This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where data pipeline design patterns come in.
There are plenty of statistics about the speed at which we are creating data in today’s modern world. On the flip side of all that data creation is a need to manage all of that data and thats where data teams come in. But leading these data teams is challenging and yet many new data… Read more The post From IC to Data Leader: Key Strategies for Managing and Growing Data Teams appeared first on Seattle Data Guy.
Today’s business landscape is increasingly competitive — and the right data platform can be the difference between teams that feel empowered or impaired. I love talking with leaders across industries and organizations to hear about what’s top of mind for them as they evaluate various data platforms. In these conversations, there are a number of questions that I hear time and time again: Will my data platform be scalable and reliable enough?
Key Takeaways: Data integrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Data quality and data governance are the top data integrity challenges, and priorities. A long-term approach to your data strategy is key to success as business environments and technologies continue to evolve. The rapid pace of technological change has made data-driven initiatives more crucial than ever within modern business strategies.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
In my never-ending quest to plumb the most boring depths of every single data tool on the market, I found myself annoyed when recently using DuckDB for a benchmark that was reading parquet files from s3. What was not clear, or easy, was trying to figure out how DuckDB would LIKE to read default AWS […] The post DuckDB … reading from s3 … with AWS Credentials and more. appeared first on Confessions of a Data Guy.
Scraping data from PDFs is a right of passage if you work in data. Someone somewhere always needs help getting invoices parsed, contracts read through, or dozens of other use cases. Most of us will turn to Python and our trusty list of Python libraries and start plugging away. Of course, there are many challenges… Read more The post Challenges You Will Face When Parsing PDFs With Python – How To Parse PDFs With Python appeared first on Seattle Data Guy.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases.
Key Takeaways: Harness automation and data integrity unlock the full potential of your data, powering sustainable digital transformation and growth. Data and processes are deeply interconnected. Successful digital transformation requires you to optimize both so that they work together seamlessly. Simplify complex SAP® processes with automation solutions that drive efficiency, reduce costs, and empower your teams to act quickly.
For over 20 years, Skyscanner has been helping travelers plan and book trips with confidence— including airfare, hotels, and car rentals. As digital natives, the organization is no stranger to staggering volume. Over the years, Skyscanner has grown organically to include a vast network of high-volume data producers and consumers, including: Serving over 110 million monthly users Partnering with hundreds of travel providers Operating in 30+ languages and 180 countries An fulfilling over 5,000
We are thrilled to unveil the finalists for the Databricks Generative AI Startup Challenge , a competition designed to spotlight innovative early-stage startups.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Key Takeaways: Data integrity is required for AI initiatives, better decision-making, and more – but data trust is on the decline. Data quality and data governance are the top data integrity challenges, and priorities. A long-term approach to your data strategy is key to success as business environments and technologies continue to evolve. The rapid pace of technological change has made data-driven initiatives more crucial than ever within modern business strategies.
For over 20 years, Skyscanner has been helping travelers plan and book trips with confidence— including airfare, hotels, and car rentals. As digital natives, the organization is no stranger to staggering volume. Over the years, Skyscanner has grown organically to include a vast network of high-volume data producers and consumers, including: Serving over 110 million monthly users Partnering with hundreds of travel providers Operating in 30+ languages and 180 countries An fulfilling over 5,000
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQL Databases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake. This fully managed service leverages Striim Cloud’s integration with the Microsoft Fabric stack for seamless data mirroring to Fabric Data Warehouse and Lake House.
We’re excited to announce a new integration between Databricks Notebooks and AI/BI Dashboards, enabling you to effortlessly transform insights from your notebooks into.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
1. Introduction 2. Analytical databases aggregate large amounts of data 3. Most platforms enable you to do the same thing but have different strengths 3.1. Understand how the platforms process data 3.1.1. A compute engine is a system that transforms data 3.1.2. Metadata catalog stores information about datasets 3.1.3. Data platform support for SQL, Dataframe, and Dataset APIs 3.1.4.
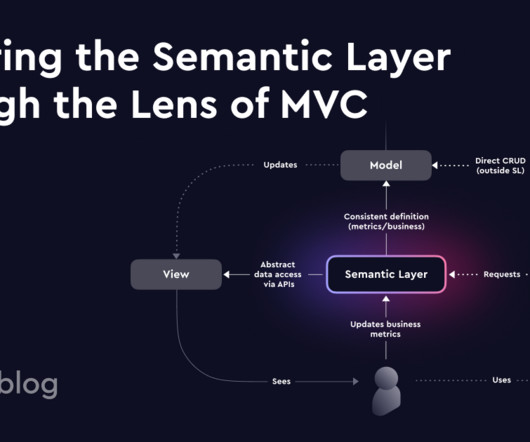
MVC is an interesting concept from the late 70s that separates the View (presentation) from the Controller via the Model. It has been used in designing web applications and is still heavily used, for example, in Ruby on Rails or Laravel, a popular PHP framework. This design pattern got me thinking: Wouldn’t it be convenient to separate the presentation from the storage through a data modeling layer, similar to the model layer?
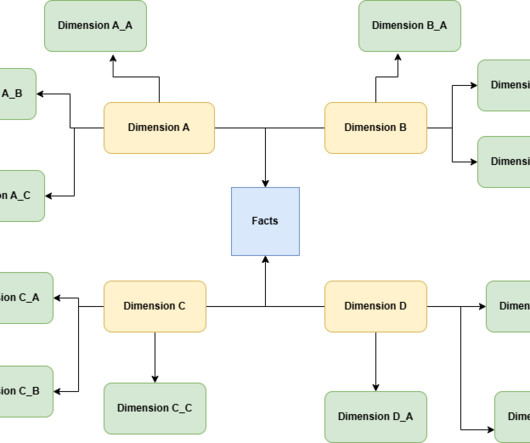
In today’s data-driven world, choosing the right schema to store data is equally important as collecting it. Schema design plays a crucial role in the performance, scalability, and usability of your data systems. Different data use cases require the selection of different schema designs.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
We are excited to introduce the gated Public Preview of Predictive Optimization for statistics. Announced at the Data + AI Summit, Predictive Optimization.
Confluent’s CwC partner program introduces bidirectional data streaming for SAP Datasphere, powered by Apache Kafka and Apache Flink; CwC Q4 2024 new entrants.
In the modern field of data analytics, proper data management is the only way to maximize performance while minimizing costs. Google BigQuery, one of the leading cloud-based data warehouses, shows great skills in managing huge datasets by partitioning and clustering.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We’re excited to announce that the Databricks Assistant , now fully hosted and managed within Databricks, is available in public preview! This version.
CDC has evolved to become a key component of data streaming platforms, and is easily enabled by managed connectors such as the Debezium PostgreSQL CDC connector.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































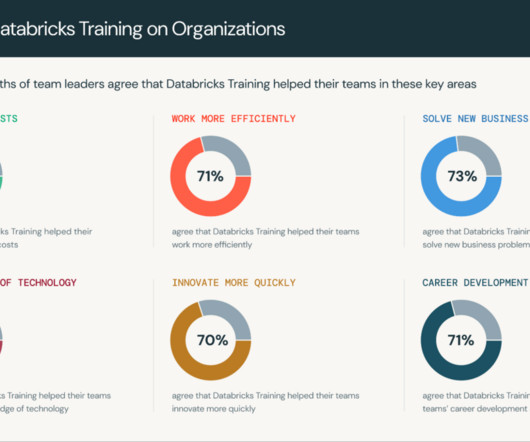








Let's personalize your content