This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Testing your data pipeline 1. End-to-end system testing 2. Data quality testing 3. Monitoring and alerting 4. Unit and contract testing Conclusion Further reading Introduction Testing data pipelines are different from testing other applications, like a website backend.
At the end of May, we released the second version of Cloudera SQL Stream Builder (SSB) as part of Cloudera Streaming Analytics (CSA). Among other features, the 1.4 version of CSA surfaced the expressivity of Flink SQL in SQL Stream Builder via adding DDL and Catalog support, and it greatly improved the integration with other Cloudera Data Platform components, for example via enabling stream enrichment from Hive and Kudu. .
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. It was also designed to be able to work for small scale systems that are just starting to develop in complexity.
Data silos across an organization are common, with valuable business insights waiting to be uncovered. This is why at Confluent we built a portfolio of fully managed connectors to enable […].
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
1. Introduction 2. E-T-L definition 3. Differences between ETL & ELT 4. Conclusion 5. Further reading 1. Introduction If you are a student, analyst, engineer, or anyone working with data pipelines, you would have heard of ETL and ELT architecture. If you have questions like What is the difference between ETL & ELT? Should I use ETL or ELT pattern for my data pipeline?
According to Domo, on average, every human created at least 1.7 MB of data per second in 2020. That’s a lot of data. For enterprises the net result is an intricate data management challenge that’s not about to get any less complex anytime soon. Enterprises need to find a way of getting insights from this vast treasure trove of data into the hands of the people that need it.
Summary Organizations of all sizes are striving to become data driven, starting in earnest with the rise of big data a decade ago. With the never-ending growth in data sources and methods for aggregating and analyzing them, the use of data to direct the business has become a requirement. Randy Bean has been helping enterprise organizations define and execute their data strategies since before the age of big data.
Summary Organizations of all sizes are striving to become data driven, starting in earnest with the rise of big data a decade ago. With the never-ending growth in data sources and methods for aggregating and analyzing them, the use of data to direct the business has become a requirement. Randy Bean has been helping enterprise organizations define and execute their data strategies since before the age of big data.
Machine learning on real-time data is a powerful combination because you gain direct insights into your data, can make powerful decisions, and consequently improve your business processes and outcomes. It […].
Introduction Setup Common Table Expressions (CTEs) Performance comparison CTE Subquery and derived tables Temp table Trade-offs Tear down Conclusion References Introduction If you are a student, analyst, engineer, or anyone in the data space and are Wondering what CTEs are? Trying to understand CTE performance Then this post is for you. In this post, we go over what CTEs are and compare their performance to the subquery, derived table, and temp table.
Modak, a leading provider of modern data engineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera Data Engineering (CDE) integration with Modak Nabu. Modak’s Nabu is a born in the cloud, cloud-neutral integrated data engineering platform designed to accelerate the journey of enterprises to the cloud.
by Joel Sole, Mariana Afonso, Lukas Krasula, Zhi Li, and Pulkit Tandon Introducing the banding artifacts detector developed by Netflix aiming at further improving the delivered video quality Banding artifacts can be pretty annoying. But, first of all, you may wonder, what is a banding artifact? Banding artifact? You are at home enjoying a show on your brand-new TV.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Many Oracle Database customers currently still leverage Oracle 12c or 18c in their production environments, with some even using Oracle 11g. Most of these customers have moved to 19c or […].
Introduction Prerequisites 6 Key Concepts 1. When to Use 2. Partition By 3. Order By 4. Function 5. Lead and Lag 6. Rolling Window Efficiency Considerations Conclusion Further reading References Introduction If work with data, window functions can significantly level up your SQL skills.
We’re excited to announce the availability of CDP Public Cloud Regional Control Plane in Australia and Europe. This addition will extend CDP Hybrid capabilities to customers in industries with strict data protection requirements by allowing them to govern their data entirely in-region. CDP’s public cloud architecture is designed to ensure that customer data remains within a customer’s environment at all times, helping enable companies to meet their data protection obligations, including any rest
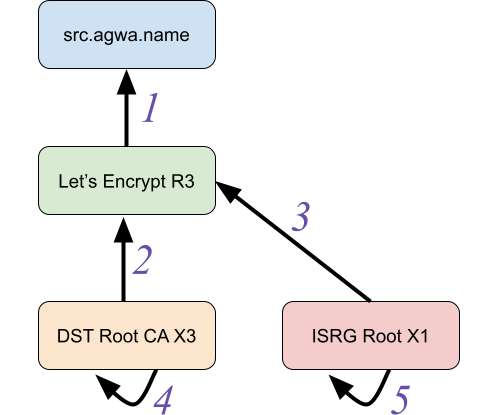
By Ian Haken Last year the AddTrust root certificate expired and lots of clients had a bad time. Some Roku devices weren’t working right, Heroku had problems , and some folks couldn’t even curl. In the aftermath Ryan Sleevi wrote a really great blog post not just about the issue of this one certificate’s expiry, but the problem that so many TLS implementations have in general with certificate path building.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
A DataOps implementation project consists of three steps. First, you must understand the existing challenges of the data team, including the data architecture and end-to-end toolchain. Second, you must establish a definition of “done.” In DataOps, the definition of done includes more than just some working code. It considers whether a component is deployable, monitorable, maintainable, reusable, secure and adds value to the end-user or customer.
Introduction Responsibilities of a data engineer 1. Move data between systems 2. Manage data warehouse 3. Schedule, execute, and monitor data pipelines 4. Serve data to the end-users 5. Data strategy for the company 6. Deploy ML models to production Conclusion Further reading Introduction Data engineering is a relatively new field, and as such, there is a huge variance in the actual job responsibilities across different companies.
