This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. But when data processes fail to match the increased demand for insights, organizations face bottlenecks and missed opportunities.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction. This counting service, built on top of the TimeSeries Abstraction, enables distributed counting at scale while maintaining similar low latency performance.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights. Before building your own data architecture from scratch though, why not steal – er, learn from – what industry leaders have already figured out?
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These new tools streamline workflows, deliver insights at scale, and get AI apps into production quickly. Customers such as Skai have used these capabilities to bring their generative AI solution into production in just two days instead of months.
Large Language Models (LLMs) will be at the core of many groundbreaking AI solutions for enterprise organizations. Here are just a few examples of the benefits of using LLMs in the enterprise for both internal and external use cases: Optimize Costs. LLMs deployed as customer-facing chatbots can respond to frequently asked questions and simple queries.
Much of the data we have used for analysis in traditional enterprises has been structured data. It’s easy for humans to break down, understand, and, in turn, find insights from it. However, much of the data that is being created and will be created comes in some form of unstructured format. However, the digital era… Read more The post What is Unstructured Data?
We are excited to share our latest research paper Retrieve, Annotate, Evaluate, Repeat — Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation. We introduce a novel approach to large-scale product retrieval evaluation using Multimodal Large Language Models (MLLMs). Evaluated on 20,000 examples, our method shows how MLLMs can help automate the relevance assessment of retrieved products, achieving levels of accuracy comparable to human annotators and enabling scalable evaluation
We are excited to share our latest research paper Retrieve, Annotate, Evaluate, Repeat — Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation. We introduce a novel approach to large-scale product retrieval evaluation using Multimodal Large Language Models (MLLMs). Evaluated on 20,000 examples, our method shows how MLLMs can help automate the relevance assessment of retrieved products, achieving levels of accuracy comparable to human annotators and enabling scalable evaluation
This fall, thousands of leaders in the financial services industry gathered at the annual Money 20/20 conference to talk trends in payments, compliance, fraud reduction, treasury and transactions and more. Conversations centered on the theme of “Human x Machine,” and while AI was a focus, there were plenty of other insights around real-time data analytics, security considerations and customer strategies that are guiding the future of money.
We are excited to announce the acquisition of Octopai , a leading data lineage and catalog platform that provides data discovery and governance for enterprises to enhance their data-driven decision making. Cloudera’s mission since its inception has been to empower organizations to transform all their data to deliver trusted, valuable, and predictive insights.
Key Takeaways: Data used for personalization must be of high quality—accurate, up-to-date, and free of redundancies. 4 Practical Tips for Implementing Data-Driven Personalization in your organization. Many organizations struggle with siloed communication channels, which create fragmented customer experiences. How do you convert the everyday customers into loyal brand enthusiasts?
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. While some businesses find ways to stitch together many tools with complex pipelines, wouldn’t it be better if you could remove some of the steps? What if you could streamline your efforts while still building an architecture that best fits your business and technology needs?
The food and beverages (F&B) industry has been transformed digitally, resulting from new technology, including GenAI. In short, GenAI is a type of artificial intelligence that is capable of creating content and offering predictions that have transformed the operations of a business in this industry. In this blog, we will look at some of the approaches GenAI has advanced in food and beverage, supported by relevant research statistics as well as real-life experiences and case studies in detail
Databricks Marketplace is an open marketplace for data, analytics, and AI, powered by the open-source Delta Sharing standard. Since the release of Databricks.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
After a couple of years recapping the excitement of the Snowflake and Databricks conference keynotes, it was beyond time to give the same treatment to the fourth annual IMPACT conference. So let’s take a closer look at the keynote delivered by Monte Carlo co-founder and chief technology officer, Lior Gavish, as he took the virtual stage to share the “vision and mission driving Monte Carlo into 2025.
The media and entertainment sector is being transformed on a new scale owing to technological progression. With artificial intelligence (AI) and the cloud, content production, distribution, and consumption have changed for the better. It’s worth noting that advanced technologies today not only facilitate the production process structure but also improve effectiveness, reduce costs, and create innovativeness.
From Fortune 500 companies processing trillions of security records to innovative startups building interactive data tools, DuckDB is revolutionizing how organizations handle analytical workloads. Building on our exploration of DuckDB’s core capabilities in Part 1 , this guide showcases production implementations and promising experimental applications across five key categories.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
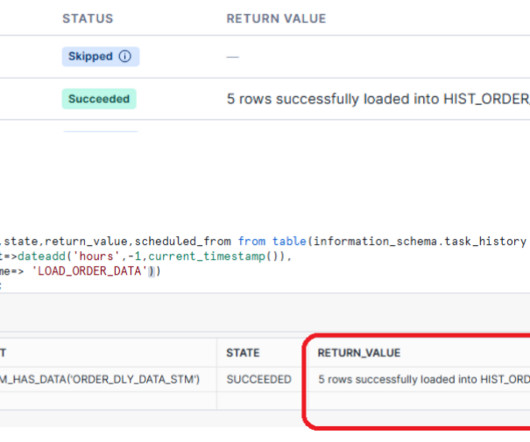
Read Time: 2 Minute, 32 Second Triggered tasks in Snowflake offer a key advantage: they only execute when new data arrives, eliminating the need to run a warehouse or cloud service constantly and reducing associated costs. By leveraging Snowflake’s stream processing and trigger-based task scheduling , we ensure data is loaded and validated as soon as it arrives, allowing for near real-time processing.
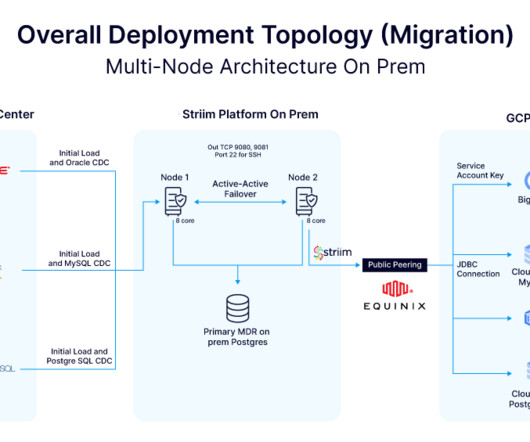
Organizations across various industries require real-time access to data to drive decisions, enhance customer experiences, and streamline operations. A leading home improvement retailer recognized the need to modernize its data infrastructure in order to move data from legacy systems to the cloud and improve operational efficiency. To achieve these goals, the retailer partnered with Striim to support its data modernization and real-time integration efforts.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Cryptographic monitoring at scale has been instrumental in helping our engineers understand how cryptography is used at Meta. Monitoring has given us a distinct advantage in our efforts to proactively detect and remove weak cryptographic algorithms and has assisted with our general change safety and reliability efforts. We’re sharing insights into our own cryptographic monitoring system, including challenges faced in its implementation, with the hope of assisting others in the industry aiming to
Leverage dbt and its advanced scripting functionality to generate dynamic pivot tables that adapt to changing pivot values Continue reading on Towards Data Science »
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Slow Presto® queries can hinder data-driven operations. At Uber, we designed Presto express to achieve a 50% improvement in the end-to-end SLA for 70% of queries using query analysis, real-time insights, and resource isolation.
Today, cyber defenders face an unprecedented set of challenges as they work to secure and protect their organizations. In fact, according to the Identity Theft Resource Center (ITRC) Annual Data Breach Report , there were 2,365 cyber attacks in 2023 with more than 300 million victims, and a 72% increase in data breaches since 2021. The constant barrage of increasingly sophisticated cyberattacks has left many professionals feeling overwhelmed and burned out.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























