This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The All Things Insights and marketing analytics and data science community completed an extensive survey covering what executives are thinking, how they’re spending and the issues and opportunities they face. Grab your free copy now.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one out of five topics from today’s subscriber-only deepdive on Advice on how to sell a startup. To get full issues twice a week, subscribe here.
Starting from Apache Spark 3.2.0 is now possible to load an initial state of the arbitrary stateful pipelines. Even though the feature is easy to implement, it hides some interesting implementation details!
1. Introduction 2. Sample project 3. Best practices 3.1. Use standard patterns that progressively transform your data 3.2. Ensure data is valid before exposing it to its consumers (aka data quality checks) 3.3. Avoid data duplicates with idempotent pipelines 3.4. Write DRY code & keep I/O separate from data transformation 3.5. Know the when, how, & what (aka metadata) of pipeline runs for easier debugging 3.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Summary Data has been one of the most substantial drivers of business and economic value for the past few decades. Bob Muglia has had a front-row seat to many of the major shifts driven by technology over his career. In his recent book "Datapreneurs" he reflects on the people and businesses that he has known and worked with and how they relied on data to deliver valuable services and drive meaningful change.
The ETL & ELT tool market is experiencing continuous transformation, propelled by fluctuating pricing structures and the advent of inventive alternatives. This industry remains fiercely competitive due to these changing elements and a swiftly growing user base. In the following sections, we will explore four emerging alternatives to Fivetran. Of course, that is if you… Read more The post 4 Alternatives to Fivetran: The Evolving Dynamics of the ETL & ELT Tool Market appeared first
Have fun train models on this ( credits ) Hey, it's Saturday I hope you're enjoying July, taking deserve break, reading data engineering articles while at the beach or traveling to unknown places. Sometimes there are Fridays when I don't find any glue between articles for the newsletter and I have an idea of something to compensate but it takes me the whole Friday of exploration.
Have fun train models on this ( credits ) Hey, it's Saturday I hope you're enjoying July, taking deserve break, reading data engineering articles while at the beach or traveling to unknown places. Sometimes there are Fridays when I don't find any glue between articles for the newsletter and I have an idea of something to compensate but it takes me the whole Friday of exploration.
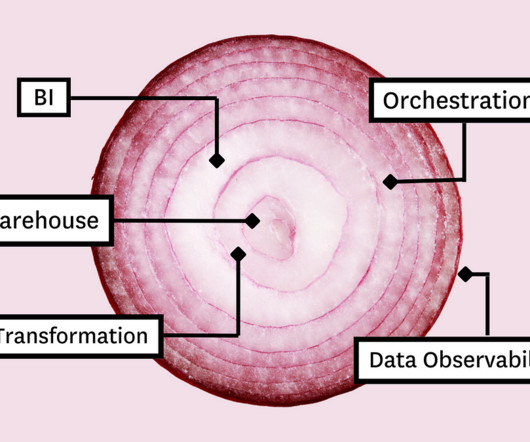
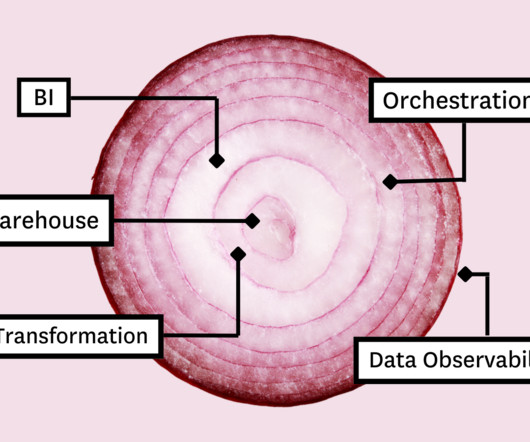
Spinning up a data platform doesn’t have to be complicated. Here are the 5 must-have layers to drive data product adoption at scale. Image courtesy of author. We hope it doesn’t make your eyes water. Like bean dip and ogres , layers are the building blocks of the modern data stack. Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the data pipeline.
Today, Meta released their latest state-of-the-art large language model (LLM) Llama 2 to open source for commercial use1. This is a significant development.
Gain the easiest solution for data streaming and increase data flow to your platform through native integrations with Confluent Cloud and 120+ Kafka connectors.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
At ThoughtSpot, we believe making data accessible to every knowledge worker requires human-centered technology—an analytics experience that bridges the “language” barrier between technology and people. AI is the perfect compliment to search because it empowers organizations to analyze, understand, and act on data. In order to achieve this vision, we knew we’d need to work with some of the best, most innovative technology companies across the modern data stack —companies that put their users fir
We are excited to announce enhanced monitoring and observability features in Databricks Workflows. This includes a new real-time insights dashboard to see all.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Today, we’re excited to share that we’ve completed our acquisition of MosaicML, a leading platform for creating and customizing generative AI models for you.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Don’t have any coding experience? Don’t worry. Check out this drag-and-drop tool that helps you to build your own customized LLM flows. And guess what, you don’t have to be a tech professional!
Brian Overstreet | Software Engineer, Observability; Humsheen Geo | Software Engineer, Observability Time series is a critical part of Observability at Pinterest, powering 60,000 alerts and 5,000 dashboards. A time series is an identifier with values where the values are associated with a timestamp. Given the widespread use and critical nature of time series, it’s important to give engineers the ability to adequately express what operations to perform on the time series in a readable, understand
Let's say a distributor reached out wanting to understand what factors are driving the sale of carbonated beverages from customers in their convenience.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Building a data stack doesn’t have to be complicated. Here’s what data leaders say are the 5 must-have layers of your data platform to drive data adoption – and ROI – across your business. Like bean dip and ogres , layers are the building blocks of the modern data stack. Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the data pipeline.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
This article explores the technical details and implications of Meta's newly released Llama 2, a large language model that promises to revolutionize the field of generative AI. We delve into its capabilities, performance, and potential applications, while also discussing its open-source nature and the company's commitment to safety and transparency.
For over a year now, Databricks and dbt Labs have been working together to realize the vision of simplified real-time analytics engineering, combining.
Meta has made it possible for people to upload high dynamic range (HDR) videos from their phone’s camera roll to Reels on Facebook and Instagram. To show standard dynamic range (SDR) UI elements and overlays legibly on top of HDR video, we render them at a brightness level comparable to the video itself. We solved various technical challenges to ensure a smooth transition to HDR video across the diverse range of old and new devices that people use to interact with our services every day.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content