This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the bustling arena of database management systems, two heavyweight contenders emerge, each carrying its arsenal of features and capabilities. In one corner, we have the suave and sophisticated Microsoft SQL Server (MSSQL), donned in the elegance of enterprise-level prowess. And in the other corner the scrappy and open-source MySQL, armed with its community-driven […] The post MSSQL vs MySQL: Comparing Powerhouses of Databases appeared first on Analytics Vidhya.
In the past few days, the scope and trajectory of Instacart’s use of Snowflake has been misrepresented by some on social media. Snowflake has partnered closely with Instacart to scale up to meet the company’s massive demand growth, and then to optimize for efficiency. Optimizations are undertaken on a workload-by-workload basis, and have been extremely successful.
It’s no secret that modern organizations are doubling down on their investments in data - investments that uncover deep customer insights that provide a.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Back to school ( credits ) Hey, I'm back. I've taken an unplanned 3-week break since the last Data News, let's be honest, it was necessary! I spent a few hours working on the fancy data stack project and articles are in the works, but it was idealistic to produce quality code and content while enjoying the summer. Like wine, it takes time to get it right.
If Delta Lake implemented the commits only, I could stop exploring this transactional part after the previous article. But as for RDBMS, Delta Lake implements other ACID-related concepts. One of these are isolation levels.
130
130
Sign up to get articles personalized to your interests!
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.
If Delta Lake implemented the commits only, I could stop exploring this transactional part after the previous article. But as for RDBMS, Delta Lake implements other ACID-related concepts. One of these are isolation levels.
Summary Data persistence is one of the most challenging aspects of computer systems. In the era of the cloud most developers rely on hosted services to manage their databases, but what if you are a cloud service? In this episode Vignesh Ravichandran explains how his team at Cloudflare provides PostgreSQL as a service to their developers for low latency and high uptime services at global scale.
Data Quality Chronicles Missing data, missing mechanisms, and missing data profiling Missing Data prevents data scientists to see the entire story the data has to tell. Sometimes, even the smallest pieces of information can provide a completely unique view of the world. Photo by Ronan Furuta on Unsplash. Earlier this year, I started a piece on several data quality issues (or characteristics) that heavily compromise our machine learning models.
7 Projects Built with Generative AI • Beyond Numpy and Pandas: Unlocking the Potential of Lesser-Known Python Libraries • 5 Ways You Can Use ChatGPT’s Code Interpreter For Data Science • GPT-4: 8 Models in One; The Secret is Out
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Robinhood Markets. Inc. (Nasdaq:HOOD) today announced that it has successfully purchased all 55,273,469 shares Earlier this year, we shared that our Board of Directors authorized us to pursue purchasing most or all of the 55 million remaining Robinhood shares that Emergent Fidelity Technologies, Ltd. had bought in May 2022. The proposed share purchase underscored the confidence that the Board of Directors and management team have in our business and the success of this effort is another step in
In today’s digital age, the growth and success of an enterprise heavily rely on how it manages and leverages its data. There are multiple enterprise data platforms in the market, each offering its distinct capabilities. However, when it comes to enterprise-grade requirements certain key features are indispensable. In this blog post, we will delve into six such capabilities – comprehensive cross-cloud replication, zero copy database and schema clone, collation support, stored procedures, mu
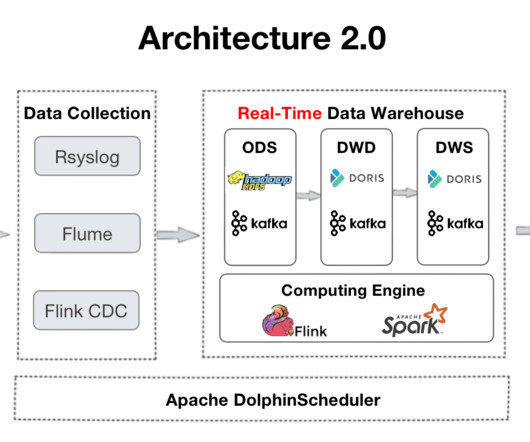
This article describes a large-scale data warehousing use case to provide reference for data engineers who are looking for log analytic solutions. It introduces the log processing architecture and real-case practice in data ingestion, storage, and queries.
