This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Starting new data engineering projects can be challenging. Data engineers can get stuck on finding the right data for their data engineering project or picking the right tools. And many of my Youtube followers agree as they confirmed in a recent poll that starting a new data engineering project was difficult. Here were the key… Read more The post 7 Data Engineering Projects To Put On Your Resume appeared first on Seattle Data Guy.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and high-growth startups through the lens of engineering managers and senior engineers. In this issue, we cover one out of six topics from today’s subscriber-only The Scoop issue. To get full articles twice a week, subscribe here.
Introduction Join us in this interview as Sumeet shares his background, journey as a former Data Scientist to a software engineer, and learn the captivating aspects of his current job. He provides insights into the future of data science and software engineering and offers valuable advice for career transitioners. Let’s dive into our conversation with […] The post Conversation with Sumeet, Software Engineer at Natwest Group appeared first on Analytics Vidhya.
Summary Batch vs. streaming is a long running debate in the world of data integration and transformation. Proponents of the streaming paradigm argue that stream processing engines can easily handle batched workloads, but the reverse isn't true. The batch world has been the default for years because of the complexities of running a reliable streaming system at scale.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
As modern companies rely on data, establishing dependable, effective solutions for maintaining that data is a top task for each organization. The complexity of information storage technologies increases exponentially with the growth of data. From physical hard drives to cloud computing, unravel the captivating world of data storage and recognize its ever-evolving role in our […] The post What is Data Storage and How is it Used?
As modern companies rely on data, establishing dependable, effective solutions for maintaining that data is a top task for each organization. The complexity of information storage technologies increases exponentially with the growth of data. From physical hard drives to cloud computing, unravel the captivating world of data storage and recognize its ever-evolving role in our […] The post What is Data Storage and How is it Used?
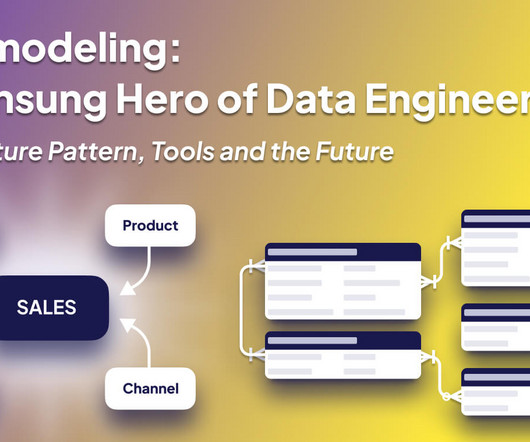
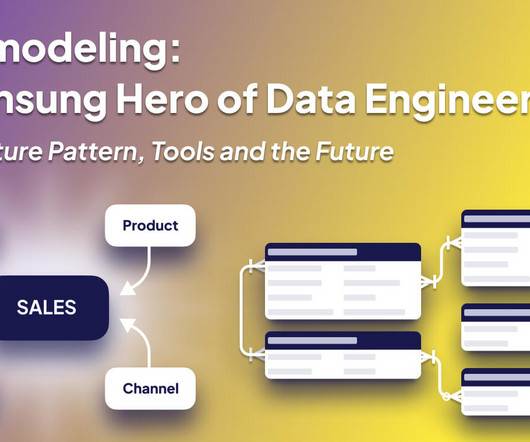
Welcome to the third and final installment of our series “Data Modeling: The Unsung Hero of Data Engineering.” If you’ve journeyed with us from Part 1, where we dove into the importance and history of data modeling, or joined us in Part 2 to explore various approaches and techniques, I’m delighted you’ve stuck around. In this third part, we’ll delve into data architecture patterns and their influence on data modeling.
When it's all said and done, and AI has been universally recognized as our rightful overlords, the idea of data science as a standalone field will have been but a blip on our collective radar.
Apache Spark is infamous for its correctness issue for chained stateful operations. Fortunately things get improved in each release. The most recent one, the 3.4.0, also got some important changes on that field!
Tweagers have an engineering mantra — Functional. Typed. Immutable. — that begets composable software which can be reasoned about and avails itself to static analysis. These are all “good things” for building robust software, which inevitably lead us to using languages such as Haskell, OCaml and Rust. However, it would be remiss of us to snub languages that don’t enforce the same disciplines, but are nonetheless popular choices in industry.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Welcome to the third and final installment of our series “Data Modeling: The Unsung Hero of Data Engineering.” If you’ve journeyed with us from Part 1, where we dove into the importance and history of data modeling, or joined us in Part 2 to explore various approaches and techniques, I’m delighted you’ve stuck around. In this third part, we’ll delve into data architecture patterns and their influence on data modeling.
Special thanks to EY's Mario Schlener, Wissem Bouraoui and Tarek Elguebaly for their support throughout this journey and their contributions to this blog.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
What is data freshness and why is it important? Data freshness, sometimes referred to as data timeliness, is the frequency in which data is updated for consumption. It is an important dimension of data quality and a pillar of data observability because recently refreshed data is more accurate, and thus more valuable. Since it is impractical and expensive to have all data refreshed on a near real-time basis, data engineers ingest and process most analytical data in batches with pipelines designed
The blog focuses on GPT models, providing an in-depth understanding and analysis. It explains the three main components of GPT models: generative, pre-trained, and transformers.
Want to build your own LLM-enabled bot? Download our end-to-end solution accelerator here. Business leaders are universally excited for the potential of large.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Representation online matters: practical end-to-end diversification in search and recommender systems Bhawna Juneja | Senior Machine Learning Engineer; Pedro Silva | Senior Machine Learning Engineer; Shloka Desai | Machine Learning Engineer II; Ashudeep Singh | Machine Learning Engineer II; Nadia Fawaz | (former) Inclusive AI Tech Lead Introduction Pinterest is a platform designed to bring everyone the inspiration to create a life they love.
With all the buzz surrounding the ChatGPT. Are you eager to make the most out of it? Here is the FREE video course that offers a comprehensive education about OpenAI API through detailed explanations and hands-on projects.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Learn to do Format Preserving Encryption (FPE) at scale, securely move data from production to test environments Continue reading on Towards Data Science »
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Author’s note: this article about marketing trends has been adapted from an article originally published in The CMO. What are your goals in 2023, and which marketing trends can help you achieve them? In my role as Chief Marketing Officer (CMO) here at Precisely, an important part of what I do is to keep a finger on the pulse of the latest marketing innovations and strategize with my team around how we may be able to capitalize on industry trends to produce even bigger and better results.
We are excited to announce Azure Databricks support for Azure confidential computing (ACC) in preview! With this announcement, customers can run their Azure.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content