As organizations wrangle with the explosive growth in data volume they are presented with today, efficiency and scalability of storage become pivotal to operating a successful data platform for driving business insight and value. Apache Ozone is a distributed, scalable, and high performance object store, available with Cloudera Data Platform Private Cloud.
Data engineering salon. News and interesting reads about the world of data. Cloudflare’s Disruption Ben Thompson, Stratechery S3’s margin is R2’s opportunity. Operations is not Developer IT Mathew Duggan, DevOps Manager, GAN Integrity It's not their fault, they were told this was easy. How Big Tech Runs Tech Projects and the Curious Absence of Scrum Gergely Orosz A survey of how tech projects run across the industry highlights Scrum being absent from Big Tech.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
For many organizations, the advantages of a cloud-based database are clear. They offer scalability, security, and availability. There can also be cost savings over custom and on-premises database solutions. However, not all cloud databases are created equal. Terms like IaaS, PaaS and SaaS have traditionally been used to describe various levels of cloud computing, but how do they apply to cloud databases?
Introduction Skills 1. SQL 2. Python 3. Leetcode: data structures and algorithms 4. Data modeling 4.1 Data warehousing 4.2 OLTP 5. Data pipelines 6. Distributed system fundamentals 7. Event streaming 8. System design 9. Business questions 10. Cloud computing 11. Probabilistic data structures (optional) Interview prep, the TL;DR version Conclusion Introduction Are you a student, analyst, engineer, or someone preparing for a data engineering interview and overwhelmed by all the tools and concepts?
As we continue to celebrate Hispanic Heritage Month, we’d like to shine a spotlight on yet another one of Cloudera’s high performing employees who contributes to the culture and community both in and outside of the Cloudera walls. . Meet Bryan Bottinelli, a 2 year Clouderan and first generation American with roots in Colombia and Chile. . As a Commercial Account Manager, he spends his work days growing the adoption of Cloudera Data Platform (CDP) in the Great Lakes region.
Linear and logistic regression models in machine learning mark most beginners’ first steps into the world of machine learning. Whether you want to understand the effect of IQ and education on earnings or analyze how smoking cigarettes and drinking coffee are related to mortality, all you need is to understand the concepts of linear and logistic regression.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Managing data in a front-end framework is an infinitely solved problem. Every framework has its own flavor, architecture, and opinions on how state should flow; NextJS does not. They provide a variety of methods for data fetching but offers no in-built patterns for data management. On one hand, it doesn't seem unreasonable; NextJS simply expands on React.
This is the third and last part of our journey to roll out SRE in Zalando. You’ll find the previous chapters here and here. Thanks for following our story. 2020 - From team to department The road so far: 2016 saw an attempt at the rollout of a Site Reliability Engineering (SRE) organization that did not quite materialize but still left the seed of SRE in the company; in 2018 and 2019 we had a single SRE team working on strategic projects that improved the reliability of Zalando’s platform.
Quite often, the digital natives of the family — you — have to explain to the analog fans of the family what PDFs are, how to use a hashtag, a phone camera, or a remote. Imagine if you had to explain what machine learning is and how to use it. There’s no need to panic. Cloudera produced a series of ebooks — Production Machine Learning For Dummies , Apache NiFi For Dummies , and Apache Flink For Dummies (coming soon) — to help simplify even the most complex tech topics.
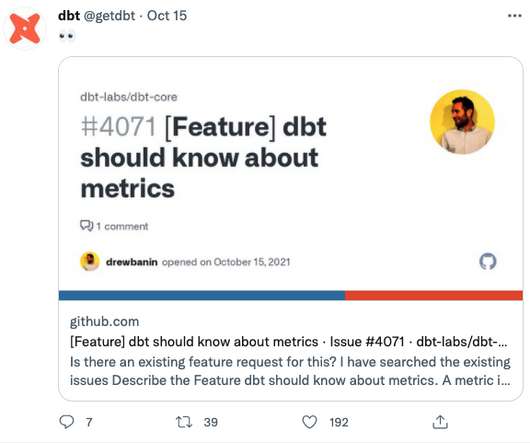
Hello there, While I have a lot of fun things to share this month, I can't start with anything other than this: Yep, it's official: ? dbt will support metric definitions ? With this feature, you'll be able to centrally define rules for aggregating metrics (think, "active users" or "MRR") in version controlled, tested, documented dbt project code. We still have a ways to go, but in future, you'll be able to explore these metrics in the BI and analytics tools that you know and love.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
dbt is an amazing way to transform data within a data warehouse. So amazing, in fact, that it’s easy to end up doing tons and tons of transformations on all kinds of datasets. After a while, it can become an innavigable collection of overlapping tables. That’s a problem when it comes time to troubleshoot. If you use Datakin to observe your dbt models as they run, you can always know exactly where your datasets came from and how they were created.
Photo by Nick Fewings on Unsplash By: Tony Tamplin After years of growth and development on evolving products, Afterpay decided it was time to apply the knowledge accumulated and create a consistent and focused direction across all products. One part of that plan involved rebuilding the website from the ground up to provide features and performance that Afterpay’s users deserve.
On behalf of the entire company, I’m excited to announce the release of Data Quality Fundamentals: A Practitioner’s Guide to Building More Trustworthy Data Pipelines , published by O’Reilly Media and available for free on the Monte Carlo website. This is the first book published by O’Reilly to educate the market on how best-in-class data teams design and architect technical systems to achieve trustworthy and reliable data at scale.
Telcos, their customers, & a range of enterprises are entering a period of experimentation with 5G. The opportunities for innovation & growth are immense – but the costs & risks are outsized too.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content