This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction NumPy is an open-source library in python and a must-learn if you want to enter the data science ecosystem. It is the library underpinning other important libraries such as Pandas, matplotlib, Scipy, scikit-learn, etc. One of the reasons this library is so foundational is because of its array of programming capabilities. Array programming, or […] The post Advanced NumPy: Broadcasting and Strides appeared first on Analytics Vidhya.
Sponsored Post Groundbreaking large language model research from OpenAI, Google, Amazon, and others have transformed expectations of machine-generated software.
Summary The ecosystem for data professionals has matured to the point that there are a large and growing number of distinct roles. With the scope and importance of data steadily increasing it is important for organizations to ensure that everyone is aligned and operating in a positive environment. To help facilitate the nascent conversation about what constitutes an effective and productive data culture, the team at Data Council have dedicated an entire conference track to the subject.
Topiary aims to be a universal formatter engine within the Tree-sitter ecosystem. Named after the art of clipping or trimming trees into fantastic shapes, it is designed for formatter authors and formatter users: Authors can create a formatter for a language without having to write their own formatting engine, or even their own parser. Users benefit from uniform, comparable code style, across multiple languages, with the convenience of a single formatter tool.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner. S3 provides a simple web interface for uploading and downloading data and a powerful set of APIs for developers to integrate S3.
Summary With the rise of the web and digital business came the need to understand how customers are interacting with the products and services that are being sold. Product analytics has grown into its own category and brought with it several services with generational differences in how they approach the problem. NetSpring is a warehouse-native product analytics service that allows you to gain powerful insights into your customers and their needs by combining your event streams with the rest of
Summary With the rise of the web and digital business came the need to understand how customers are interacting with the products and services that are being sold. Product analytics has grown into its own category and brought with it several services with generational differences in how they approach the problem. NetSpring is a warehouse-native product analytics service that allows you to gain powerful insights into your customers and their needs by combining your event streams with the rest of
There is always a gap between a disruption in the data engineering industry and its integration on the cloud. It was not different for table file formats which have started gaining interest on AWS, Azure, GCP recently.
Introduction Apache Cassandra is a NoSQL database management system that is open-source and distributed. It is meant to handle massive volumes of data across many commodity servers while maintaining high availability with no single point of failure. Facebook created Cassandra, which ultimately became an Apache Software Foundation project. It is well-known for its rapid write […] The post Top 6 Cassandra Interview Questions appeared first on Analytics Vidhya.
Data manipulation and analysis can be challenging and involve working with large datasets. Thankfully, a widely used Python library known as Pandas has become the go-to tool for processing and manipulating data. Pandas recently got an update, which is version 2.0. This article takes a closer look at what Pandas is, its success, and what the new version brings, including its ecosystem around Arrow, Polars, and DuckDB.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Introduction Microsoft Azure HDInsight(or Microsoft HDFS) is a cloud-based Hadoop Distributed File System version. A distributed file system runs on commodity hardware and manages massive data collections. It is a fully managed cloud-based environment for analyzing and processing enormous volumes of data. HDInsight works seamlessly with the Hadoop ecosystem, which includes technologies like MapReduce, Hive, […] The post Top 6 Microsoft HDFS Interview Questions appeared first on Analytics V
Between January 24, 2023, and February 28, 2023, I ran a survey to get more data for my latest book Data Teams , and to update my previous survey from late 2020. Overall, we had 81 respondents. This survey was designed to get information about how management uses data teams, the value they’re creating, and how they’re creating it. The survey asked about the best and worst practices that teams are using or experiencing.
Formula 1 is back (trying to jinx before it happens) (yes there is no link with the data news) ( credits ) Hello you, I hope this new Data News finds you well. After last week question about your consideration of a paying subscription I got a few feedbacks and it helped me a lot realise how you see the newsletter and what it means for a you. So thank you for that.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
The Biggest Data Science Blogathon is now live! “Knowledge is power. Sharing knowledge is the key to unlocking that power.”― Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon. This 30th edition of the Data Science Blogathon is particularly very important because we are celebrating the women in […] The post Data Science Blogathon 30th Edition- Women in Data Science appeared first on Analytics Vidhya.
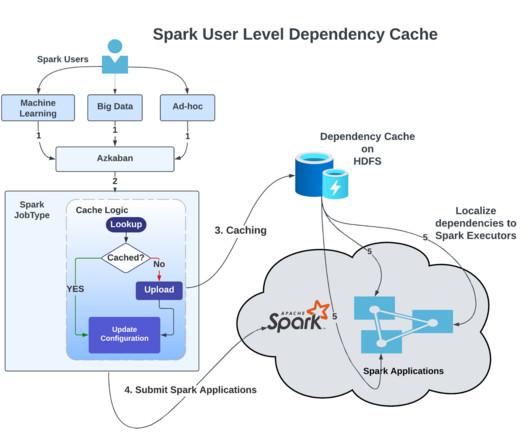
Co-authors: Shu Wang , Biao He , and Minchu Yang At LinkedIn, Apache Spark is our primary compute engine for offline data analytics such as data warehousing, data science, machine learning, A/B testing, and metrics reporting. We execute nearly 100,000 Spark applications daily in our Apache Hadoop YARN (more on how we scaled YARN clusters here ). These applications rely heavily on dependencies ( JAR files ) for their computation needs.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Introduction DataHour sessions are an excellent opportunity for aspiring individuals looking to launch a career in the data-tech industry, including students and freshers. Current professionals seeking to transition into the data-tech domain or data science professionals seeking to enhance their career growth and development can also benefit from these sessions.
While most engineering tooling at DoorDash is focused on making safe incremental improvements to existing systems, in part by testing in production (learn more about our end-to-end testing strategy ), this is not always the best approach when launching an entirely new business line. Building from scratch often requires faster prototyping and customer validation than incremental improvements to an existing system.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software. Instead, it provides high-performance analytics, flexibility, and cost-effective scaling.
by Varun Sekhri , Meenakshi Jindal , Burak Bacioglu Introduction At Netflix, to promote and recommend the content to users in the best possible way there are many Media Algorithm teams which work hand in hand with content creators and editors. Several of these algorithms aim to improve different manual workflows so that we show the personalized promotional image, trailer or the show to the user.
Today we’re excited to announce ThoughtSpot Sage , our new search experience that combines the power of GPT’s natural language processing and generative AI capabilities with the accuracy and security of our patented self-service analytics platform. With this new integration, data teams will be able to exponentially increase their impact across an organization as business users self-serve personalized, actionable, and trustworthy insights like never before.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Interested in learning how ChatGPT and other AI chatbots work under the hood? Look no further. Check out these free courses and resources on large language models from Stanford, Princeton, ETH, and more.
Introduction Amazon Athena is an interactive query tool supplied by Amazon Web Services (AWS) that allows you to use conventional SQL queries to evaluate data stored in Amazon S3. Athena is a serverless service. Thus there are no servers to operate, and you pay for the queries you perform. Athena is built on Presto, an open-source […] The post Top 6 Amazon Athena Interview Questions appeared first on Analytics Vidhya.
By Burak Bacioglu , Meenakshi Jindal Asset Management at Netflix At Netflix, all of our digital media assets (images, videos, text, etc.) are stored in secure storage layers. We built an asset management platform (AMP), codenamed Amsterdam , in order to easily organize and manage the metadata, schema, relations and permissions of these assets. It is also responsible for asset discovery, validation, sharing, and for triggering workflows.
Uber’s configuration platform team talks about how they consolidated the infrastructure for multiple configuration systems into a unified, next-gen distribution platform, reducing CPU usage by an order of magnitude.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content