This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. To get full issues twice a week, subscribe here. The past month, we’ve done deepdives in the newsletter on what a senior software engineer is at Big Tech , and at scaleups.
A few months ago, I uploaded a video where I discussed data warehouses, data lakes, and transactional databases. However, the world of data management is evolving rapidly, especially with the resurgence of AI and machine learning. There are numerous other methods that technical teams are utilizing to handle their data effectively. In this presentation, I… Read more The post Data Warehouses Vs Operational Data Stores Vs Data Lakes – How To Store Your Data For Analytics appeared first
When you wrote your first arbitrary stateful processing pipelines, the state expiration is maybe the first tricky point you had to deal with. Why is that? After all, it's just about setting the timeout, doesn't it? Most of the time, yes, but there is an exception.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
👋 Hi, this is Gergely with a free issue of the Pragmatic Engineer Newsletter. We cover one out of five topics in today’s subscriber-only The Pulse issue. If you’re not yet a full subscriber, you missed this week’s deepdive: The 2023 tech market, as seen by hiring managers. To get full newsletters twice a week, subscribe here.
Summary All software systems are in a constant state of evolution. This makes it impossible to select a truly future-proof technology stack for your data platform, making an eventual migration inevitable. In this episode Gleb Mezhanskiy and Rob Goretsky share their experiences leading various data platform migrations, and the hard-won lessons that they learned so that you don't have to.
Summary All software systems are in a constant state of evolution. This makes it impossible to select a truly future-proof technology stack for your data platform, making an eventual migration inevitable. In this episode Gleb Mezhanskiy and Rob Goretsky share their experiences leading various data platform migrations, and the hard-won lessons that they learned so that you don't have to.
The Databricks Container Infra team builds cloud-agnostic infrastructure and tooling for building, storing and distributing container images. Recently, the team worked on scaling.
A Step-by-Step Guide to Building an Effective Data Quality Strategy from Scratch How to build an interpretable data quality framework based on user expectations Photo by Rémi Müller on Unsplash As data engineers, we are (or should be) responsible for the quality of the data we provide. This is nothing new, but every time I join a data project I ask myself the same questions: When should I start working on data quality?
Introduction Since 2021, Zalando invested in building up a developer portal called Sunrise, aimed to become the starting point for Builders at Zalando. The portal is based on Spotify's Backstage platform with additional extensions built internally. Sunrise enables everyone at Zalando to view and discover information about teams, applications, APIs, events, CI/CD pipelines, Infrastructure accounts and costs, and much more.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Are you trying to solve your first data science project? This tutorial will help you to guide you step by step to prepare your dataset before applying the machine learning model.
We are thrilled to announce the opening of Databricks’ latest development center in Belgrade, Serbia. This addition joins our existing R&D centers in A.
The results are in! The 2023 Data Integrity Trends and Insights Report , published in partnership between Precisely and Drexel University’s LeBow College of Business, delivers groundbreaking insights into the importance of trusted data. For the report, more than 450 data and analytics professionals worldwide were surveyed about the state of their data programs.
An interview with Behnam Rezaei | Pinterest VP, Engineering At Pinterest, we’re on a mission to bring everyone the inspiration to create a life they love. For our employees, this extends further to creating the life and career they love. The Pinterest Engineering Blog team sat down with Behnam Rezaei to get an inside scoop into the Monetization Engineering team, what makes Pinterest different and why now is a great time to join our team.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Today, we are excited to announce the public preview of Databricks Assistant, a context-aware AI assistant, available natively in Databricks Notebooks, SQL editor.
Modern Announces Partnership with Data Mesh Pioneers, ThoughtWorks In July, we collaborated with ThoughtWorks at the annual CDOIQ Conference in Cambridge, MA to discuss real-world Data Products implementation and best practices for Data Mesh. The data community, especially CDOs, emphasized the importance of raising awareness and gaining clarity about data products.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Google's BQML can be used to make time series models, and recently it was updated to create multivariate time series models. With the simple code, this article shows how to use it to predict multivariate time series and it can be more powerful than a univariate time series model in this article.
In the ever-evolving realm of healthcare, two powerful trends have emerged: The rise of personalized medicine and the increasing emphasis on patient involvement.
Leveraging The Powers of Functional Code — Part 2 The Fully Functional Haskell Solution Part one can be found here: [link] The Solution: Regarding the Haskell code — don’t worry if you don’t understand everything. I am going to explain the main points of it by drawing a parallel to the Java implementation. If you are curious about FP, I cannot recommend this book enough, and the online version is free: [link] It is a pleasant read with lots of humor (just the illustrations by themselves make me
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
ChatGPT Code Interpreter: Do Data Science in Minutes • This Week in AI • Introduction to Statistical Learning, Python Edition: Free Book • 8 Programming Languages For Data Science to Learn in 2023 • Mastering GPUs: A Beginner's Guide to GPU-Accelerated DataFrames in Python
As cryptocurrencies, particularly Bitcoin, have grown in popularity, so has the phenomenon of Bitcoin mining. While normal mining operations are critical for blockchain.
Robinhood Markets, Inc. (Nasdaq: HOOD) today reported financial results for the quarter ended June 30, 2023. Read our Q2 earnings press release here. Access more information at investors.robinhood.com. The post Robinhood Reports Second Quarter 2023 Results appeared first on Robinhood Newsroom.
Accurate and reliable observability is essential when supporting a large distributed service, but this is only possible if your tools are equally scalable. Unfortunately, this was a challenge at DoorDash because of peak traffic failures while using our legacy metrics infrastructure based on StatsD. Just when we most needed observability data, the system would leave us in the lurch.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Unlock the power of AI collaboration with Keras 3.0! Seamlessly switch between TensorFlow, JAX, and PyTorch, revolutionizing your deep learning projects. Read now and stay ahead in the world of AI.
Reading Time: 9 minutes Obtaining a user’s location is a critical requirement for many modern web applications, such as location-based services, personalized content delivery, and targeted marketing. However, without proper guidance and understanding of HTML and JavaScript geolocation techniques, developers often face challenges in implementing this feature effectively.
LinkedIn and Cornell Ann S. Bowers College of Computing and Information Science (Bowers CIS) embarked on a partnership , bringing together our collective research power to make technological advances that will further our goal to connect professionals with opportunities at scale. Through this partnership, we support Ph.D. students and faculty members on their research in areas in Computer Science, AI, Information Science including Diversity and Equity.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






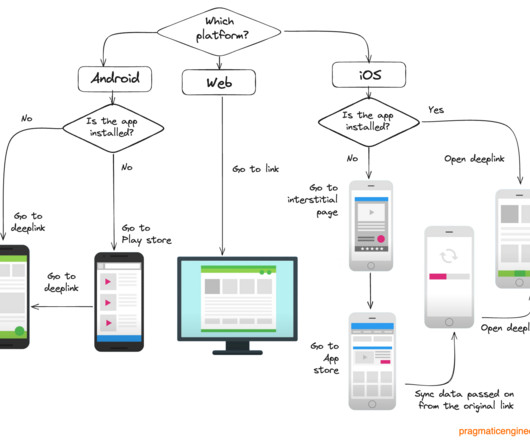





































Let's personalize your content