With the rapid advancement of neural network-based techniques and Large Language Model (LLM) research, businesses are increasingly interested in AI applications for value.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Bitcoin and Dogecoin support is now available to all Robinhood Wallet users, and in-app Ethereum Swaps started rolling out today Since launching to the general public nearly six months ago, Robinhood Wallet has seen significant adoption globally, with hundreds of thousands of users in more than 140 countries worldwide. We are always gathering feedback, and have heard loud and clear that people want access to more coins on more chains.
Apache Iceberg continues to grow in popularity as the industry standard for open table formats. Because of its leading ecosystem of diverse adopters, contributors and commercial offerings, Iceberg helps prevent storage lock-in and eliminates the need to move or copy tables between different systems, which often translates to lower compute and storage costs for your overall data stack.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
I’m calling it now. The next battleground for analytics adoption among business users will be the productivity suite. Let’s unpack that statement by considering these two examples: You finally get your data visualization just how you want it for your presentation. Now, you take a screenshot and copy-paste it into your slide deck. You pull your dashboard data into Google Sheets so you can perform ad-hoc analysis and collaborate with various stakeholders who don’t have dashboard access.
Welcome to Snowflake’s Startup Spotlight, where we learn about startups building amazing things on Snowflake. In this edition, we’ll hear from Bobby Pinero, Co-Founder of Equals , about how his preference for doing analysis in spreadsheets fueled his drive to create a modern spreadsheet that can handle today’s data analysis needs. Tell us a little about yourself and what inspired you to build Equals.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Optimizing queries, improving runtimes, and geospatial data science applications Photo by Tamas Tuzes-Katai on Unsplash Intro: why is a spatial index useful? In doing geospatial data science work, it is very important to think about optimizing the code you are writing. How can you make datasets with hundreds of millions of rows aggregate or join faster?
Reading Time: 12 minutes Hey there, shopping savvy! Ever wished you could magically know when your favorite Amazon items go on sale? Guess what – we’ve cracked the code! Learn how to build your very own Amazon Price Tracker using Python. Imagine getting alerts right in your inbox when prices drop. Let’s dive in and make those savings dreams come true!
This post discusses the importance of media mix modeling and how it can be used to maximize the business impact of advertising. It also discusses the impact of seasonality on media advertising and how media mix modeling can be used to minimize the impact of seasonality on business outcomes.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
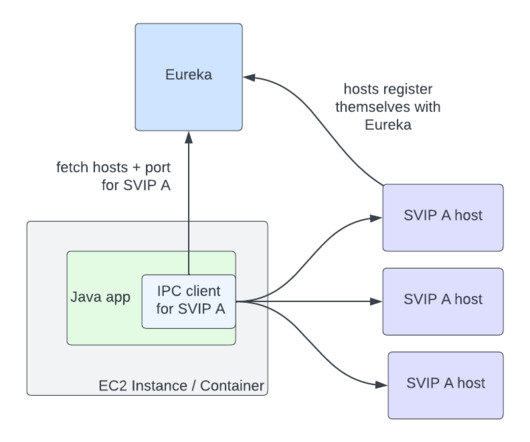
by David Vroom, James Mulcahy, Ling Yuan, Rob Gulewich In this post we discuss Netflix’s adoption of service mesh: some history, motivations, and how we worked with Kinvolk and the Envoy community on a feature that streamlines service mesh adoption in complex microservice environments: on-demand cluster discovery. A brief history of IPC at Netflix Netflix was early to the cloud, particularly for large-scale companies: we began the migration in 2008, and by 2010, Netflix streaming was fully run o
The Burtch Works 2023 Data Science & AI Professionals salary report is here, and includes insightful data such as hiring and marketplace trends, compensation changes over time, and salary data. Get your copy here.
The explosive growth of ChatGPT has influenced every industry to reexamine their artificial intelligence (AI) strategies. While healthcare & life sciences has been.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content