This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data science is ever-evolving, so mastering its foundational technical and soft skills will help you be successful in a career as a Data Scientist, as well as pursue advance concepts, such as deep learning and artificial intelligence.
AWS has jumped on the bandwagon of removing the need for ETLs. Snowflake announced this both with their hybrid tables and their partnership with Salesforce. Now, I do take a little issue with the naming “Zero ETLs”. Because at the very surface the functionality described is often closer to a zero integration future, which probably… Read more The post Should We Get Rid Of ETLs?
Data engineering is a vital field within the realm of data science that focuses on the practical aspects of collecting, storing, and processing large amounts of data. It involves designing and building the infrastructure to store and process data, as well as developing the tools and systems to extract valuable insights and knowledge from that […] The post I asked ChatGPT to write a blog post about Data Engineering.
Summary Making effective use of data requires proper context around the information that is being used. As the size and complexity of your organization increases the difficulty of ensuring that everyone has the necessary knowledge about how to get their work done scales exponentially. Wikis and intranets are a common way to attempt to solve this problem, but they are frequently ineffective.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
It's time again to look at some data science cheatsheets. Here you can find a short selection of such resources which can cater to different existing levels of knowledge and breadth of topics of interest.
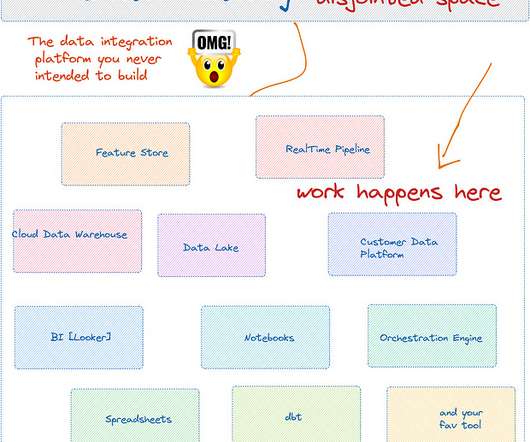
Data catalogs are the most expensive data integration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern data workflow, not just adding “modern” in its prefix. I know that is an expensive statement to make😊 To be fair, I’m a big fan of data catalogs, or metadata management , to be precise.
We’ve all been in that spot, especially in tech. You wanted to fit in, be cool, and look smart, so you didn’t ask any questions. And now it’s too late. You’re stuck. Now you simply can’t ask … you’re too afraid. I get it. Apache Arrow is probably one of those things. It keeps popping […] The post What is Apache Arrow?
We’ve all been in that spot, especially in tech. You wanted to fit in, be cool, and look smart, so you didn’t ask any questions. And now it’s too late. You’re stuck. Now you simply can’t ask … you’re too afraid. I get it. Apache Arrow is probably one of those things. It keeps popping […] The post What is Apache Arrow?
Summary With all of the messaging about treating data as a product it is becoming difficult to know what that even means. Vishal Singh is the head of products at Starburst which means that he has to spend all of his time thinking and talking about the details of product thinking and its application to data. In this episode he shares his thoughts on the strategic and tactical elements of moving your work as a data professional from being task-oriented to being product-oriented and the long term i
Looking to the Future – How a Data Operating System Breathes Life Into Healthcare Download (PDF) The post Looking to the Future – How a Data Operating System Breathes Life Into Healthcare appeared first on TheModernDataCompany.
The Top Data Strategy Influencers and Content Creators on LinkedIn Eitan Chazbani 2022-12-29 14:08:41 What’s the latest in the data world? In a space that moves at a rapid-fire pace, keeping up with new trends and evolving best practices can be dizzying. But having the right network can make all the difference. Regularly following updates from leaders in the data strategy space can go a long way toward not only helping you stay up to date on the latest and greatest, but also allowing you to join
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Summary Encryption and security are critical elements in data analytics and machine learning applications. We have well developed protocols and practices around data that is at rest and in motion, but security around data in use is still severely lacking. Recognizing this shortcoming and the capabilities that could be unlocked by a robust solution Rishabh Poddar helped to create Opaque Systems as an outgrowth of his PhD studies.
Banking and Capital Markets are undergoing a period of transformation. The global economic outlook is somewhat fragile, but banks are in an excellent position to survive and thrive as long as they have the right tools in place. According to Deloitte’s report 2023 Banking and Capital Markets Outlook , banks must find ways to adapt to global disruption and understand the changing needs of consumers to find success.
