This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1. Introduction 2. Project demo 3. TL;DR 4. Building efficient data pipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Use DuckDB 4.4. Distributed systems are scalable, resilient to failures, & designed for high availability 4.5.
Of all the duties that Data Engineers take on during the regular humdrum of business and work, it’s usually filled with the same old, same old. Build new pipeline, update pipeline, new data model, fix bug, etc, etc. It’s never-ending. It’s a constant stream of data, new and old, spilling into our Data Warehouses and […] The post Building Data Platforms (from scratch) appeared first on Confessions of a Data Guy.
Robinhood Crypto customers in the United States can now use our API to view crypto market data, manage portfolios and account information, and place crypto orders programmatically Today, we are excited to announce the Robinhood Crypto trading API , ushering in a new era of convenience, efficiency, and strategy for our most seasoned crypto traders. Robinhood Crypto customers in the United States can use our new trading API to set up advanced and automated trading strategies that allow them to st
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
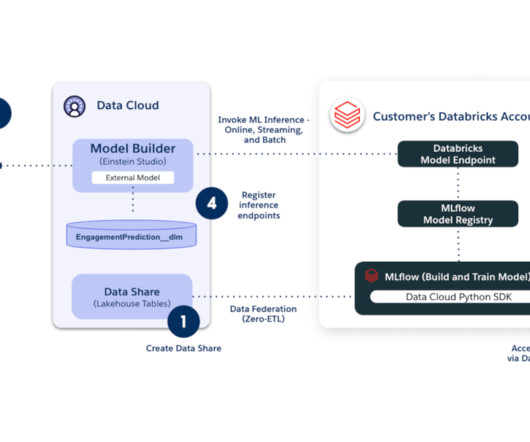
Salesforce and Databricks are excited to announce an expanded strategic partnership that delivers a powerful new integration - Salesforce Bring Your Own Model.
How companies data model varies widely. They might say they use Kimball dimensional modeling. However, when you look in their data warehouse the only part you recognize is the word fact and dim. Over the past near decade, I have worked for and with different companies that have used various methods to capture this data.… Read more The post How To Data Model – Real Life Examples Of How Companies Model Their Data appeared first on Seattle Data Guy.
Last week I was speaking in Gdansk on the DataMass track at Infoshare. As it often happens, the talk time slot impacted what I wanted to share but maybe it's for good. Otherwise, you wouldn't read stream processing fallacies!
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Many data engineers and analysts don’t realize how valuable the knowledge they have is. They’ve spent hours upon hours learning SQL, Python, how to properly analyze data, build data warehouses, and understand the differences between eight different ETL solutions. Even what they might think is basic knowledge could be worth $10,000 to $100,000+ for a… Read more The post Why Data Analysts And Engineers Make Great Consultants appeared first on Seattle Data Guy.
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. Sriram Panyam has been involved in several projects that required migration of large volumes of data in high traffic environments. In this episode he shares some of the valuable lessons that he learned about how to make those projects successful.
We’re excited to announce today that we’re reinforcing our commitment and deepening our partnership with Sigma with an expanded investment from Snowflake Ventures. Sigma is a leading business intelligence and analytics solution that makes it easy for employees to explore live data, create compelling visualizations and collaborate with colleagues. Sigma allows employees to break free of dashboards and build workflows, powered by write-back to Snowflake through their unique Input Tables capability
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
The annual Data Team Awards celebrate the critical contributions of data teams to various sectors, spotlighting their role in driving progress and positive.
The AI Data Cloud unlocks the power of data for technical and non-technical users alike, including data analysts, data scientists, data engineers and business users. When employees can collaborate seamlessly to generate new insights, share findings and create efficient workflows, organizations can drive even more efficiency, unlocking value from their data, faster.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
It’s hard to have a conversation in adtech today without hearing the words, “retail media.” The retail media wave is in full force, piquing the interest of any company with a strong, first-party relationship with consumers. Companies are now understanding the value of their data and how that data can power a new, high-margin media business. The two-sided network that exists between retailers and their brands turns into a flywheel for growth.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
In Part 1 of “Retail Media’s Business Case for Data Clean Rooms,” we discussed how to (1) assess your data assets and (2) define your data structures and permissions. Once you have a plan on paper, you can begin sizing the data clean room opportunity for your business. Step 3: Commercial Models to Unlock Revenue at Scale Modeling the business value comes down to two things: (1) What data are you making accessible; and (2) How many partners are you willing (and able) to engage?
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
The board of directors of Robinhood Markets, Inc. (“Robinhood”) (NASDAQ: HOOD) has authorized a $1 billion share repurchase program, demonstrating management and the board’s confidence in Robinhood’s financial strength and future growth prospects. “As our business and cash flow have continued to grow, we’re excited to announce a $1 billion share repurchase program to return value to shareholders,” said Jason Warnick, Chief Financial Officer of Robinhood.
Explore how to build, trigger and parameterize a time-series data pipeline in Azure, accompanied by a step-by-step tutorial Continue reading on Towards Data Science »
Everybody sees a dream—aspiring to become a doctor, astronaut, or anything that fits your imagination. If you were someone who had a keen interest in looking for answers and knowing the “why” behind things, you might be a good fit for research. Further, if this interest revolved around computers and tech, you would be an excellent computer researcher!
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content