This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is a guest post from our friends over at Satori Cyber. Data-driven organizations generate, collect, and store vast amounts of data. To effectively manage and analyze this data, data engineering teams must navigate a wide range of challenges, including data access, security, compliance, and data observability. Automation is a missing link in many organizations’ efforts toward data operationalization.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. We cover one out of six topics in today’s subscriber-only The Pulse issue. If you’re not yet a full subscriber, you missed this week’s deep-dive on Software architect archetypes. To get the full issues, twice a week, subscribe here. Before we start, a small change.
That's the conference I've heard only recently about. What a huge mistake! Despite the lack of "data" word in the name, it covers many interesting data topics and before I share with you my notes from this year's Data+AI Summit, let me do the same for Berlin Buzzwords!
Summary For business analytics the way that you model the data in your warehouse has a lasting impact on what types of questions can be answered quickly and easily. The major strategies in use today were created decades ago when the software and hardware for warehouse databases were far more constrained. In this episode Maxime Beauchemin of Airflow and Superset fame shares his vision for the entity-centric data model and how you can incorporate it into your own warehouse design.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Some data teams need to have their data near real-time for dashboards and reporting. So how can they implement a near real-time data pipeline? One possible choice is a method called change data capture, also known as CDC. I have seen companies employ multiple ways to use CDC or CDC-like approaches to pull data from… Read more The post What Is Change Data Capture appeared first on Seattle Data Guy.
Who's leading the data peloton? ( credits ) Hey you, this is the Saturday Data News edition 🥲 Time flies. I'm working for the Series of articles in advance for August about "creating data platforms" and I'm looking for ideas about the data I could use for this. Having some kind of simulated real-time data would be the best.
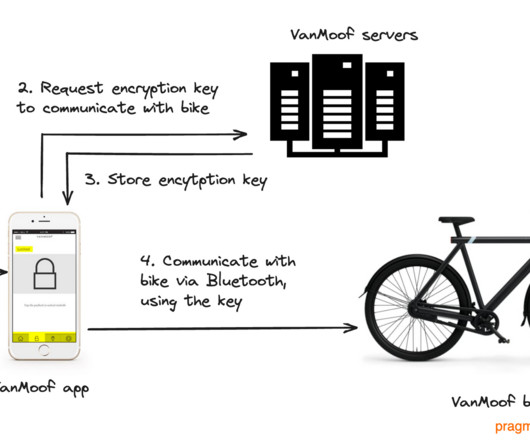
Onion Routing is a method of communicating anonymously across a computer network. The layers of encryption that protect messages in an onion network are comparable to the layers of an onion. The encrypted data is sent through a network of "onion routers," or network nodes, each of which "peels" away a single layer to disclose the encrypted data's destination.
ESO is the largest software and data solutions provider to emergency medical services (EMS) agencies and fire departments in the U.S. With a mission to improve community health and public safety through the power of data, ESO makes software that helps save lives. If you call 911 and a fire or medical team responds, it’s likely they’re using ESO software to make sure you get the right help fast.
The article highlights various use cases of synthetic data, including generating confidential data, rebalancing imbalanced data, and imputing missing data points. It also provides information on popular synthetic data generation tools such as MOSTLY AI, SDV, and YData.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
In a crowded retail marketplace, organizations increasingly compete for consumer time, attention and spend. Gone are the days where broadstroke advertisements and bulk.
Divye , Teja , Chen , Sam , Lu , Heng , Kanchi , Rainie , Dinesh , Ashish , Nishant , Pooja | Stream Processing Platform Team At Pinterest, stream data processing powers a wide range of real-time use cases. Our Flink clusters are multitenant and run jobs that concurrently process more than 20M msgs/sec across 12 clusters. Over the course of 2022 and early 2023, we’ve spent a significant period of time optimizing our Flink runtime environment and cluster configurations, and we’d like to share our
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
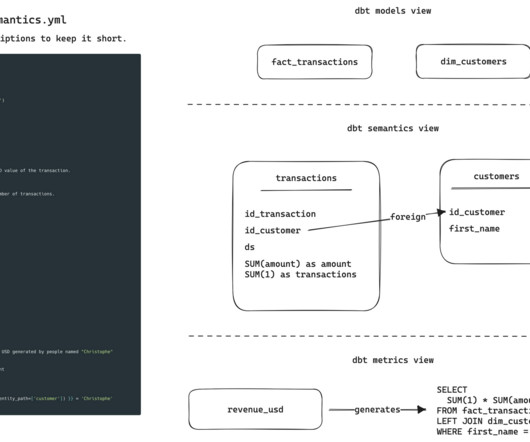
A simple framework for building dbt models that actually get used. When I was researching the Ultimate Guide to dbt , I was shocked by the lack of material around actually building models from scratch. Not the exact steps to take in the tool — that is all covered in innumerable blogs and tutorials. I mean how do you know the right design? How do you make sure your stakeholders will use that model?
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Snowflake Native Apps introduce a new model for cloud-based software. To buy and use a traditional SaaS app, a business has to go through lengthy evaluations and verify that the application builder adhered to their standards of data security. This is a critical step because the application is processing data that belongs to the customer, and in order for the customer to use the app, the customer’s data must either be moved to where the application runs, or the application must collect or produce
Iceberg is an emerging open-table format designed for large analytic workloads. The Apache Iceberg project continues developing an implementation of Iceberg specification in the form of Java Library. Several compute engines such as Impala, Hive, Spark, and Trino have supported querying data in Iceberg table format by adopting this Java Library provided by the Apache Iceberg project.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Welcome to our recap of all of the great industry sessions presented at Snowflake Summit 2023, which just wrapped up in Las Vegas. As we continue to revolutionize the way businesses operate, allowing them to solve their most pressing problems and drive revenue through the Data Cloud, the insights, expertise, and experiences we offer at Summit have continued to grow.
Apache Impala and Apache Kudu make a great combination for real-time analytics on streaming data for time series and real-time data warehousing use cases. More than 200 Cloudera customers have implemented Apache Kudu with Apache Spark for ingestion and Apache Impala for real-time BI use cases successfully over the last decade, with thousands of nodes running Apache Kudu.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Building a maintainable and modular LLM application stack with Hamilton in 13 minutes LLM Applications are dataflows, use a tool specifically designed to express them LLM stacks. Using the right tool, like Hamilton, can sure your stack doesn’t become a pain to maintain and manage. Image from pixabay. This post is written in collaboration with Thierry Jean and originally appeared here.
Introduction For more than a decade now, the Hive table format has been a ubiquitous presence in the big data ecosystem, managing petabytes of data with remarkable efficiency and scale. But as the data volumes, data variety, and data usage grows, users face many challenges when using Hive tables because of its antiquated directory-based table format.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content