This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Setup Problems with a single large update Updating in batches Conclusion Further reading Introduction When updating a large number of records in an OLTP database, such as MySQL, you have to be mindful about locking the records. If those records are locked, they will not be editable(update or delete) by other transactions on your database.
COVID-19 vaccines from various manufacturers are being approved by more countries, but that doesn’t mean that they will be available at your local pharmacy or mass vaccination centers anytime soon. Creating, scaling-up and manufacturing the vaccine is just the first step, now the world needs to coordinate an incredible and complex supply chain system to deliver more vaccines to more places than ever before.
Summary Collecting and processing metrics for monitoring use cases is an interesting data problem. It is eminently possible to generate millions or billions of data points per second, the information needs to be propagated to a central location, processed, and analyzed in timeframes on the order of milliseconds or single-digit seconds, and the consumers of the data need to be able to query the information quickly and flexibly.
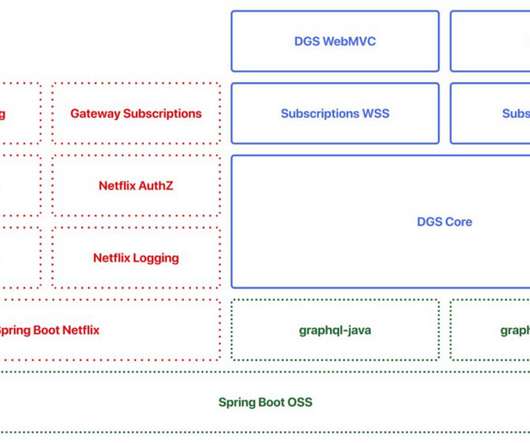
By Paul Bakker and Kavitha Srinivasan , Images by David Simmer , Edited by Greg Burrell Netflix has developed a Domain Graph Service (DGS) framework and it is now open source. The DGS framework simplifies the implementation of GraphQL, both for standalone and federated GraphQL services. Our framework is battle-hardened by our use at scale. By open-sourcing the project, we hope to contribute to the Java and GraphQL communities and learn from and collaborate with everyone who will be using the fra
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Every DataOps initiative starts with a pilot project. How do you choose a project that matters to people? DataOps addresses a broad set of use cases because it applies workflow process automation to the end-to-end data-analytics lifecycle. DataOps reduces errors, shortens cycle time, eliminates unplanned work, increases innovation, improves teamwork, and more.
Since I first started using Apache Kafka® eight years ago, I went from being a student who had just heard about event streaming to contributing to the transformational, company-wide event […].
Financial services institutions need the ability to analyze and act on massive volumes of data from diverse sources in order to monitor, model, and manage risk across the enterprise. They need a comprehensive data and analytics platform to model risk exposures on-demand. Cloudera is that platform. I am pleased to announce that Cloudera was just named the Risk Data Repository and Data Management Product of the Year in the Risk Markets Technology Awards 2021. .
Financial services institutions need the ability to analyze and act on massive volumes of data from diverse sources in order to monitor, model, and manage risk across the enterprise. They need a comprehensive data and analytics platform to model risk exposures on-demand. Cloudera is that platform. I am pleased to announce that Cloudera was just named the Risk Data Repository and Data Management Product of the Year in the Risk Markets Technology Awards 2021. .
Read how a principal data scientist at Teradata leveraged his cross-industry expertise to build an algorithm to help doctors better understand & fight COVID-19.
This blog builds on earlier posts that defined Kitchens and showed how they map to technical environments. We’ve also discussed how toolchains are segmented to support multiple kitchens. DataOps automates the source code integration, release, and deployment workflows related to analytics development. To use software dev terminology, DataOps supports continuous integration, continuous delivery, and continuous deployment.
How do you process IoT data, change data capture (CDC) data, or streaming data from sensors, applications, and sources in real time? Apache Kafka® and Azure Databricks are widely adopted […].
In the previous posts in this series, we have discussed Kerberos , LDAP and PAM authentication for Kafka. In this post we will look into how to configure a Kafka cluster and client to use a TLS client authentication. The examples shown here will highlight the authentication-related properties in bold font to differentiate them from other required security properties, as in the example below.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Data & analytics now allow rapid response to changing preferences and emerging value propositions to seed future growth in the digital payments area. Read more.
For today’s data engineering teams, the demand for real-time, accurate data has never been higher, yet data downtime is an all-too-common reality. So, how can we break this vicious cycle and achieve reliable data? Just like our software engineering counterparts 20 years ago, data teams in the early 2020s are facing a significant challenge: reliability.
Today, we’re delighted to launch the Confluent Community Forum. Built on Discourse, a platform many developers will already be familiar with, this new forum is a place for the community […].
The 2020 murders of Ahmad Aubrey, Breonna Taylor, and George Floyd within a three month span of one another brought discussions about racial-social justice to dining rooms and boardrooms alike; and just like with the African-American catalysts before them, their tragedies reopened the door to larger discussions around economic, social, and civil rights.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
We’re excited to share that Silectis has released a new suite of automated data lineage features within Magpie, the end-to-end data engineering platform. These features equip users with knowledge of where data originates, when it was published, and who it was published by. This additional context provides users the transparency and accountability necessary to trust their data and react to inevitable data quality issues.
OpenLineage is an API for collecting data lineage and metadata at runtime. While initiated by Datakin, the company behind Marquez, it was developed with the aim to create an open standard. As Datakin’s CTO Julien Le Dem explained in a blog post announcing the launch , OpenLineage is meant to answer the industry-wide need for data lineage, while making sure efforts in that direction aren’t fragmented or duplicated.
The Ripple Data Engineering team is expanding, which means higher frequency changes to our data pipeline source code. This means we need to build better, more configurable and more collaborative tooling that prevents code collisions and enforces software engineering best practices. To ensure the quality of incoming features, the team sought to create a pipeline that automatically validated those features, build them to verify their interoperability with existing features and GitLab, and al
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Scala 3 comes with lots of new features: in this episode, we dive into match types, a powerful tool for pattern matching on types and more accurate type checking
From the visual search for improved product discoverability to face recognition on social networks- image classification is fueling a visual revolution online and has taken the world by storm. Image classification , a subfield of computer vision helps in processing and classifying objects based on trained algorithms. Image Classification had its Eureka moment back in 2012 when Alexnet won the ImageNet challenge and since then there has been an exponential growth in the field.
Is it ever too late to follow your dream and start a new career? Well, I was 30 and had been working for Zalando for more than 4 years when I decided to change my career path for the second time. I made the decision a year ago, joined my new team in April 2020, and I didn't regret it for a single day. Since that transition, a lot of people approached me with questions and asked me for advice.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
If you are a business person wondering why you should invest in DevOps / MLOps, this is your guide in terms of real live money. We'll try to keep this as non-technical as possible. The technical terms we mention are because they are ABSOLUTELY essential and should have budget allocated to them. Be sure to read to the end for instructions on how to execute an analysis of expected gains from infrastructure changes required for MLOps in your organisation.
Introduction Testing is widely accepted practice in software industry. I am an iOS Engineer and have been writing tests, like most of us. The way I approach testing changed radically a few years back. And I have used and shared this new technique for a few years within Zalando and outside. In this post, I will explain what is wrong with most test cases and how to apply randomized input to improve tests.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content