This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data engineering is the field of study that deals with the design, construction, deployment, and maintenance of data processing systems. The goal of this domain is to collect, store, and process data efficiently and efficiently so that it can be used to support business decisions and power data-driven applications. This includes designing and implementing […] The post Most Essential 2023 Interview Questions on Data Engineering appeared first on Analytics Vidhya.
Hmm … data types. We all know they are important, but we don’t take them very seriously. I mean we know the difference between boolean, string, and integers, those are easy to get right. But we all get sloppy, sometimes we got the string and varchar route because we don’t spend enough time on the […] The post Data Types in Delta Lake + Spark.
Summary This podcast started almost exactly six years ago, and the technology landscape was much different than it is now. In that time there have been a number of generational shifts in how data engineering is done. In this episode I reflect on some of the major themes and take a brief look forward at some of the upcoming changes. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Your host is Tobias Macey and today I'm reflecting on the m
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Introduction A design pattern is simply a repeatable solution for problems that keep on reoccurring. The pattern is not an actual code but a template that can be used to solve problems in different situations. Especially while working with databases, it is often considered a good practice to follow a design pattern. This ensures easy […] The post What are Data Access Object and Data Transfer Object in Python?
As I started to use Rust on and off, more out of curiosity than anything, I discovered some specs of gold buried down in the depths. Some of the things I’m going to talk about, well … all of it, is probably fairly obvious to most Rust folk, but it’s enjoyable to learn what new […] The post Ownership and Borrowing in Rust – Data Engineering Gold Mine. appeared first on Confessions of a Data Guy.
Facebook for iOS (FBiOS) is the oldest mobile codebase at Meta. Since the app was rewritten in 2012 , it has been worked on by thousands of engineers and shipped to billions of users, and it can support hundreds of engineers iterating on it at a time. After years of iteration , the Facebook codebase does not resemble a typical iOS codebase: It’s full of C++, Objective-C(++), and Swift.
Introduction Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a data warehouse in the cloud. Redshift uses columnar storage techniques to store data efficiently and supports data warehousing workloads intelligence, reporting, and analytics. It allows users to perform complex queries […] The post Top 6 Amazon Redshift Interview Questions appeared first on Analytics Vidhya.
We are introduced to new discoveries and technologies every day, and one of the best and most popular inventions today is artificial intelligence (AI) and its tools. One of them is Chat GPT, a conversational model of AI that is a powerful chatbot that answers follow-up questions and writes code for the users. The day it was launched, everybody was going gaga over the new technology and the remarkable uses of this AI-powered chatbot.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
A lot has changed since the initial launch of our basemap in late 2020. We’re Meta now, but our mission remains the same: Giving people the power to build community and bring the world closer together. Across Meta, our family of applications (Facebook, Instagram, WhatsApp, among others) are using our basemap to connect people through functions like status updates, location sharing, and location-based searching.
Introduction While working with multiple projects, there are chances of issues with versions of packages in python; for example, a project needs a new version of a package, and another requires a different version. Sometimes the python version itself changes from project to project. Managing these different python versions and different versions of packages is […] The post Isolated Python Environments using Docker appeared first on Analytics Vidhya.
Compaction is also a feature present in Apache Iceberg. However, it works a little bit differently than for Delta Lake presented last time. Why? Let's see in this new blog post!
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
It would be almost impossible to build a scalable backend without a scalable datastore. DoorDash’s expansion from food delivery into new verticals like convenience and grocery introduced a number of new business challenges that would need to be supported by our technical stack. This business expansion not only increased the number of integrated merchants dramatically but also exponentially increased the number of menu items, as stores have much larger and more complicated inventories than typica
source: svitla.com Introduction Before jumping to the data warehouse interview questions, let’s first understand the overview of a data warehouse. A data warehouse is a system used for collecting and managing large amounts of data from various sources, such as transactional systems, log files, and external data sources. The data is then organized and structured […] The post Data Warehouse Interview Questions appeared first on Analytics Vidhya.
In the aftermath of the 2008 financial crash, service providers have been subject to increasing rules & requirements. To what extent has this climate held back advances in data analytics?
KDnuggets and its partners have just released a Spend & Trends survey to provide you the opportunity to benchmark with your peers on how folks are spending and the mindsets around current trends.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Advances in Natural Language Processing (NLP) have unlocked unprecedented opportunities for businesses to get value out of their text data. Natural Language Processing.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary. Data engineers specialize in building and maintaining these data pipelines that underpin the analytics ecosystem.
Two years ago, we announced our Databricks partnership —including the launch of ThoughtSpot for Databricks, which gives joint customers the ability to run ThoughtSpot search queries directly on the Databricks Lakehouse without the need to move any data. Since then, we’ve empowered teams at companies like Johnson & Johnson, NASDAQ, and Flyr to safely self-serve business-critical insights on governed and reliable data.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Today, we're excited to announce that Databricks has expanded Brickbuilder Solutions by collaborating with key partners in Europe, the Middle East, and Africa.
Introduction In this technical era, Big Data is proven as revolutionary as it is growing unexpectedly. According to the survey reports, around 90% of the present data was generated only in the past two years. Big data is nothing but the vast volume of datasets measured in terabytes or petabytes or even more. Big data […] The post A Beginner’s Guide to the Basics of Big Data and Hadoop appeared first on Analytics Vidhya.
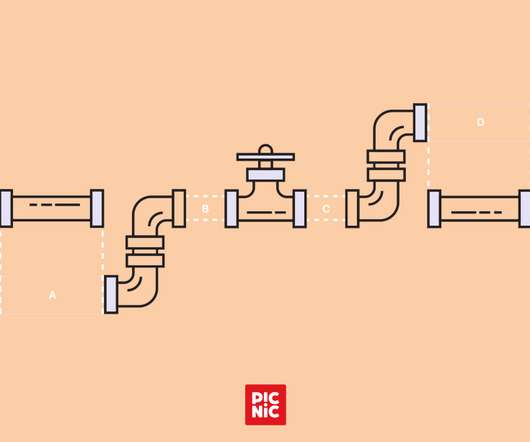
Delivering the right events at low latency and with a high volume is critical to Picnic’s system architecture. In our previous blog, Dima Kalashnikov explained how we configure our Internal services pipeline in the Analytics Platform. In this post, we will explain how our team automates the creation of new data pipeline deployments. The step towards automation was an important improvement for us, as the previous setup was manual, slow, and error-prone.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Introduction The February installment of the webinar series is now open! It’s a farewell time to your quest for finding the ideal data science learning platform, as Analytics Vidhya has arrived. Explore your ultimate data science destination where the emphasis is on supporting the community and fostering professional development. Attend expert-led DataHour sessions to boost […] The post February DataHour: Enhance Your Skills with Expert Sessions appeared first on Analytics Vidhya.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content