This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI is taking the world by storm – here’s what it means for data engineering and why data observability is critical for this groundbreaking technology to succeed. Maybe you’ve noticed the world has dumped the internet, mobile, social, cloud and even crypto in favor of an obsession with generative AI. But is there more to generative AI than a fancy demo on Twitter?
Introduction Welcome back to the success story interview series with a successful data scientist and our DataHour Speaker, Vidhya Chandrasekaran! In today’s data-driven world, data scientists play a crucial role in helping businesses make informed decisions by analyzing and interpreting data. With their expertise in statistics, machine learning, AI, and programming, they are able to […] The post Data Scientist’s Insights: Strategies for Innovation and Leadership appeared first
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and high-growth startups through the lens of engineering managers and senior engineers. In this article, we cover one out of four topics from today’s subscriber-only The Scoop issue. If you’re not a full subscriber yet, you missed this week’s deep-dive on Shopify’s leveling split.
This article discusses the significance of large language and visual models in AI, their capabilities, potential synergies, challenges such as data bias, ethical considerations, and their impact on the market, highlighting their potential for advancing the field of artificial intelligence.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
ChatGPT and data streaming can work together for any company. Learn a basic framework for using GPT-4 and streaming to build a real-world production application.
Discover how Lyft identified and fixed performance issues in our streaming pipelines. Background Every streaming pipeline is unique. When reviewing a pipeline’s performance, we ask the following questions: “Is there a bottleneck?”, “Is the pipeline performing optimally?”, “Will it continue to scale with increased load?” Regularly asking these questions are vital to avoid scrambling to fix performance issues at the last minute.
Rethinking the newsletter ( credits ) Here's a new edition of the Data News newsletter. Since my 2-year anniversary post, I've been struggling to find the right writing rhythm. I've been sick and I've been stuck on a client project. Writing the newsletter was not an easy exercise. Even though I keep telling myself "it's not a question of motivation, it's a question of discipline" like a LinkedIn guy.
One of my greatest pleasures in life is watching the r/dataengineering Reddit board, I find it very entertaining and enlightening on many levels. It gives a fairly unique view into the wide range of Data Engineering companies, jobs, projects people are working on, tech stacks, and problems that are being faced. One thing I’ve come […] The post 4 Ways To Setup Your Data Engineering Game. appeared first on Confessions of a Data Guy.
Summary A significant portion of the time spent by data engineering teams is on managing the workflows and operations of their pipelines. DataOps has arisen as a parallel set of practices to that of DevOps teams as a means of reducing wasted effort. Agile Data Engine is a platform designed to handle the infrastructure side of the DataOps equation, as well as providing the insights that you need to manage the human side of the workflow.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Sun is coming in Berlin ( credits ) Hey, I've been sick longer than I expected, but I'm finally well. I hope this email finds you all well, as well. I've had to catch up on almost 3 weeks of content. When I step back, the amount of articles shared each week is insane, there are countless articles about things that have already been written.
by Akshay Garg , Roger Quero Introduction Maximizing immersion for our members is an important goal for the Netflix product and engineering teams to keep our members entertained and fully engaged in our content. Leveraging a good mix of mature and cutting-edge client device technologies to deliver a smooth playback experience with glitch-free in-app transitions is an important step towards achieving this goal.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
The availability of deep learning frameworks like PyTorch or JAX has revolutionized array processing, regardless of whether one is working on machine learning tasks or other numerical algorithms. The Haskell library ecosystem has been catching up as well, and there are now multiple good array libraries. However, writing high-performance array processing code in Haskell is still a non-trivial endeavor.
Announcing a new portfolio of Generative AI learning offerings on Databricks Academy Enroll in the Large Language Models: Application through Production on Databricks.
Introducing Lyft Engineering: Hello Czechia! Ahoj! Lyft is opening offices in Czechia ?? and hiring for full-time positions on end-to-end product, science, and engineering teams. We’re looking for driven engineers to fortify our European operations and solve some of the hardest problems in building large distributed systems to support rideshare, mapping, and more.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
LLMs present a massive opportunity for organizations of all scales to quickly build powerful applications and deliver business value. Where data scientists used.
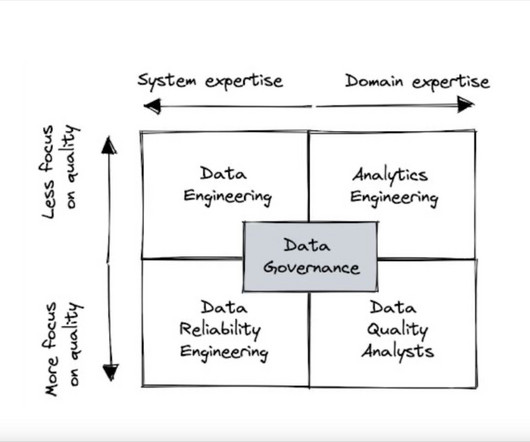
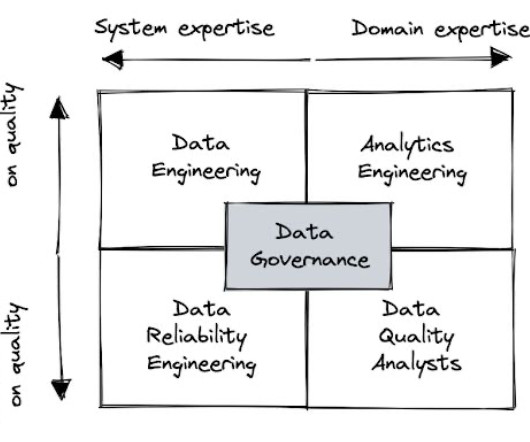
Sure, data quality is everyones’ problem. But who is responsible for data quality? Given the variations in approach and mixed success, we have a lot of natural experiments from which to learn. Some organizations will attempt to diffuse the responsibility widely across data stewards, data owners, data engineering and governance committees, each owning a fraction of the data value chain.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Fitbit activity analysis with DuckDB Photo by Jake Hills on Unsplash Wearable fitness trackers have become an integral part of our lives, collecting and tracking data about our daily activities, sleep patterns, location, heart rate, and much more. I’ve been using a Fitbit device for 6 years to monitor my health. However, I have always found the data analysis capabilities lacking — especially when I wanted to track my progress against long term fitness goals.
In today's data-driven landscape, organizations face the challenge of aggregating data to derive meaningful insights that enrich audience profiles. Traditional data integration methods.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Specialists or generalists? Engineer or analyst? We examine which team structures are the best suited for efficiently improving data quality. Image courtesy of Shane Murray. Sure, data quality is everyones’ problem. But who owns the solution? Given the variations in approach and mixed success, we have a lot of natural experiments from which to learn.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content