This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The rise of AI and GenAI has brought about the rise of new questions in the data ecosystem – and new roles. One job that has become increasingly popular across enterprise data teams is the role of the AI data engineer. Demand for AI data engineers has grown rapidly in data-driven organizations. But what does an AI data engineer do? What are they responsible for?
Unapologetically Technical’s newest episode is now live! In this episode of Unapologetically Technical, I interview Cliff Crosland, the co-founder and CEO of Scanner.dev. Cliff Crosland is a data engineer passionate about helping people wrangle massive log volumes. He sees logs as a treasure trove of insights and believes effective log analysis is critical in today’s complex systems.
Key Takeaways: Data mesh is a decentralized approach to data management, designed to shift creation and ownership of data products to domain-specific teams. Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. Both approaches empower your organization to be more agile, data-driven, and responsive so you can make informed decisions in real time.
I am a glutton for punishment, a harbinger of tidings, a storm crow, a prophet of the data land, my sole purpose is to plumb the depths of the tools we use every day in Data Engineering. I find the good, the bad, the ugly, and splay them out before you, string ’em up and […] The post Testing DuckDB’s Large Than Memory Processing Capabilities. appeared first on Confessions of a Data Guy.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Demystifying Azure Storage Account Network Access Service endpoints and private endpoints hands-on: including Azure Backbone, storage account firewall, DNS, VNET and NSGs Connected Network — image by Nastya Dulhiier on Unsplash 1. Introduction Storage accounts play a vital role in a medallion architecture for establishing an enterprise data lake. They act as a centralized repository, enabling seamless data exchange between producers and consumers.
Astasia Myers: The three components of the unstructured data stack LLMs and vector databases significantly improved the ability to process and understand unstructured data. I never thought of PDF as a self-contained document database, but that seems a reality that we can’t deny. The blog is an excellent summary of the existing unstructured data landscape.
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. Data transformation is key for data-driven decision-making, allowing organizations to derive meaningful insights from varied data sources.
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. Data transformation is key for data-driven decision-making, allowing organizations to derive meaningful insights from varied data sources.
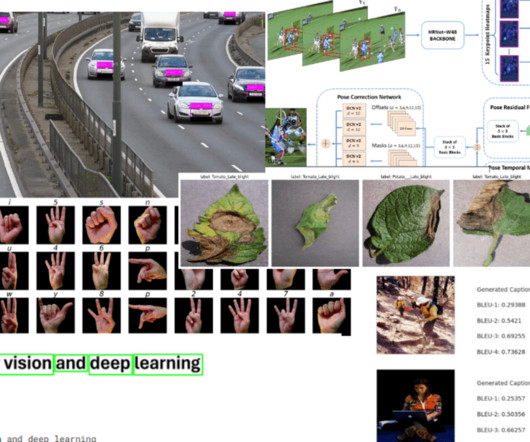
Each project, from beginner tasks like Image Classification to advanced ones like Anomaly Detection, includes a link to the dataset and source code for easy access and implementation.
While predicting the future may be impossible (so far), analyzing trends and learning from industry leaders can help us get pretty close. In an effort to better understand where data governance is heading, we spoke with top executives from IT, healthcare, and finance to hear their thoughts on the biggest trends, key challenges, and what insights they would recommend.
Read Time: 5 Minute, 8 Second In a financial institution, sensitive information such as Customer Numbers , transaction details , and customer balances are often needed for internal analysis and reporting. However, due to compliance regulations, access to these fields needs to be restricted based on the user’s role. To solve this, we’ll apply Projection Policies to ensure that only certain roles can see sensitive columns like Customer numbers.
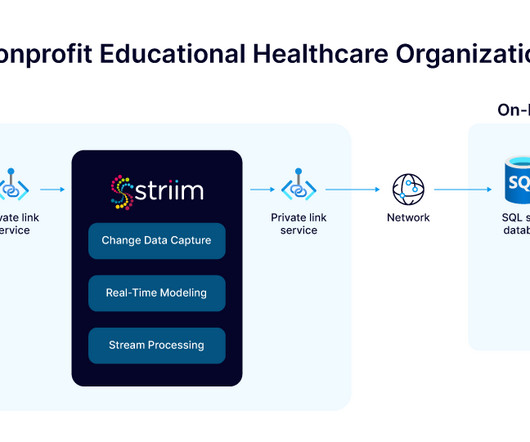
A nonprofit educational healthcare organization is faced with the challenge of modernizing its critical systems while ensuring uninterrupted access to essential services. With Striim’s real-time data integration solution, the institution successfully transitioned to a cloud infrastructure, maintaining seamless operations and paving the way for future advancements.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
“That should take two hours, not two months. Can’t your Data & Analytics Team go any faster?” “The executives’ dashboard broke! The data’s wrong! Can I ever trust our data?” If you’ve ever heard (or had) these complaints about speed-to-insight or data reliability, you should watch our webinar, DataOps for Beginners, on demand. DataKitchen’s VP Gil Benghiat breaks down what DataOps is (spoiler: it’s not just DevOps for data) and how DataOps can take your Data & Analytics factory fro
We are thrilled to announce the General Availability of a Python step-through debugger for Databricks Notebooks and Files. This highly requested feature allows.
Understanding GenAI models Generative AI (GenAI) models are designed to create content, recognise patterns and make predictions. In addition, they have an ability to improve over time as they are exposed to more data. GenAI chatbot models, such as GPT-4 by OpenAI, can generate human-like text and other forms of content autonomously. They can produce outputs that are remarkably like human-created content, making them useful for a wide range of applications.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Robinhood Markets, Inc. (Nasdaq: HOOD) today reported financial results for the quarter ended September 30, 2024. Read our Q3 2024 earnings press release here. Access more information at investors.robinhood.com. The post Robinhood Reports Third Quarter 2024 Results appeared first on Robinhood Newsroom.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Learn about how the Storage team at Uber significantly reduced costs and improved speed for backups of its Petabyte-scale, MyRocks-based distributed databases by devising a Differential Backups solution.
Step-by-Step Instructions for Constructing a Dataset of PubMed-Listed Publications on Cardiovascular Disease Research Continue reading on Towards Data Science »
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
Deploying Confluent Platform in conjunction with Confluent's OEM Program can help CSPs and MSPs develop high-margins, while maintaining operational excellence and lowering risk.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content