This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Near-real-time insights have become a de facto requirement for Azure use cases involving scalable log analytics, time series analytics, and IoT/telemetry analytics. Azure Data Explorer (also called Kusto) is the […].
Everybody needs more data and more analytics, with so many different and sometimes often conflicting needs. Data engineers need batch resources, while data scientists need to quickly onboard ephemeral users. Data architects deal with constantly evolving workloads and business analysts must balance the urgency and importance of a concurrent user population that continues to grow.
Summary In memory computing provides significant performance benefits, but brings along challenges for managing failures and scaling up. Hazelcast is a platform for managing stateful in-memory storage and computation across a distributed cluster of commodity hardware. On top of this foundation, the Hazelcast team has also built a streaming platform for reliable high throughput data transmission.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making. But there is far less agreement on what that term “data analytics” actually means?
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Since the MongoDB Atlas source and sink became available in Confluent Cloud, we’ve received many questions around how to set up these connectors in a secure environment. By default, MongoDB […].
For enterprise organizations, managing and operationalizing increasingly complex data across the business has presented a significant challenge for staying competitive in analytic and data science driven markets. With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that data engineering has become the most in-demand role across businesses — growing at an estima
The game had changed for the retail sector long ago – but it has taken the COVID-19 crisis for people to notice. A new appreciation for the role of data in retail has emerged.
The game had changed for the retail sector long ago – but it has taken the COVID-19 crisis for people to notice. A new appreciation for the role of data in retail has emerged.
Part of our series on who works in Analytics at Netflix?—?and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. Photo from a team curling offsite?
Are you looking for a way to run AWS services on premises in your own datacenter? I am excited to share today that we have completed validation of support for […].
Announcing the finalists of the Data Impact Awards is always a highlight in our annual Cloudera calendar, and this year is no different. The 2020 entrants have shown incredible data-driven innovation, problem-solving ability and have proven real-world impact. . Our independent judges certainly had their jobs cut out for them, as they were faced with an overwhelming number of outstanding entries.
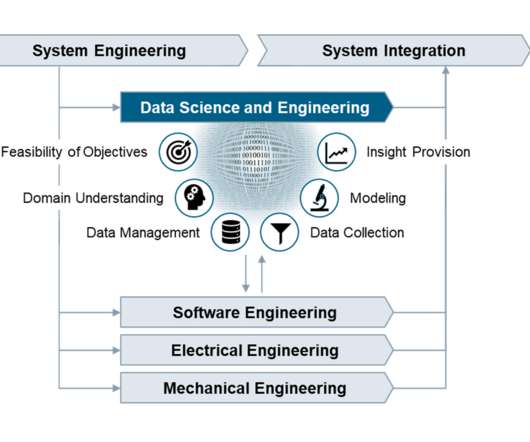
The Data Science and Engineering Process in PLM. Huge opportunities for digital products are accompanied by huge risks Digitalization is about to profoundly change the way we live and work. The increasing availability of data combined with growing storage capacities and computing power make it possible to create data-based products, services, and customer specific solutions to create insight with value for the business.
Hispanic Heritage Month not only promotes the rich culture & heritage that so many Americans share, it sheds a distinct light on colleagues & friends. Read more from our colleague, Crystal Diaz.
Supply chain redesign has become an area of critical focus as businesses try to ensure supply chains aren’t overly reliant on any one constituent part. . In Part One of our round-table discussion with Michael Ger, Managing Director of Manufacturing and Automotive, and Brent Biddulph, Global Managing Director, Retail and Consumer Goods at Cloudera they talked about the direct impact of COVID 19 on the retail and manufacturing sectors with Vijay Raja, Director of Industry & Solutions Marketing
Many businesses have built great analytics products to help with tracking the actions your users are taking in your product ( Mixpanel , Pendo , and Amplitude , to name a few). These products use an events-based data model where they track user behavior, usually client-side, so you can understand and visualize behavior like page views and button clicks.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
To keep pace with data’s lightning innovation speed, data engineers need to invest not only in the latest data modeling and analytics tools, but also technologies that can increase data accuracy and prevent broken ETL pipelines. The solution? Data observability tools , the next frontier of data engineering and a pillar of the emerging data reliability category.
If you’re responsible for data strategy in a large organization, there’s a good chance you’ve got a data mess on your hands. So what do you do with it? Read more.
Cloudera Data Platform 7.2.1 introduces fine-grained authorization for access to Azure Data Lake Storage using Apache Ranger policies. Cloudera and Microsoft have been working together closely on this integration, which greatly simplifies the security administration of access to ADLS-Gen2 cloud storage. Apache Ranger provides a centralized console to manage authorization and view audits of access to resources in a large number of services including Apache Hadoop’s HDFS, Apache Hive, Apache HBase
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
You can complete the project requirements by yourself or in collaboration with others. Feel free to ask questions in the discussion forum or on social media using the #CloudGuruChallenge hashtag! The post #CloudGuruChallenge – Event-Driven Python on AWS appeared first on A Cloud Guru.
Learn how Teradata Vantage was used for a leading Turkish bank to predict credit scores for customers in real time and to make near-immediate decisions on their loan applications.
For some, this may look like a new category at this year’s Data Impact Awards. However, the Enterprise Data Cloud category marks the evolution of what was once the Data Anywhere category. The main reason for this change is that this title better represents the move that our customers are making; away from acknowledging the ability to have data ‘anywhere’.
In Brian’s post, Building a Sync Engine , he talks about the value of using a High Water Mark to keep track of the latest bit of data you’ve imported. This approach is often a better pattern than using Limit and Offset , especially when the underlying data might be changing. In this post, I’m gong to dive even deeper into this topic, and suggest that you should be storing you High Water Marks as strings whenever possible.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
YADB (Yet Another Database Benchmark) The world has a plethora of database benchmarks, starting with the Wisconsin Benchmark which is my favorite. Firstly, that benchmark was from Dr David Dewitt, who taught me Database Internals when I was a graduate student at University of Wisconsin. Secondly, it is probably the earliest conference paper (circa 1983) that I ever read.
We’re excited to share that Monte Carlo has raised $16M in funding to pioneer the Data Reliability category. Our Series A was led by Accel , with participation from GGV Capital , and enables us to pursue our mission of accelerating the world’s adoption of data by reducing Data Downtime. Other angel investors include DJ Patil , the former Chief Data Scientist for the U.S. as well as top executives from Cloudera, eBay, Google and VMWare.
Today’s data tool challenges. A North American telecom company struggled for years trying to react quickly enough to new categories and new levels of spam texts and calls. They also did not have a good way to know when and why they would need additional capacity on their own, or any other telecom company’s networks. By enabling their event analysts to monitor and analyze events in real time, as well as directly in their data visualization tool, and also rate and give feedback to the system
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content