This is yet another step forward in our journey to expand access and empower investors across the UK. Options are contracts between buyers and sellers whose value is derived from an underlying asset, such as a stock or an index.
LangChain is a dynamic framework designed to supercharge the potential of Large Language Models (LLMs) by seamlessly integrating them with tools, APIs, and memory. It empowers developers to craft intelligent and context-aware applications, from conversational AI to workflow automation. With its modular design and versatile capabilities, LangChain transforms static LLMs into powerful engines for innovation.
Data science is a rapidly evolving and growing field with undiscovered potential. Do you find the world of data fascinating and want to know how to work as a data scientist in 2025? Whether starting your career in this domain or transitioning from another field, you need a data science roadmap to follow. WeCloudData is […] The post Data Science Roadmap for Beginners 2025-Skills, Tools, Courses & Career Prep appeared first on WeCloudData.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Few-shot learning (FSL) is changing data science by allowing models to make correct predictions using very little labeled data. Unlike traditional guided learning, which needs a lot of data, Few-Shot Learning (FSL) is about learning from just a few examples. This makes FSL perfect for situations where data is limited or difficult to get. In this blog, we’ll explore Few-shot learning, its main ideas, and how it differs from traditional learning methods.
Automate Airflow deploys with built-in CI/CD. Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities. Try Astro Free → Hugging Face: Mixture of Experts Explained The mixture of Experts (MoEs) are transformer models efficiently gaining traction in the open AI community. MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational bud
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Here's how Dask applies the building blocks of sklearn to bring ML modeling workflows to the next level of scalability via high-performance parallel computing
The world is becoming increasingly reliant on data, about 2.5 quintillion bytes of data are generated every day and thats a great sign for anyone interested in a data-driven career. There are many career paths related to data including data scientist, data analyst, ML engineer, AI engineer, BI engineer, and many more. This blog focuses […] The post Data Scientist Vs Data Analyst: Key Differences, Career Paths, and How to Choose the Right Role appeared first on WeCloudData.
Bidirectional Encoder Representations from Transformers, or BERT, is a game-changer in the rapidly developing field of natural language processing (NLP). Built by Google, BERT revolutionizes machine learning for natural language processing, opening the door to more intelligent search engines and chatbots. The design, capabilities, and impact of BERT on altering NLP applications across industries are explored in this blog.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content