This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What does the data reveal if we ask: "What are the 10 Best Python Courses?". Collecting almost all of the courses from top platforms shows there are plenty to choose from, with over 3000 offerings. This article summarizes my analysis and presents the top three courses.
Image by Mohammad Bagher Adib Behrooz on Unsplash Why GraphQL for data engineers, you might ask? GraphQL solved the problem of providing a distinct interface for each client by unifying it to a single API for all clients such as web, mobile, web apps. The same challenge we’re now facing in the data world, where we integrate multiple clients with numerous backend systems.
As I meet with our customers, there are always a range of discussions regarding the use of the cloud for financial services data and analytics. Customers vary widely on the topic of public cloud – what data sources, what use cases are right for public cloud deployments – beyond sandbox, experimentation efforts. Private cloud continues to gain traction with firms realizing the benefits of greater flexibility and dynamic scalability.
On behalf of the Apache Kafka® community, it is my pleasure to announce the release of Apache Kafka 3.1.0. The 3.1.0 release contains many improvements and new features. We’ll highlight […].
Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.
There are many great boosting Python libraries for data scientists to reap the benefits of. In this article, the author discusses LightGBM benefits and how they are specific to your data science job.
The use of integrated data to restore customer confidence will be big in 2022. Building a customer insights foundation should be high on the to-do list for retail & CPG businesses this year.
Martin Tingley with Wenjing Zheng , Simon Ejdemyr , Stephanie Lane , Colin McFarland , Mihir Tendulkar , and Travis Brooks This is the last post in an overview series on experimentation at Netflix. Need to catch up? Earlier posts covered the basics of A/B tests ( Part 1 and Part 2 ), core statistical concepts ( Part 3 and Part 4 ), how to build confidence in a decision ( Part 5 ), and the the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at N
Martin Tingley with Wenjing Zheng , Simon Ejdemyr , Stephanie Lane , Colin McFarland , Mihir Tendulkar , and Travis Brooks This is the last post in an overview series on experimentation at Netflix. Need to catch up? Earlier posts covered the basics of A/B tests ( Part 1 and Part 2 ), core statistical concepts ( Part 3 and Part 4 ), how to build confidence in a decision ( Part 5 ), and the the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at N
Summary Data platforms are exemplified by a complex set of connections that are subject to a set of constantly evolving requirements. In order to make this a tractable problem it is necessary to define boundaries for communication between concerns, which brings with it the need to establish interface contracts for communicating across those boundaries.
In order to achieve quality data, there is a process that needs to happen. That process is data cleaning. Learn more about the various stages of this process.
Analytics are prone to frequent data errors and deployment of analytics is slow and laborious. The strategic value of analytics is widely recognized, but the turnaround time of analytics teams typically can’t support the decision-making needs of executives coping with fast-paced market conditions. Perhaps it is no surprise that the average tenure of a CDO or CAO is only about 2.5 years.
The start of a new year is a perfect time to reflect on what was accomplished and look forward, re-evaluate what we can do better. Change, although difficult at first, can also be very rewarding. That’s why I was excited to see similar sentiments shared at Thoughtspot beyond.2021 to move beyond the traditional dashboards of the past. As roles within organizations evolve (as seen by the growth of citizen scientists and analytics engineers) and as data needs change (think schema changes and real-
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
Summary Data engineering is a relatively young and rapidly expanding field, with practitioners having a wide array of experiences as they navigate their careers. Ashish Mrig currently leads the data analytics platform for Wayfair, as well as running a local data engineering meetup. In this episode he shares his career journey, the challenges related to management of data professionals, and the platform design that he and his team have built to power analytics at a large company.
Angus Croll Netflix is used by 222 million members and runs on over 1700 device types ranging from state-of-the-art smart TVs to low-cost mobile devices. At Netflix we’re proud of our reliability and we want to keep it that way. To that end, it’s important that we prevent significant performance regressions from reaching the production app. Sluggish scrolling or late rendering is frustrating and triggers accidental navigations.
According to 451 Research , 96% of enterprises are actively pursuing a hybrid IT strategy. Modern, real-time businesses require accelerated cycles of innovation that are expensive and difficult to maintain with legacy data platforms. Cloud technologies and respective service providers have evolved solutions to address these challenges. . The hybrid cloud’s premise—two data architectures fused together—gives companies options to leverage those solutions and to address decision-making criteria, on
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Today we’re announcing an exciting Strategic Collaboration Agreement (SCA) with Amazon Web Services (AWS). This new five-year agreement builds on our strong existing collaboration, with the goal of making it […].
In recent years, it’s getting more common to see organizations looking for a mysterious analytics engineer. As you may guess from the name, this role sits somewhere in the middle of a data analyst and data engineer, but it’s really neither one nor the other. Quoting a comment from the Reddit discussion , “Their [analytics engineers] job is to marry the technical requirements of the data stack with the business objectives”.
