Introducing Objectiv: Open-source product analytics infrastructure
KDnuggets
JUNE 21, 2022
Collect validated user behavior data that’s ready to model on without prepwork. Take models built on one dataset and deploy & run them on another.

KDnuggets
JUNE 21, 2022
Collect validated user behavior data that’s ready to model on without prepwork. Take models built on one dataset and deploy & run them on another.

Simon Späti
JUNE 20, 2022
Data consumers, such as data analysts, and business users, care mostly about the production of data assets. On the other hand, data engineers have historically focused on modeling the dependencies between tasks (instead of data assets) with an orchestrator tool. How can we reconcile both worlds? This article reviews open-source data orchestration tools (Airflow, Prefect, Dagster) and discusses how data orchestration tools introduce data assets as first-class objects.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Start Data Engineering
JUNE 24, 2022
1. Introduction 2. Steps 2.1. Choosing companies to work for 2.2. Optimizing your Linkedin & resume 2.3. Landing interviews 2.4. Preparing for interviews 2.5. Offers & Negotiation 3. Conclusion 4. Further reading 5. Reference 1. Introduction The data industry is booming! & data engineering salaries are skyrocketing. But landing a new job is not an easy task.

Azure Data Engineering
JUNE 19, 2022
While we have discussed various ways for running custom SQL code in Azure Data Factory in a previous post , recently, a new activity has been added to Azure Data Factory called Script Activity , which provides a more flexible way of running custom SQL scripts. Azure Data Factory: Script Activity As shown in the screenshot above, this activity supports execution of custom Data Query Language (DQL) as well as Data Definition Language (DDL) and Data Manipulation Language (DML).

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.

KDnuggets
JUNE 23, 2022
Essential Linux commands to improve the data science workflow. It will give you the power to automate tasks, build pipelines, access file systems, and enhance development operations.

Marc Lamberti
JUNE 19, 2022
Dynamic Task Mapping is a new feature of Apache Airflow 2.3 that puts your DAGs to a new level. Now, you can create tasks dynamically without knowing in advance how many tasks you need. This feature is for you if you want to process various files, evaluate multiple machine learning models, or process a varied number of data based on a SQL request. Excited?
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

|

Cloudera
JUNE 18, 2022
Cloudera customers run some of the biggest data lakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.

KDnuggets
JUNE 22, 2022
Let’s get into some of the expectations of data scientists – and the reality they face.

Confluent
JUNE 23, 2022
Set up a hybrid cloud environment with Confluent for Kubernetes to enable seamless cloud and on-preem integrations, a cloud-native, declarative API, and cluster linking.

Data Engineering Podcast
JUNE 19, 2022
Summary Data analysis is a valuable exercise that is often out of reach of non-technical users as a result of the complexity of data systems. In order to lower the barrier to entry Ryan Buick created the Canvas application with a spreadsheet oriented workflow that is understandable to a wide audience. In this episode Ryan explains how he and his team have designed their platform to bring everyone onto a level playing field and the benefits that it provides to the organization.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.

Cloudera
JUNE 22, 2022
Across the globe, cloud concentration risk is coming under greater scrutiny. The UK HM Treasury department recently issued a policy paper “ Critical Third Parties to the Finance Sector.” The paper is a proposal to enable oversight of third parties providing critical services to the UK financial system. The proposal would grant authority to classify a third party as “critical” to the financial stability and welfare of the UK financial system, and then provide governance in order to minimize the p

KDnuggets
JUNE 21, 2022
In this article, we examine various types of plots used in data science and machine learning.
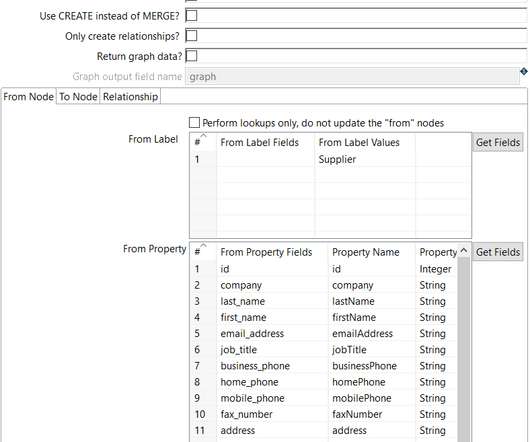
know.bi
JUNE 22, 2022
This guide will teach you the process of exporting data from a relational database (MySQL) and importing it into a graph database (Neo4j). You will learn how to take data from the relational system and to the graph by translating the schema and using Apache Hop as import tools. This Tutorial uses a specific data set, but the principles in this tutorial can be applied and reused with any data domain.