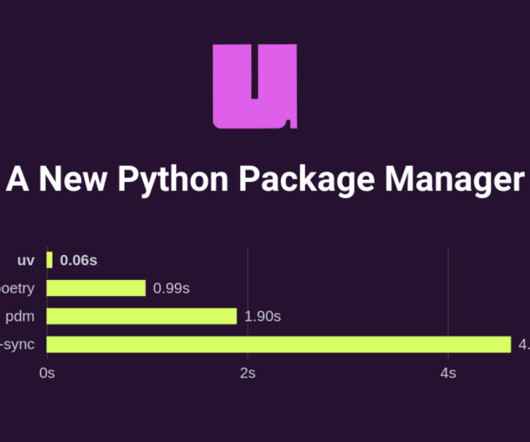


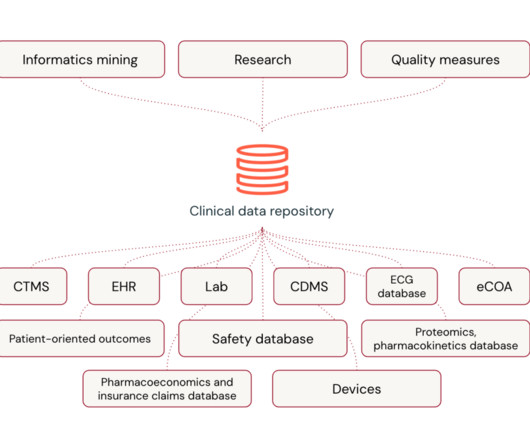









Let's personalize your content