3 Key techniques, to optimize your Apache Spark code
Start Data Engineering
JUNE 19, 2020
Intro A lot of tutorials show how to write spark code with just the API and code samples, but they do not explain how to write “efficient Apache Spark” code.

Start Data Engineering
JUNE 19, 2020
Intro A lot of tutorials show how to write spark code with just the API and code samples, but they do not explain how to write “efficient Apache Spark” code.

Simon Späti
JUNE 14, 2020
Today we have more requirements with ever-growing tools and framework, complex cloud architectures, and with data stack that is changing rapidly. I hear claims: “Business Intelligence (BI) takes too long to integrate new data”, or “understanding how the numbers match up is very hard and needs lots of analysis”. The goal of this article is to make business intelligence easier, faster and more accessible with techniques from the sphere of data engineering.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Confluent
JUNE 19, 2020
When I have a small software project that I want to share with the world, I don’t write my own version control system with a web UI. I don’t even […].

Teradata
JUNE 17, 2020
Juneteenth has been declared a U.S. holiday at Teradata, as we stand with the black community and reflect on what we can do to fight racism and injustice, and embrace diversity.

Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.

Data Engineering Podcast
JUNE 15, 2020
Summary Machine learning is a process driven by iteration and experimentation which requires fast and easy access to relevant features of the data being processed. In order to reduce friction in the process of developing and delivering models there has been a recent trend toward building a dedicated feature. In this episode Simba Khadder discusses his work at StreamSQL building a feature store to make creation, discovery, and monitoring of features fast and easy to manage.

Advancing Analytics: Data Engineering
JUNE 16, 2020
You might have seen that I’ve been pretty busy recently, digging into the new Azure Synapse Analytics preview, announced back at Microsoft Build 2020. I’ve explored the spark engine, SQL serverless/On-Demand and various other bits… but I’m still getting the same question of “Cool!…. but what actually is it?”. One of the problems here is that Azure SQL Data Warehouse was rebranded as “Azure Synapse Analytics”… but it’s not the same as the full workspace.
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

Teradata
JUNE 16, 2020
Integration with AWS first-party services gives our enterprise customers as much cloud-native functionality as they want for their Vantage environments. Learn more.

Rock the JVM
JUNE 16, 2020
Explore how Akka Streams, Kafka Streams, and Spark Streaming stack up and find out which one is best for your use case
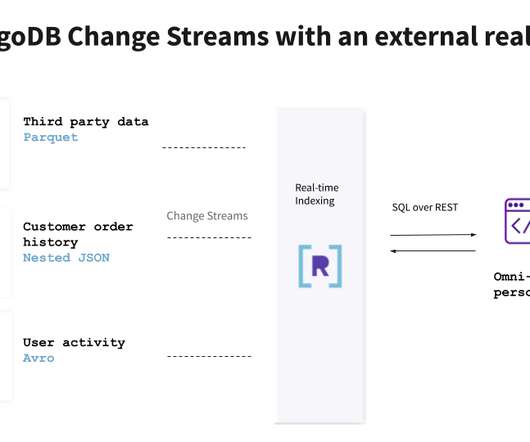
Rockset
JUNE 16, 2020
MongoDB.live took place last week, and Rockset had the opportunity to participate alongside members of the MongoDB community and share about our work to make MongoDB data accessible via real-time external indexing. In our session, we discussed the need for modern data-driven applications to perform real-time aggregations and joins, and how Rockset uses MongoDB change streams and Converged Indexing to deliver fast queries on data from MongoDB.

Confluent
JUNE 18, 2020
Many organisations rely on commercial or open source monitoring tools to measure the performance and stability of business-critical applications. AppDynamics, Datadog, and Prometheus are widely used commercial and open source […].

Speaker: Kenten Danas, Senior Manager, Developer Relations
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!

Teradata
JUNE 18, 2020
Integration with Azure first-party services enables Vantage users to tap into new sources of innovation across all aspects of the analytic process from start to finish.

dbt Developer Hub
JUNE 19, 2020
If you’ve been using dbt for over a year, your project is out-of-date. This is natural. New functionalities have been released. Warehouses change. Best practices are updated. Over the last year, I and others on the Fishtown Analytics (now dbt Labs!) team have conducted seven audits for clients who have been using dbt for a minimum of 2 months. In every single audit, we found opportunities to: Improve performance Improve maintainability Make it easier for new people to get up-to-speed on the proj

Teradata
JUNE 17, 2020
Lloyds Banking Group executes analytic projects that benefit the customer journey for multiple brands within Lloyds Banking Group.

Teradata
JUNE 14, 2020
Learn how leveraging Machine Learning for advanced analytics enables Telcos to tackle problems from identifying network anomalies to customer churn. Read more.

Advertisement
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.

Expert insights. Personalized for you.






Let's personalize your content