Pipeline Data Engineering
JUNE 22, 2022
It’s time to share some important news with you: we’re taking time off to focus on our health and families, the launch of new data engineering cohorts is on hold until further notice. Health and family Running a bootstrapped company in times of repeated economic crises and data industry vibe shifts is a gift and a curse at the same time. No surprises here: it can be highly rewarding and joyful, but it can be exhausting and stressful as well.

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri

Zalando Engineering
JUNE 22, 2022
What were the biggest learnings in your career so far? And what advice would you give your younger self today? How do you get ahead in your career? We’re celebrating International Women in Engineering Day by talking to three senior Zalando Women in Tech: Mahak Swami , Engineering Manager; Floriane Gramlich , Director of Product Payments; and Ana Peleteiro Ramallo , Head of Applied Science.

KDnuggets
JUNE 20, 2022
Check out Super Study Guide: Algorithms and Data Structures, a free ebook covering foundations, data structures, graphs, and trees, sorting and searching.

Confluent
JUNE 22, 2022
How to use data pipelines, unlock the benefits of real-time data flow, and achieve seamless data streaming and analytics at scale with Confluent.

U-Next
JUNE 22, 2022
Scrum is a framework for developing complicated products under the Agile product development umbrella. The term scrum is also used during a sprint to describe the daily standup sessions. A sprint is one iteration of a continuous development cycle that is timed. During a Sprint, the team must complete a set amount of work and prepare it for review. Sprints are the smallest and most reliable time intervals used by scrum teams.

Advertisement
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you

Rockset
JUNE 21, 2022
We’re excited to announce that Rockset’s new connector with Snowflake is now available and can increase cost efficiencies for customers building real-time analytics applications. The two systems complement each other well, with Snowflake designed to process large volumes of historical data and Rockset built to provide millisecond-latency queries , even when tens of thousands of users are querying the data concurrently.

KDnuggets
JUNE 24, 2022
Will your skills get outdated if you survive on one programming language for your career? Read on to find out.

Yelp Engineering
JUNE 21, 2022
Our community of users will always come first, which is why Yelp takes significant measures to protect sensitive user information. In this spirit, the Database Reliability Engineering team implemented a data sanitization process long ago to prevent any sensitive information from leaving the production environment. The data sanitization process still enables developers to test new features and asynchronous jobs against a complete, real time dataset without complicated data imports.

Teradata
JUNE 21, 2022
Companies have started to explore deployment of 5G networks across their value chains. This post will look at the impact of 5G on manufacturing value chain activities.

Speaker: Tamara Fingerlin, Developer Advocate
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!

U-Next
JUNE 21, 2022
The distinction between hashing and encryption is that hashing refers to converting permanent data into message digests, but encryption operates in two ways: decoding and encoding the data. Hashing serves to maintain the information’s integrity, while md5 encryption and decryption are used to keep data out of the hands of third parties. Encryption and Hashing difference appears to be indistinguishable, yet they are not.

KDnuggets
JUNE 23, 2022
Drop in for some tips on how this fundamental statistics concept can improve your data science.

Rock the JVM
JUNE 20, 2022
Discover Slick: The popular Scala library for seamless database interactions

Emeritus
JUNE 20, 2022
Data is the new oil. In a crude, unrefined form, it is of no real use. But once it is cleaned and processed, its value shoots up. From understanding customer behavior to sales performance, everything makes more sense when data is analyzed the right way. The ability to take existing data, and process it with… The post 10 Best Online Data Science Courses Hand-Picked for You appeared first on Emeritus Online Courses.

Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m

U-Next
JUNE 21, 2022
Introduction. People naturally spend a substantial portion of their day online now that digital media has become an essential part of their lives. As a result, digital platforms have become a very familiar location for individuals worldwide, and people have begun to trust the information provided on digital platforms. The term refers to any electronic information on our computers or cell phones.

KDnuggets
JUNE 20, 2022
Tech visionaries to address accelerating machine learning, unifying AI platforms and taking intelligence to the edge, at the fifth annual AI Hardware Summit & Edge AI Summit, Santa Clara.

Monte Carlo
JUNE 23, 2022
When it comes to big data quality, bigger data isn’t always better data. But at times we are guilty of forgetting this. At some point in the last two decades, the size of our data became inextricably linked to our ego. The bigger the better. We watched enviously as FAANG companies talked about optimizing hundreds of petabyes in their data lakes or data warehouses.

Rock the JVM
JUNE 20, 2022
This article is brought to you by Yadu Krishnan , a new contributor to Rock the JVM. He’s a senior developer and constantly shares his passion for new languages, libraries and technologies. He also loves writing Scala articles, especially for newcomers. This is a beginner-friendly article to get started with Slick, a popular database library in Scala.

Advertisement
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.

Expert insights. Personalized for you.






Let's personalize your content