10 Built-In Python Modules Every Data Engineer Should Know
KDnuggets
SEPTEMBER 2, 2024
Interested in data engineering? Check out this round-up of built-in Python modules that'll come in handy for data engineering tasks.

KDnuggets
SEPTEMBER 2, 2024
Interested in data engineering? Check out this round-up of built-in Python modules that'll come in handy for data engineering tasks.

Confluent
SEPTEMBER 5, 2024
Dive into Kafka internals with a four-part series examining client requests and brokers. Part 1 covers what a producer does to prepare raw event data for the broker.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

databricks
SEPTEMBER 5, 2024
An improved answer-correctness judge in Agent Evaluation Agent Evaluation enables Databricks customers to define, measure, and understand how to improve the quality of.

Start Data Engineering
SEPTEMBER 4, 2024
1. Introduction 2. Key parts of data systems: 2.1. Requirements 2.2. Data flow design 2.3. Orchestrator and scheduler 2.4. Data processing design 2.5. Code organization 2.6. Data storage design 2.7. Monitoring & Alerting 2.9. Infrastructure 3. Conclusion 1. Introduction If you are trying to break into (or land a new) data engineering job, you will inevitably encounter a slew of data engineering tools.

Advertisement
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate

KDnuggets
SEPTEMBER 6, 2024
A beginner's guide to A/B testing by FAANG data scientists.

Seattle Data Guy
SEPTEMBER 3, 2024
One of the holy grails that many data teams seem to chase is real-time data analytics. After all, if you can have real-time analytics, you can make better decisions faster. However, there often is a conflation between real-time data analytics and stream processing. These are two different concepts that are crucial to understanding how to… Read more The post Real-time Analytics Vs Stream Processing – What Is The Difference?
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

|

Engineering at Meta
SEPTEMBER 4, 2024
We are working in partnership with others to scale inclusive solutions that support the transition to a zero-carbon economy and help create a healthier planet for all.

KDnuggets
SEPTEMBER 5, 2024
A beginner tutorial on building a simple web application for machine learning model inference using FastAPI and Jinja2 templates.

ArcGIS
SEPTEMBER 6, 2024
Learn more about how to use response caching for hosted feature services in ArcGIS Enterprise.

databricks
SEPTEMBER 5, 2024
Maintaining heavy equipment assets, such as oil rigs, agricultural combines, or fleets of vehicles, poses an extremely complex challenge for global companies. These.

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.

Confessions of a Data Guy
SEPTEMBER 4, 2024
Over the many years I’ve been pounding my keyboard … Perl, PHP, Python, C#, Rust … whatever … I, like most programmers, built up a certain disdain for what is called Low Code / No Code solutions. In my rush to worship at the feet of the code we create, I failed, in the beginning, […] The post Streaming Postgres data to Databricks Delta Lake in Unity Catalog appeared first on Confessions of a Data Guy.

KDnuggets
SEPTEMBER 5, 2024
How does AI learn by doing? Read this to discover the basics of reinforcement learning.
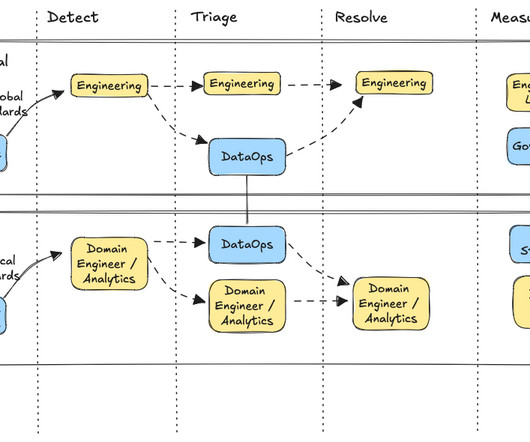
Monte Carlo
SEPTEMBER 6, 2024
I’ve spoken with dozens of enterprise data professionals, and one of the most common data quality questions is, “who does what?” This is quickly followed by, “why and how?” There is a reason for this. Data quality is like a relay race. The success of each leg —detection, triage, resolution, and measurement—depends on the other. Every time the baton is passed, the chances of failure skyrocket.

databricks
SEPTEMBER 5, 2024
We recently announced the General Availability of our serverless compute offerings for Notebooks, Jobs, and Pipelines. Serverless compute provides rapid workload startup, automatic.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.

Confessions of a Data Guy
SEPTEMBER 4, 2024
Polars is the hot new Rust based Python Dataframe tool that is taking over the world and destryoing Pandas even as we speak. You want the quick and dirty introduction to Polars? Look no farther. The post Introduction to Polars in 2 Minutes appeared first on Confessions of a Data Guy.

KDnuggets
SEPTEMBER 3, 2024
Let's see how to perform cross-correlation in NumPy, a method for measuring the similarity or relationship between two sequences of data as one is shifted in relation to the other.

