This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Uber delivers efficient and reliable transportation across the global marketplace, which is powered by hundreds of services, machine learning models, and tens of thousands of datasets. While growing rapidly, we’re also committed to maintaining data quality, as it can greatly … The post How Uber Achieves Operational Excellence in the Data Quality Experience appeared first on Uber Engineering Blog.
Summary Data lake architectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis. Vinoth Chandar helped to create the Hudi project while at Uber to address this challenge.
It is often difficult enough to build one application that talks to a single middleware or backend layer; e.g., a whole team of frontend engineers may build a web application […].
In our previous blog, we talked about the four paths to Cloudera Data Platform. . In-place Upgrade. Sidecar Migration. Rolling Sidecar Migration. Migrating to Cloud. If you haven’t read that yet, we invite you to take a moment and run through the scenarios in that blog. The four strategies will be relevant throughout the rest of this discussion. Today, we’ll discuss an example of how you might make this decision for a cluster using a “round of elimination” process based on our decision workflow.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
In our last post, we summarized the thinking behind the data mesh design pattern. In this post (2 of 5), we will review some of the ideas behind data mesh, take a functional look at data mesh and discuss some of the challenges of decentralized enterprise architectures like data mesh. Last we’ll explore how DataOps can be paired with data mesh to mitigate these challenges.
Summary Every organization needs to be able to use data to answer questions about their business. The trouble is that the data is usually spread across a wide and shifting array of systems, from databases to dashboards. The other challenge is that even if you do find the information you are seeking, there might not be enough context available to determine how to use it or what it means.
Today, I’m very excited to announce an all-new website dedicated to Apache Kafka®, event streaming, and associated cloud technologies. The site is called Confluent Developer, and it represents a significant […].
Today, I’m very excited to announce an all-new website dedicated to Apache Kafka®, event streaming, and associated cloud technologies. The site is called Confluent Developer, and it represents a significant […].
Recently, I worked with a large fortune 500 customer on their migration from Apache Storm to Apache NiFi. If you’re asking yourself, “Isn’t Storm for complex event processing and NiFi for simple event processing?”, you’re correct. A few customers chose a complex event engine like Apache Storm for their simple event processing, even when Apache NiFi is the more practical choice, cutting drastically down on SDLC (software development lifecycle) time.
The data mesh design pattern breaks giant, monolithic enterprise data architectures into subsystems or domains, each managed by a dedicated team. With an architecture comprised of numerous domains, enterprises need to manage order-of-operations issues, inter-domain communication, and shared services like environment creation and meta-orchestration. A DataOps superstructure provides the foundation to address the many challenges inherent in operating a group of interdependent domains.
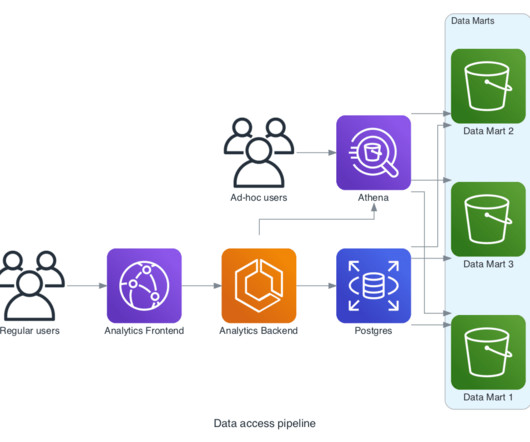
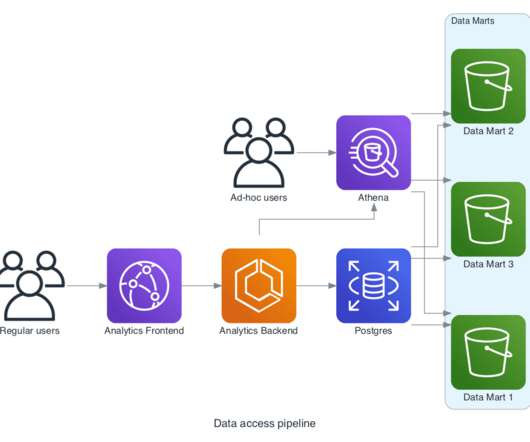
Imagine you run a candy store. Some sweets are presented on your display cases for quick access while the rest is kept in the storeroom. Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a data warehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
In Monte Carlo’s Weekly ETL (Explanations Through Lior) series, Lior Gavish, Monte Carlo’s co-founder, and CTO answers a trending question on Reddit about some of data engineering’s hottest topics. Reddit thread can be found here Reddit user /treacherous_tim asks how do you “thin slice” a data pipeline and if anyone has faced this challenge before? First, I think it’s great that data engineers are now following best practices from DevOps and software engineering, in this case, starting wit
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Minimizing Supply Chain Disruptions . January 2020 is a distant memory, but for most, the early days of the pandemic was a time that will be ingrained in memories for decades, if not generations. Over the last 18 months, supply chain issues have dominated our nightly news, social feeds and family conversations at the dinner table. Some but not all have stemmed from the pandemic. .