Insurers are increasingly adopting data from smart devices and related technologies to support and service their customers better. According to Statista , the projected installed base of IOT devices is expected to increase to 30.9 billion units by 2025, a huge jump from the 13.8 billion units that exist today. I have been researching more about how we can use the new data from those devices to design more innovative insurance products while being aware that these should all be contingent upon cu
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
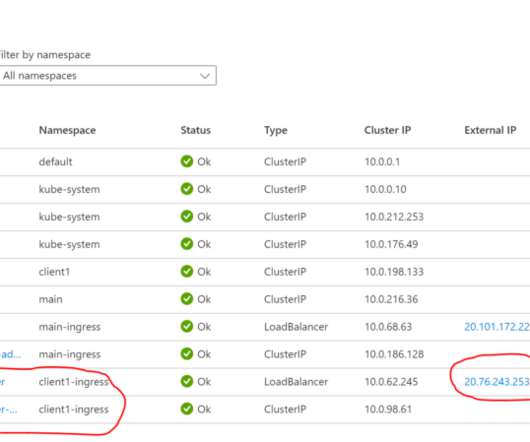
You may find yourself needing to deploy multiple NGINX Ingress Controllers to serve each namespace on your Kubernetes cluster. This may be useful in a scenario where you have multiple client deployments on the same K8S cluster; and you want to assign a public load balancer IP address for each client to achieve logical separation. This blogpost explores how to do that.
Whether you’re working independently or setting up a stack for a company, you need an affordable stack option. Here’s how you can set up your stack without spending too much.
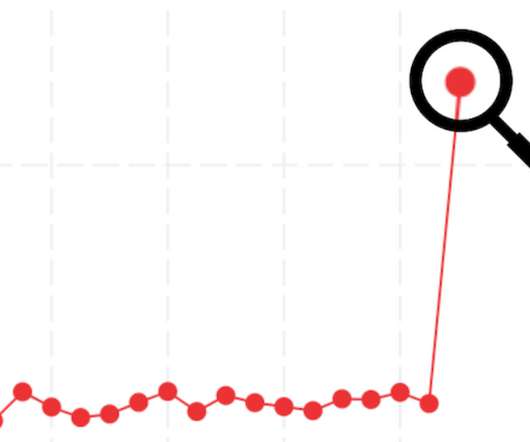
In data science, algorithms are usually designed to detect and follow trends found in the given data. The modeling follows from the data distribution learned by the statistical or neural model. In real life, the features of data points in any given domain occur within some limits. They will only go outside of these expected patterns in exceptional cases, which are usually erroneous or fraudulent.
Seesaw Learning Inc. provides a leading online student learning platform used by more than 10 million K-12 teachers, students and family members in the U.S. every month. The San Francisco company has grown steadily since its founding in 2013, with its hosted service in use in 75% of American schools and in another 150 countries. Of course, when COVID-19 hit in early 2020 and forced schools to abruptly switch to full-time remote learning, the need for Seesaw’s platform skyrocketed.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Data engineering is the process of designing and implementing solutions to collect, store, and analyze large amounts of data. This process is generally called “Extract, Transfer, Load” or ETL. The data then gets prepared in formats to be used by people such as business analysts, data analysts, and data scientists. The format of the data will be different depending on the intended audience.
Participating in competitions has taught me everything about machine learning and how It can help you learn multiple domains faster than online courses.
Apache Superset 1.4 is now out! This version contains the most number of bug fixes in recent history, a variety of UX improvements, and improved database support.
The prevalence of new business models, emerging global risks & modernization of data processing in the cloud is ushering in a new era for credit risk management & the transformation of risk analytics.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
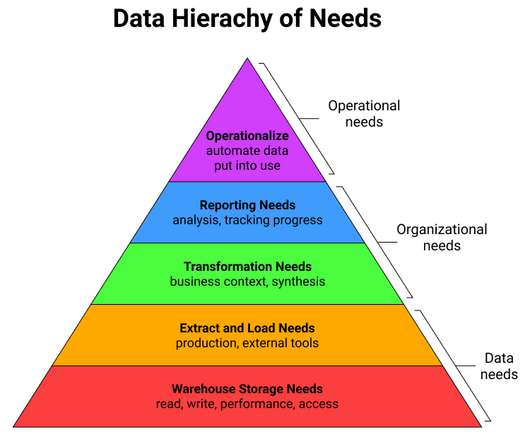
In psychology, there is a famous construct created by Abraham Maslow called the hierarchy of needs. Put simply, it says that people must first satisfy their basic needs before they can progress to focusing on more nuanced goals. It’s often shown as a pyramid where each need builds on top of the previous one. The goal, of course, is to reach the top.
In this article, see how you can get above 90% accuracy on the validation set with a pretty straightforward approach. You'll also see what happens to the validation accuracy if we scale down the amount of training data by a factor of 20. Spoiler alert - it will remain unchanged.
Before we go on to explain why they made the best decisions and how they have found their ‘Happily Ever After’ in the career with our program, here are some fun facts about the booming Data Science domain – According to Globe Newswire , The global predictive analytics market is expected to become 21.5 billion USD by 2025, growing at a CAGR of 24.5%.
Did you know that, according to Linkedin, over 24,000 Big Data jobs in the US list Apache Spark as a required skill? Learning Spark has become more of a necessity to enter the Big Data industry. One of the most in-demand technical skills these days is analyzing large data sets, and Apache Spark and Python are two of the most widely used technologies to do this.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content