No one wants to read marketing fluff, especially not data engineers. These builders and architects are prone to scoff at any article detailing concepts at a “high-level.” Everyone understands that data lineage and data pipeline monitoring are important, but the real question is, “how do you build it?” Caveat emptor, the following articles are for the technically inclined and definitely not for the faint of heart.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Summary Five years of hosting the Data Engineering Podcast has provided Tobias Macey with a wealth of insight into the work of building and operating data systems at a variety of scales and for myriad purposes. In order to condense that acquired knowledge into a format that is useful to everyone Scott Hirleman turns the tables in this episode and asks Tobias about the tactical and strategic aspects of his experiences applying those lessons to the work of building a data platform from scratch.
It's the end of the year, and so it's time for KDnuggets to assemble a team of experts and get to the bottom of what the most important data science, machine learning, AI and analytics developments of 2022 were.
The Terms and Conditions of a Data Contract are Automated Production Data Tests. A data contract is a formal agreement between two parties that defines the structure and format of data that will be exchanged between them. Data contracts are a new idea for data and analytic team development to ensure that data is transmitted accurately and consistently between different systems or teams.
Data mesh is a complex socio-technological data engineering concept, but it doesn’t change too much. The four principles are still the four principles, there are still three experience planes, and automation is still as vital as ever. This is a good thing! Data mesh is one of those rare transformative concepts that emerged relatively fully formed as a result of creator Zhamak Dhegani’s years of consulting experience captured in a comprehensive 384 page book.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Reading Time: 8 minutes As of this writing, Linux has a global desktop market share of 2.77% ( A Report by Statcounter ), but it powers over 90% of all cloud infrastructure and hosting services. It is critical to be familiar with common Linux commands for this reason alone. According to a 2022 StackOverflow survey , Linux-based operating systems are more popular than macOS, demonstrating the appeal of using open-source software by professional developers, with an impressive 39.89% market share.
Data center downtime can be costly. Gartner estimates that downtime can cost $5,600 per minute, extrapolating to well over $300K per hour. When your organization’s digital service is interrupted, it can impact employee productivity, company reputation, and customer loyalty. It can also result in the loss of business, data, and revenue. With the heart of the holiday season happening, we have tips on how to enjoy holiday downtime while avoiding the high costs of data center downtime.
From a build perspective, data products ultimately translate into products that utilize data to improve services and overall functionality. And if we were to go by this definition, it becomes clear that no product in the world can truly survive unless they are a “data product”.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Scaling Elasticsearch Elasticsearch is a NoSQL search and analytics engine that is easy to get started using for log analytics, text search, real-time analytics and more. That said, under the hood Elasticsearch is a complex, distributed system with many levers to pull to achieve optimal performance. In this blog, we walk through solutions to common Elasticsearch performance challenges at scale including slow indexing, search speed, shard and index sizing, and multi-tenancy.
Python is one of the programming languages that are very versatile and relatively easy to learn. Hence it is the choice of many new programmers, regardless of what area of tech they are interested in. It is particularly popular in all data science branches.
The Pareto Principle , which holds 80% of the results will derive from 20% of the cases, is tough to escape. It definitely holds true for our Data Downtime blog with these five articles driving a majority of our traffic in 2022. There are a few characteristics that separate these articles from the chaff, namely: They were among the first to describe or even define a nascent concept.
Read Time: 3 Minute, 2 Second SSE File Encryption: During this post we will discuss an ERROR while executing the COPY command. Recently we got an issue while loading data from S3 bucket to Snowflake. According to the scenario, there were two files present in the bucket but surprisingly COPY command was failing to process one File. The command was reporting Access denied error for particular file.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
As 2022 wraps up, we would like to recap our top posts of the year in Data Integrity, Data Integration, Data Quality, Data Governance, Location Intelligence, SAP Automation, and how data affects specific industries. Let’s take a look! Best of Data Integrity Data integrity empowers your businesses to make fast, confident decisions based on trusted data that has maximum accuracy, consistency, and context.
I don’t see myself as a writer or blogger. In fact, the first blog post I published on Medium sat as a draft for months. ( Data downtime , anyone?) Prior to launching Monte Carlo, I interviewed hundreds of data leaders. I gained so much insight into their hopes, dreams, and fears that the impulse to share finally exceeded the anxiety of publishing. And there was no turning back.
The holidays bring joy and memories. It is always a joyful memory for me every week when I pen down (or key down 🤷🏽♂️) every edition of Data Engineering Weekly. I want to take a holiday break for this week's edition, and instead, I want to reflect on our journey in 2022. A Growth To Remember 2022 has been a remarkable year in terms of subscriber growth.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content