How to Get Hired as Data Scientist in the GPT-4 Era
KDnuggets
APRIL 19, 2023
We will be focusing on statistics, core data science concepts, NLP, prompt engineering, data science portfolio, interview preparation, and AIOps.

KDnuggets
APRIL 19, 2023
We will be focusing on statistics, core data science concepts, NLP, prompt engineering, data science portfolio, interview preparation, and AIOps.

Knowledge Hut
APRIL 19, 2023
The process of gathering and compiling data from various sources is known as data Aggregation. Businesses and groups gather enormous amounts of data from a variety of sources, including social media, customer databases, transactional systems, and many more. in today's data-driven world, Consolidating, processing, and making meaning of this data in order to derive insights that can guide decision-making is the difficult part.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

The Pragmatic Engineer
APRIL 19, 2023
When I think back on the software engineers I looked up to, they all shared this trait where they never took anything at face value. They regularly questioned statements that did not make sense to them, no matter how small the topic was: even if it involved admitting they did not understand a concept. After a while, I started adopting this approach.

Analytics Vidhya
APRIL 17, 2023
Are you a data enthusiast looking to break into the world of analytics? The field of data science and analytics is booming, with exciting career opportunities for those with the right skills and expertise. But with so many job titles and buzzwords floating around, figuring out which path to pursue can be challenging. So, let’s […] The post Data Scientist vs Data Analyst: Which is a Better Career Option to Pursue in 2023?

Advertisement
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate

KDnuggets
APRIL 20, 2023
CTGAN and other generative AI models can create synthetic tabular data for ML training, data augmentation, testing, privacy-preserving sharing, and more.

Data Engineering Podcast
APRIL 16, 2023
Summary Business intellingence has been chasing the promise of self-serve data for decades. As the capabilities of these systems has improved and become more accessible, the target of what self-serve means changes. With the availability of AI powered by large language models combined with the evolution of semantic layers, the team at Zenlytic have taken aim at this problem again.
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

|

Analytics Vidhya
APRIL 17, 2023
Introduction Well, hold onto your seats because the DataHour sessions are here to revolutionize how you learn about data-driven technologies. If you’re tired of boring, dry sessions that put you to sleep faster than a lullaby, you’re in for a treat. These sessions will cover everything from conversational intelligence to people analytics covering topics like […] The post Ace Your Data Science Skills with DataHour Sessions appeared first on Analytics Vidhya.

KDnuggets
APRIL 18, 2023
In short, generative AI — and the prompts that power them — are everywhere. But beyond the basics, what do you really know about either? Perhaps you would find a concise, focused ebook on the topics useful.

Confessions of a Data Guy
APRIL 16, 2023
I was wondering the other day … since Polars now has a SQL context and is getting more popular by the day, do I need DuckDB anymore? These two tools are hot. Very hot. I haven’t seen this since Databricks and Snowflake first came out and started throwing mud at each other. You might think […] The post DuckDB vs Polars for Data Engineering. appeared first on Confessions of a Data Guy.

dbt Developer Hub
APRIL 19, 2023
Dimensional modeling is one of many data modeling techniques that are used by data practitioners to organize and present data for analytics. Other data modeling techniques include Data Vault (DV), Third Normal Form (3NF), and One Big Table (OBT) to name a few. Data modeling techniques on a normalization vs denormalization scale While the relevancy of dimensional modeling has been debated by data practitioners , it is still one of the most widely adopted data modeling technique for analytics.

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Analytics Vidhya
APRIL 17, 2023
Introduction Kedro is an open-source Python framework for creating reproducible, maintainable, and modular data science code. It uses best practices of software engineering to build production-ready data science pipelines. This article will give you a glimpse of Kedro framework using news classification tasks. The advantages of using Kedro are: Machine Learning Engineering: It borrows concepts from […] The post Walkthrough of Kedro Framework Using News Classification Task appeared first on

KDnuggets
APRIL 18, 2023
Natural Language Processing is one of the hottest areas of research. While NLP tasks may seem a bit complicated at first, they can be made easier by using the right tools. This article covers a list of the top 6 NLP Libraries that can save you time and effort.

Snowflake
APRIL 20, 2023
Generative AI and large language models (LLMs) are revolutionizing many aspects of both developer and non-coder productivity with automation of repetitive tasks and fast generation of insights from large amounts of data. Snowflake users are already taking advantage of LLMs to build really cool apps with integrations to web-hosted LLM APIs using external functions , and using Streamlit as an interactive front end for LLM-powered apps such as AI plagiarism detection , AI assistant , and MathGPT.

Christophe Blefari
APRIL 21, 2023
If this picture had been generated with AI it would have been boring ( credits ) Dear readers, I hope you're doing good. We are close to the second anniversary of the newsletter. Which is crazy. Retrospectively it means that I've written 900 words on average every week for the last 102 weeks. When you look at the first edition we came a long way—lmao.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.

Waitingforcode
APRIL 20, 2023
After a 2-years break, I had a chance to speak again, this time at the Big Data Warsaw 2023. Even though I couldn't be at Warsaw that day, I enjoyed the experience and also watched other sessions available through the conference platform.

