This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
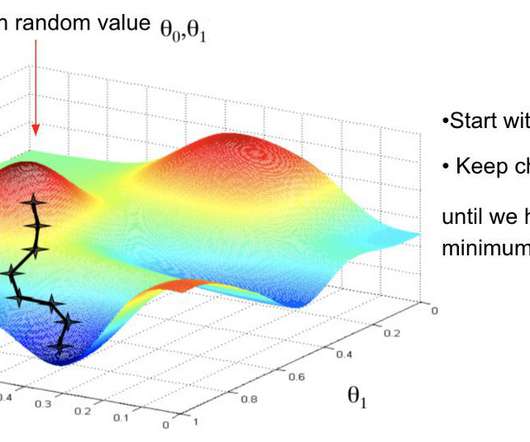
Why is Gradient Descent so important in Machine Learning? Learn more about this iterative optimization algorithm and how it is used to minimize a loss function.
Summary Any business that wants to understand their operations and customers through data requires some form of pipeline. Building reliable data pipelines is a complex and costly undertaking with many layered requirements. In order to reduce the amount of time and effort required to build pipelines that power critical insights Manish Jethani co-founded Hevo Data.
How gaming enterprises like Sony and Big Fish Games use Apache Kafka®, Confluent, and ksqlDB’s data streaming technologies for the best in-game experience, ROI, and real-time capabilities.
Apache Ozone is a distributed, scalable, and high-performance object store , available with Cloudera Data Platform (CDP), that can scale to billions of objects of varying sizes. It was designed as a native object store to provide extreme scale, performance, and reliability to handle multiple analytics workloads using either S3 API or the traditional Hadoop API.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Summary Data engineering systems are complex and interconnected with myriad and often opaque chains of dependencies. As they scale, the problems of visibility and dependency management can increase at an exponential rate. In order to turn this into a tractable problem one approach is to define and enforce contracts between producers and consumers of data.
How banks and finance companies use Confluent to transform their digital systems with event-driven architecture, real-time payment processing, fraud detection, and analytics.
How banks and finance companies use Confluent to transform their digital systems with event-driven architecture, real-time payment processing, fraud detection, and analytics.
Cloudera Contributor: Mark Ramsey, PhD ~ Globally Recognized Chief Data Officer. July brings summer vacations, holiday gatherings, and for the first time in two years, the return of the Massachusetts Institute of Technology (MIT) Chief Data Officer symposium as an in-person event. The gathering in 2022 marked the sixteenth year for top data and analytics professionals to come to the MIT campus to explore current and future trends.
In this article, we will discuss the importance of large language models and suggest some of the top open source models and the NLP tasks they can be used for.
Why do people cherry pick into upper branches? The simplest branching strategy for making code changes to your dbt project repository is to have a single main branch with your production-level code. To update the main branch, a developer will: Create a new feature branch directly from the main branch Make changes on said feature branch Test locally When ready, open a pull request to merge their changes back into the main branch If you are just getting started in dbt and deciding which branchin
Reading Time: 2 minutes TensorFlow Lite is TensorFlow’s lightweight solution for mobile and embedded devices. It allows you to run machine learning models on edge devices with low latency, eliminating the need for a server. After the development of the TensorFlow model, we can convert the same to a more efficient and smaller version by converting it into a Tflite model format.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
A key part of business is the drive for continual improvement, to always do better. “Better” can mean different things to different organizations. It could be about offering better products, better services, or the same product or service for a better price or any number of things. Fundamentally, to be “better” requires ongoing analysis of the current state and comparison to the previous or next one.
Robinhood was founded on a simple idea: that our financial markets should be accessible to all. With customers at the heart of our decisions, Robinhood is lowering barriers and providing greater access to financial information and investing. Together, we are building products and services that help create a financial system everyone can participate in.
RegTech is the word on everyone’s lips as financial services businesses look for ways to manage the avalanche of regulatory reporting precipitated by the 2008 financial crisis.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Learn how stream data technologies are used for fraud detection, real-time analytics, and how Fortune 100 companies are using solutions like Apache Kafka® to accelerate innovation.
Standard Deviation is one of the most underrated statistical tools out there. It’s an extremely useful metric that most people know how to calculate but very few know how to use effectively.
Monte Carlo is a company that has put considerable time, energy, and thought into creating awesome employee experiences. One of our core principles from the start has been to meet talent where they are and build the company around them rather than vice versa. Today, we have over 150 employees spread across 13 states and 9 countries with offices in San Francisco, Santa Cruz, London, Dublin, Tel Aviv, and New York–we are truly a remote first team!
At Teradata, we are committed to operating a business that takes a responsible view of our impact on society and the planet. Find out how we are living this commitment everyday.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
The challenges Customer expectations and the corresponding demands on applications have never been higher. Users expect applications to be fast, reliable, and available. Further, data is king, and users want to be able to slice and dice aggregated data as needed to find insights. Users don't want to wait for data engineers to provision new indexes or build new ETL chains.
By themselves, these data points will probably not provide much insight into a single customer. However, a company that has some or all of this information is well-positioned to have a strong idea of how legitimate its visitors are.
A year after the IPO, Confluent’s sales operations team is still growing at an extraordinary rate in EMEA. Learn what it’s like to work with us, and what the team’s achieving together.
Introduction to Cybersecurity . Cyber safety is securing internet-connected systems such as servers, networks, mobile devices, electronic systems, and data against hostile assaults. We may divide the term “cybersecurity” into two words: cyber and security. The former encompasses systems, networks, programs, and data, while the latter is concerned with safeguarding networks, applications, and data. .
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
How to analyze dataset performance and schema changes in Databand Eric Jones 2022-09-12 13:06:42 “Why did my dataset schema change?” Yeah, we hear this question a lot too. Unfortunately, most data engineers don’t realize the schema has changed until someone else downstream tells them. By then, the business impact has already happened. Databand helps fix this problem by capturing the metadata from your datasets and then alerting you when dataset operations change unexpectedly.
The field of data engineering has been growing at a breakneck pace. New frameworks, new challenges, and new technologies are constantly shifting how engineers think about their work and their roles within their organizations. Keeping up with the latest developments can feel like a full-time job—so we’re always grateful when seasoned leaders share their perspectives on which trends in data engineering actually matter.
. Introduction . Learning IT fundamentals for Cyber Security is a must in present times. Rampant cyber attacks due to mass-scale digitization of business are a major nuisance, and Cyber Security awareness is the only solution. . . A cyber-attack is an offensive action targeting computer networks or devices. A cyber-attack can be carried out by individuals, groups, or even nation-states and can range from relatively unsophisticated attacks to highly sophisticated operations that can cause
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
This article is brought to you by Mark Rudolph - his second contribution to Rock the JVM. Mark is a senior developer, who has been working with Scala for a number of years. He also has been diving into the ZIO ecosystem, and loves sharing his learnings. If you want to learn more about the core ZIO library, check out the ZIO course. If you want the video version, check below: Outline In this post, we’re going to go over an introduction to the zio-http library, and take a look at some of the basic
TransformX by Scale AI is happening on October 19th - 21st. Don't miss this opportunity to learn from leading AI and ML experts across industries. Registration is free and the conference is virtual with one day in-person at SF Jazz.
This post will look at a few different ways of attempting to simplify decision tree representation and, ultimately, interpretability. All code is in Python, with Scikit-learn being used for the decision tree modeling.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content