This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snowflake leaders offer insight on AI, open source and cybersecurity development — and the fundamental leadership skills required — in the years ahead. As we come to the end of a calendar year, it’s natural to contemplate what the new year will hold for us. It’s an understatement to say that the future is very hard to predict, but it’s possible to both prepare for the likeliest outcomes and stay ready to adapt to the unexpected.
Well, everyone is abuzz with the recently announced S3 Tables that came out of AWS reinvent this year. I’m going to call fools gold on this one right out of the gate. I tried them out, in real life that is, not just some marketing buzz, and it will leave most people, not all, be […] The post AWS S3 Tables. Technical Introduction. appeared first on Confessions of a Data Guy.
For more than a decade, Cloudera has been an ardent supporter and committee member of Apache NiFi, long recognizing its power and versatility for data ingestion, transformation, and delivery. Our customers rely on NiFi as well as the associated sub-projects (Apache MiNiFi and Registry) to connect to structured, unstructured, and multi-modal data from a variety of data sources – from edge devices to SaaS tools to server logs and change data capture streams.
As we approach 2025, data teams find themselves at a pivotal juncture. The rapid evolution of technology and the increasing demand for data-driven insights have placed immense pressure on these teams. According to recent research, 95% of data teams are operating at or over capacity, highlighting the urgent need for strategic preparation. This isn’t just about keeping up; it’s about staying ahead so that data teams can deliver the data needed to fuel their organizations.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Artificial Intelligence promises to transform lives and business as we know it. But what does that future look like? The AI Forecast: Data and AI in the Cloud Era , sponsored by Cloudera, aims to take an objective look at the impact of AI on business, industry, and the world at large. Hosted weekly by Paul Muller, The AI Forecast speaks to experts in the space to understand the ins and outs of AI in the enterprise, the kinds of data architectures and infrastructures that support it, the guardrai
Artificial Intelligence promises to transform lives and business as we know it. But what does that future look like? The AI Forecast: Data and AI in the Cloud Era , sponsored by Cloudera, aims to take an objective look at the impact of AI on business, industry, and the world at large. Hosted weekly by Paul Muller, The AI Forecast speaks to experts in the space to understand the ins and outs of AI in the enterprise, the kinds of data architectures and infrastructures that support it, the guardrai
As we approach 2025, data teams find themselves at a pivotal juncture. The rapid evolution of technology and the increasing demand for data-driven insights have placed immense pressure on these teams. According to recent research, 95% of data teams are operating at or over capacity, highlighting the urgent need for strategic preparation. This isn’t just about keeping up; it’s about staying ahead so that data teams can deliver the data needed to fuel their organizations.
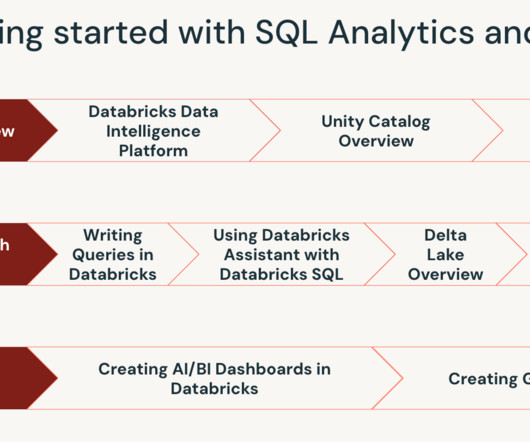
Databricks launches two new self-paced trainings to enhance SQL and AI-powered analytics skills The "Get Started with SQL analytics and BI" course covers how to use Databricks SQL for data analysis and Databricks AI/BI Dashboards and Genie spaces Additional courses being developed include "Databricks AI/BI for self-service analytics" and a deep dive for data analysts on building AI/BI Dashboards and Genie Spaces
Welcome to the first installment of a series of posts discussing the recently announced Cloudera AI Inference service. Today, Artificial Intelligence (AI) and Machine Learning (ML) are more crucial than ever for organizations to turn data into a competitive advantage. To unlock the full potential of AI, however, businesses need to deploy models and AI applications at scale, in real-time, and with low latency and high throughput.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Data preparation tools are very important in the analytics process. They transform raw data into a clean and structured format ready for analysis. These tools simplify complex data-wrangling tasks like cleaning, merging, and formatting, thus saving precious time for analysts and data teams.
In this article, we’ll go over Python libraries for tasks like logging, unit testing, data handling, and more — each with features that can simplify your application development.