KDnuggets
APRIL 17, 2023
Learn the basics of Web Scraping and its Python implementation. Also, get to know about the various methods of Beautiful Soup library.

Confessions of a Data Guy
APRIL 15, 2023
PySpark. One of those things to hate and love, well … kinda hard not to love. PySpark is the abstraction that lets a bazillion Data Engineers forget about that blight Scala and cuddle their wonderfully soft and ever-kind Python code, while choking down gobs of data like some Harkonnen glutton. But, that comes with […] The post The Dog Days of PySpark appeared first on Confessions of a Data Guy.

ArcGIS
APRIL 17, 2023
The Generate Tessellation tool now includes H3 Hexagons, a hexagonal hierarchical spatial indexing system.

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri

Waitingforcode
APRIL 15, 2023
In my long - but not long enough! - journey with Apache Spark I've met the "checkpointing" world in the context of Structured Streaming mostly. But this term also applies to other modules including Apache Spark SQL, so batch processing!

KDnuggets
APRIL 17, 2023
ChatGPT for Data Science Cheat Sheet • 4 Ways to Generate Passive Income Using ChatGPT • GPT-4: Everything You Need To Know • Automate the Boring Stuff with GPT-4 and Python • Simpson's Paradox and its Implications in Data Science • ChatGPT vs Google Bard: A Comparison of the Technical Differences • OpenChatKit: Open-Source ChatGPT Alternative • How to Use ChatGPT to Improve Your Data Science Skills

LinkedIn Engineering
APRIL 20, 2023
On the LinkedIn platform, members from around the world share their knowledge, perspectives, and discuss topics important to them. Our goal at LinkedIn is to enable them to do so in a safe, trusted, and professional environment. We’ve previously discussed the various systems used to create a safe and trusted experience for our members and how we keep the LinkedIn Feed relevant for our members on LinkedIn.

Engineering at Meta
APRIL 17, 2023
What the research is: Millisampler is one of Meta’s latest characterization tools and allows us to observe, characterize, and debug network performance at high-granularity timescales efficiently. This lightweight network traffic characterization tool for continual monitoring operates at fine, configurable timescales. It collects time series of ingress and egress traffic volumes, number of active flows, incoming ECN marks, and ingress and egress retransmissions.

Advertisement
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you

databricks
APRIL 20, 2023
Background and Motives Deep Learning algorithms are complex and time consuming to train, but are quickly moving from the lab to production because.

KDnuggets
APRIL 21, 2023
Dolly 2.0 was trained on a human-generated dataset of prompts and responses. The training methodology is similar to InstructGPT but with a claimed higher accuracy and lower training costs of less than $30.

Lyft Engineering
APRIL 21, 2023
Building a large scale unsupervised model anomaly detection system — Part 1 Distributed Profiling of Model Inference Logs By Anindya Saha , Han Wang , Rajeev Prabhakar Introduction LyftLearn is Lyft’s ML Platform. It is a machine learning infrastructure built on top of Kubernetes that powers diverse applications such as dispatch, pricing, ETAs, fraud detection, and support.

Rockset
APRIL 18, 2023
We’re excited to introduce vector search on Rockset to power fast and efficient search experiences, personalization engines, fraud detection systems and more. To highlight these new capabilities, we built a search demo using OpenAI to create embeddings for Amazon product descriptions and Rockset to generate relevant search results. In the demo, you’ll see how Rockset delivers search results in 15 milliseconds over thousands of documents.

Speaker: Tamara Fingerlin, Developer Advocate
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!

databricks
APRIL 17, 2023
With all the incredible progress being made in the space of Large Language Models, customers have asked us how they can enable their.

KDnuggets
APRIL 19, 2023
Use simple UI to experiment with various renowned large language models.
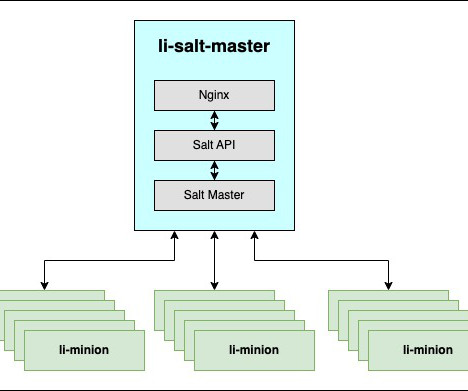
LinkedIn Engineering
APRIL 18, 2023
At LinkedIn, site engineers like to automate operational tasks at various infrastructure layers to minimize manual interventions, which can scale well and be easy to operate. Certain automations are performed via onDemand job executions. LinkedIn engineers have been using Salt , a Python-based, open source software, for executing tasks on hosts for more than a decade now, due to its high performance and pluggability.

Towards Data Science
APRIL 17, 2023
Data teams are more important than ever before — but they need to get closer to the business. Here’s how we can right the ship. Image courtesy of Daniel Lerman on Unsplash. Over the past decade, data teams have been simultaneously underwater and riding a wave. We’ve been building modern data stacks, migrating to Snowflake like our lives depended on it, investing in headless BI, and growing our teams faster than you can say reverse ETL.

Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m

Expert insights. Personalized for you.






Let's personalize your content