This is a guest article by tech writer Melanie Johnson. No matter how big or small your machine learning (ML) project might be, the overall output depends on the quality of data used to train the ML models. Data annotation plays a pivotal role in the process. And as we know it, it’s the process of marking machine-recognizable content using computer vision, or through natural language processing (NLP) in different formats, including texts, images, and videos.
Artificial Intelligence has made a significant impact on our daily lives. Every time you scroll through social media, open Spotify, or do a quick Google search, you are using an application of AI. The AI industry has expanded massively in the past few years and is predicted to grow even further, reaching around 126 billion U.S. dollars by 2025. Multinational companies like IBM, Accenture, and Apple are actively hiring AI practitioners.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Today’s organizations face rising customer expectations in a fragmented marketplace amidst stiff competition. This landscape is one that presents opportunities for a modern data-driven organization to thrive. At the nucleus of such an organization is the practice of accelerating time to insights, using data to make better business decisions at all levels and roles.
Blog A real-time approach to data lineage Written by Ross Turk on August 5, 2021 A data ecosystem that spans multiple pipelines, teams, and platforms can be overwhelming. Each dataset and job exists in a unique operational context, with interdependencies that may seem simple…until they multiply. Every tiny piece has something in common, though: when it breaks, it becomes the most important thing to everyone you know.
Gaining trust in data with extensive data quality, accuracy and anomaly checks As shared in our Data Quality Initiative post , Airbnb has embarked on a project of massive scale to ensure trustworthy data across the company. To enable employees to make faster decisions with data and provide better support for business metric monitoring, we introduced Midas , an analytical data certification process that certifies all important metrics and data sets.
The pressure to integrate analytics & machine learning into the automotive business is unrelenting. Find out what the auto industry needs to deliver on its digital promise.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Historically, maintenance has been driven by a preventative schedule. Today, preventative maintenance, where actions are performed regardless of actual condition, is giving way to Predictive, or Condition-Based, maintenance, where actions are based on actual, real-time insights into operating conditions. While both are far superior to traditional Corrective maintenance (action only after a piece of equipment fails), Predictive is by far the most effective.
August is a good time to start new things – some people are on vacation and have more spare time to read than usual, while others are back and looking for a quick refresher on what’s new in data engineering. We’re launching this Annotated series to find interesting and useful content on different topics around data engineering, such as news, technical articles, tools, future conferences, and more.
Photo by Chris Kursikowski on Unsplash By: Huan Nguyen Eight months ago at Afterpay, we kicked off our “app rewrite” project in which we are rewriting our React Native apps in native Android and iOS. As part of this project, we are not only aiming at building an app, we are also aiming to build a strong and scalable mobile platform which supports our fast-growing business.
The mission of many data teams is a very simple one. They seek to use data to help the business take smarter actions. The input is raw data from everywhere that touches the business. This includes many external sources, its own products, and various systems used for marketing, sales, and operations. The outputs often take the form of analysis, insights, models, and other usable mediums.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Author Chris J. Preimesberger is Editor Emeritus of eWEEK. With hackers now working overtime to expose business data or implant ransomware processes, data security is largely IT managers’ top priority. And if data security tops IT concerns, data governance should be their second priority. Not only is it critical to protect data, but data governance is also the foundation for data-driven businesses and maximizing value from data analytics.
August is a good time to start new things – some people are on vacation and have more spare time to read than usual, while others are back and looking for a quick refresher on what’s new in data engineering. We’re launching this Annotated series to find interesting and useful content on different topics around data engineering, such as news, technical articles, tools, future conferences, and more.
Cost income ratios in traditional banks remain untenably high. What’s required is a thorough analysis of the overall operating model to improve both sides of the cost income equation.
“The world’s most valuable resource is no longer oil, but data.” There are those rare opportunities in your career where you are at the intersection of multiple macro and micro trends. I’m thrilled to join the team at Rockset that is defining the category of Real-Time Analytics. My Path to Rockset I've been fortunate to have experienced and embraced hyper-growth companies throughout my career.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
In this series, we highlight the critical steps your business must follow when building a data incident management workflow , including incident detection, response, root cause analysis & resolution (RCA), and a blameless post-mortem. Let’s start with incident detection and alerting, your first line of defense against data downtime and broken data pipelines.
In my last blog post I explained how we defined our 3-year technical vision for the company. One of the key pillars of this vision is shifting from a model where we used the same tool for every job (mostly a combination of Python + Django + MySQL), to the right tool(s) for each job. … Continue reading "Writing our Golden Path" The post Writing our Golden Path appeared first on Engineering Blog.
A Supply Chain Data Hub provides a model-driven set of data objects with maximum data reuse, minimum technical debt, lower cost to build and faster time to market. Find out more.
Organizations that depend on data for their success and survival need robust, scalable data architecture, typically employing a data warehouse for analytics needs. Snowflake is often their cloud-native data warehouse of choice. With Snowflake, organizations get the simplicity of data management with the power of scaled-out data and distributed processing.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content