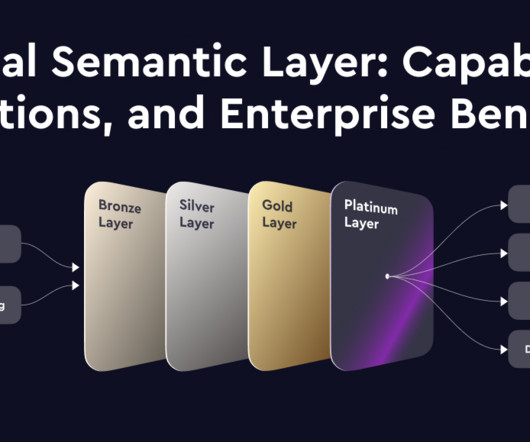
Modern data teams face growing complexity: multiple data sources, various BI tools, and ever-increasing self-service analytics. Organizations must maintain consistency across their metrics while making data accessible to business users. This is where a semantic layer shines: It provides a single source of truth for business metrics while abstracting away the underlying complexity.
Would you like help maintaining high-quality data across every layer of your Medallion Architecture? Like an Olympic athlete training for the gold, your data needs a continuous, iterative process to maintain peak performance. We covered how Data Quality Testing, Observability, and Scorecards turn data quality into a dynamic process, helping you build accuracy, consistency, and trust at each layerBronze, Silver, and Gold.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
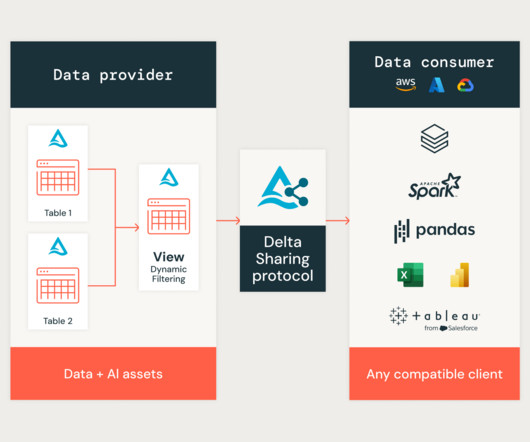
We are excited to announce the Public Preview of Cross-Platform View Sharing. Available today, it allows data providers to share views across different.
MongoDB is a database that’s great for handling large amounts of diverse data. This article walks you through installing MongoDB and using the MongoDB Shell to manage your data easily.
Greetings, dbters! Its Faith & Jerrie, back again to offer tactical advice on where to put tests in your pipeline. In our first post on refining testing best practices, we developed a prioritized list of data quality concerns. We also documented first steps for debugging each concern. This post will guide you on where specific tests should go in your data pipeline.
As one of the most important sectors of the global economy, the food and beverage (F&B) industry works in highly volatile conditions and ensures its success by reducing waste and managing inventories. Managing production and consumption, meeting deadlines, cutting waste, and being environmentally friendly are always a challenge. Old and traditional approaches often fail or become inefficient and unresponsive in real time.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Predictive Optimization (PO) enhances the performance of Unity Catalog managed tables by intelligently optimizing data layouts, leading to significant improvements in query performance.
Data integration is an integral part of modern business strategy, enabling businesses to convert raw data into actionable information and make data-driven decisions. Tools like Apache Airflow are used and popular for workflow automation. However, its technical complexities and steeper learning curve can create a challenge for teams that require an efficient real-time data pipeline.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
The world of artificial intelligence (AI) and data analytics is about to get a significant boost, thanks to Databricks’ collaboration with NVIDIA. This.
How Pinterest Leverages Honeycomb to Enhance CI Observability and Improve CI Build Stability Oliver Koo | Staff Software Engineer Optimizing Mobile Builds and Continuous Integration Observability at Pinterest with Honeycomb At Pinterest, our mobile infrastructure is core to delivering a high-quality experience for our users. In this blog, I’ll showcase how the Pinterest Mobile Builds team is leveraging Honeycomb (starting in 2021) to enhance observability and performance in our mobile builds and
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
As an online grocery retailer, we operate in a complex environment that requires us to adapt on an ongoing basis to changes in customer behavior, our operations, legislation etc. In order to do so adequately, we need to be able to ship changes to our apps often and with little lead time. For example, when the government introduced lockdowns during COVID, we were still allowed to deliver groceries but not alcohol after 20:00, a restriction that came into effect practically overnight.
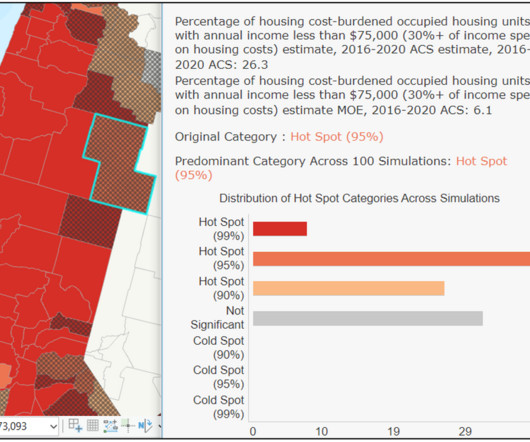
Learn how to analyze uncertainty in your data using spatial statistics tools. Explore patterns of housing burden and make informed decisions with ArcGIS Pro 3.4.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content