This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1. Introduction 2. Run Data Pipelines 2.1. Run on codespaces 2.2. Run locally 3. Projects 3.1. Projects from least to most complex 3.2. Batch pipelines 3.3. Stream pipelines 3.4. Event-driven pipelines 3.5. LLM RAG pipelines 4. Conclusion 1. Introduction Whether you are new to data engineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up!
This video covers the latest announcements from StreamNative, Confluent, and WarpStream. We discuss communication protocols, how they’re used, and what they mean for you. We also discuss the various systems using Kafka’s protocol. Finally, we discuss the announcements about writing to Iceberg and DeltaLake directly from the broker and what that means for costs and operational ease.
Summary Streaming data processing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. To address this shortcoming Datorios created an observability platform for Flink that brings visibility to the internals of this popular stream processing system. In this episode Ronen Korman and Stav Elkayam discuss how the increased understanding provided by purpose built observability improves the usefulness
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
As we continue to focus our AI research and development on solving increasingly complex problems, one of the most significant and challenging shifts we’ve experienced is the sheer scale of computation required to train large language models (LLMs). Traditionally, our AI model training has involved a training massive number of models that required a comparatively smaller number of GPUs.
As we continue to focus our AI research and development on solving increasingly complex problems, one of the most significant and challenging shifts we’ve experienced is the sheer scale of computation required to train large language models (LLMs). Traditionally, our AI model training has involved a training massive number of models that required a comparatively smaller number of GPUs.
Over the last year, we have seen a surge of commercial and open-source foundation models showing strong reasoning abilities on general knowledge tasks.
Meta is currently operating many data centers with GPU training clusters across the world. Our data centers are the backbone of our operations, meticulously designed to support the scaling demands of compute and storage. A year ago, however, as the industry reached a critical inflection point due to the rise of artificial intelligence (AI), we recognized that to lead in the generative AI space we’d need to transform our fleet.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Discovering and surfacing telemetry traditionally can be a tedious and challenging process, especially when it comes to pinpointing specific issues for debugging. However, as applications and pipelines grow in complexity, understanding what’s happening beneath the surface becomes increasingly crucial. A lack of visibility hinders the development and maintenance of high-quality applications and pipelines, ultimately impacting customer experience.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Today’s data-driven world requires an agile approach. Modern data teams are constantly under pressure to deliver innovative solutions faster than ever before. Fragmented tooling across data engineering, application development and AI/ML development creates a significant bottleneck, hindering the speed of value delivery required to stay competitive.
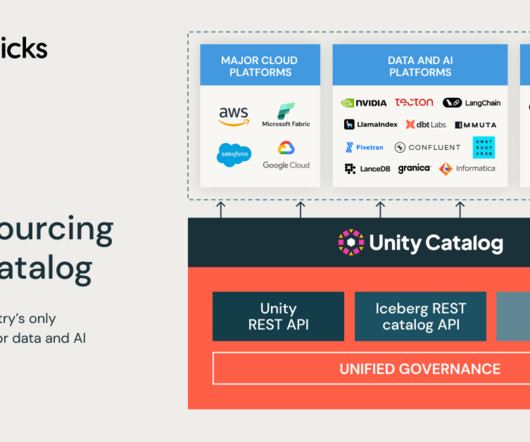
Today, we are excited to announce Databricks LakeFlow, a new solution that contains everything you need to build and operate production data pipelines.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
The journey toward achieving a robust data platform that secures all your data in one place can seem like a daunting one. But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective data ingestion to help bring your workloads into the AI Data Cloud with ease. Snowflake is launching native integrations with some of the most popular databases, including PostgreSQL and MySQL.
Data privacy has been a long-standing issue that continues to challenge the data industry. Let’s understand how rapid developments in the world of AI have elevated data privacy concerns.
At Meta, Bento , our internal Jupyter notebooks platform, is a popular tool that allows our engineers to mix code, text, and multimedia in a single document. Use cases run the entire spectrum from what we call “lite” workloads that involve simple prototyping to heavier and more complex machine learning workflows. However, even though the lite workflows require limited compute, users still have to go through the same process of reserving and provisioning remote compute – a process that takes time
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Bringing machine learning (ML) models into production is often hindered by fragmented MLOps processes that are difficult to scale with the underlying data. Many enterprises stitch together a complex mix of various MLOps tools to build an end-to-end ML pipeline. The friction of having to set up and manage separate environments for features and models creates operational complexity that can be costly to maintain and difficult to use.
“FactSet’s mission is to empower clients to make data-driven decisions and supercharge their workflows and productivity. To deliver AI-driven solutions across our entire.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Learn More → Cube Research: Crystallizing Snowflake Summit 2024 We should officially call the first week of June the data engineering week, as two major data companies are running their developer conference.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
It is estimated that between 80% and 90% of the world’s data is unstructured 1 , with text files and documents making up a significant portion. Every day, countless text-based documents, like contracts and insurance claims, are stored for safekeeping. Despite containing a wealth of insights, this vast trove of information often remains untapped, as the process of extracting relevant data from these documents is challenging, tedious and time-consuming.
Hadoop. The first time that I really became familiar with this term was at Hadoop World in New York City some ten or so years ago. There were thousands of attendees at the event – lining up for book signings and meetings with recruiters to fill the endless job openings for developers experienced with MapReduce and managing Big Data. This was the gold rush of the 21st century, except the gold was data.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content