ArcGIS
SEPTEMBER 5, 2024
An Overview of editing schema reports for conversion to XML workspace documents.
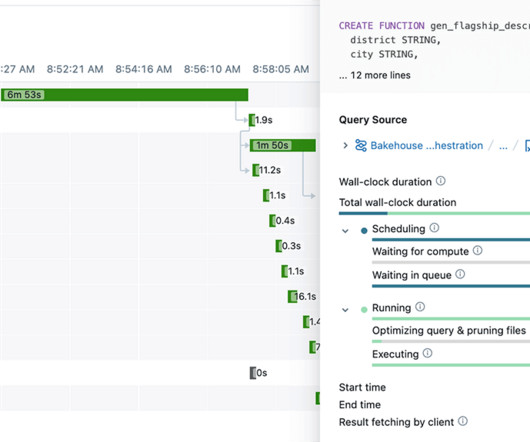
databricks
SEPTEMBER 4, 2024
Data teams spend way too much time troubleshooting issues, applying patches, and restarting failed workloads. It's not uncommon for engineers to spend their.

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
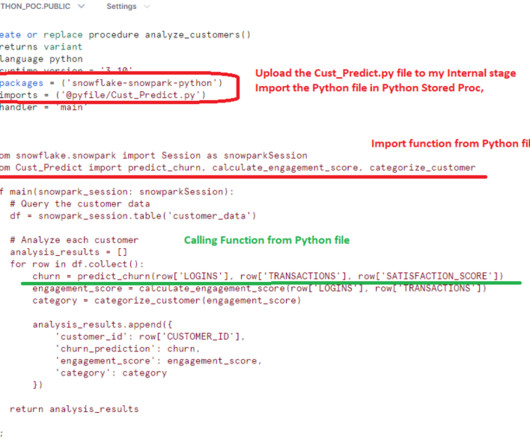
Cloudyard
SEPTEMBER 2, 2024
Read Time: 1 Minute, 36 Second Snowflake’s support for Python stored procedures allows data engineers and scientists to leverage Python’s vast ecosystem directly within Snowflake. This capability enables advanced analytics, custom data processing, and seamless integration of Python libraries. One particularly powerful feature is the ability to import and use Python files (.py) directly within a Snowflake stored procedure, which promotes code modularity, reusability, and better organi
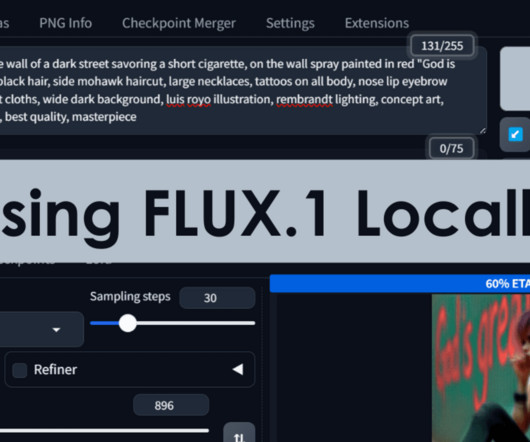
KDnuggets
SEPTEMBER 6, 2024
Learn how to install Stable Diffusion WebUI Forge easily and set up the FLUX.1 [dev] model for local use on a laptop.

Scott Logic
SEPTEMBER 4, 2024
Our team had previously built a tool to investigate code quality from PR data. Building on this work, we set about finding a method to detect AI-written code, so we could investigate any potential differences in code quality between human and AI-written code. During our time on this project, we learnt some important lessons, including just how hard it can be to detect AI-written code, and the importance of good-quality data when conducting research.

databricks
SEPTEMBER 1, 2024
Terms like “data governance,” “Generative AI” and “large language models” are becoming commonplace in the workplace. But for business leaders, it takes more.

Advertisement
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you

Towards Data Science
SEPTEMBER 3, 2024
Understand how batch can be considered a subset of streaming and why data engineering should simplify its usage significantly Continue reading on Towards Data Science »

KDnuggets
SEPTEMBER 4, 2024
Here are five must-know R packages for data analysis in R.

Hevo
SEPTEMBER 4, 2024
A data warehouse is a centralized system that stores, integrates, and analyzes large volumes of structured data from various sources. It is predicted that more than 200 zettabytes of data will be stored in the global cloud by 2025.

databricks
SEPTEMBER 2, 2024
Rivian chose to modernize its data infrastructure on the Databricks Data Intelligence Platform, giving it the ability to unify all of its data into a common view for downstream analytics and machine learning.

Speaker: Tamara Fingerlin, Developer Advocate
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!

Towards Data Science
SEPTEMBER 1, 2024
Data Mesh trends in data platform design Continue reading on Towards Data Science »
KDnuggets
SEPTEMBER 4, 2024
Check out this list of resources for different types of interviews.

Confluent
SEPTEMBER 5, 2024
Confluent’s CwC partner program turns one year old and new program entrants for Q3 2024.

databricks
SEPTEMBER 1, 2024
Within the Databricks Community, there is a technical blog where community members share best practices, tutorials and insights on data analytics, data engineering.

Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m

Expert insights. Personalized for you.






Let's personalize your content