This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In a data-driven world, behind-the-scenes heroes like data engineers play a crucial role in ensuring smooth data flow. Imagine being an online shopper who suddenly receives irrelevant recommendations. A data engineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless data pipelines.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one out of four topics from today’s subscriber-only The Scoop issue. To get full issues twice a week, subscribe here.
Summary Data transformation is a key activity for all of the organizational roles that interact with data. Because of its importance and outsized impact on what is possible for downstream data consumers it is critical that everyone is able to collaborate seamlessly. SQLMesh was designed as a unifying tool that is simple to work with but powerful enough for large-scale transformations and complex projects.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Introduction In the era of data-driven decision-making, having accurate data modeling tools is essential for businesses aiming to stay competitive. As a new developer, a robust data modeling foundation is crucial for effectively working with databases. Properly configured data structures ensure a smoother workflow and prevent data loss or misplacement.
Introduction We are thrilled to unveil the English SDK for Apache Spark, a transformative tool designed to enrich your Spark experience. Apache Spark™.
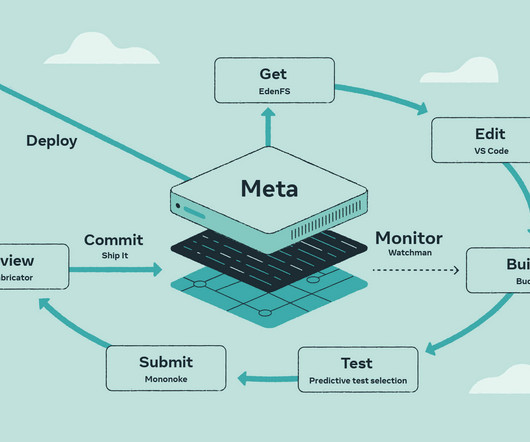
Every day, thousands of developers at Meta are working in repositories with millions of files. Those developers need tools that help them at every stage of the workflow while working at extreme scale. In this article we’ll go through a few of the tools in the development process. And, as an added bonus, those we talk about below are open source so you can try them yourself.
Every day, thousands of developers at Meta are working in repositories with millions of files. Those developers need tools that help them at every stage of the workflow while working at extreme scale. In this article we’ll go through a few of the tools in the development process. And, as an added bonus, those we talk about below are open source so you can try them yourself.
The k-Nearest Neighbors Classifier is a machine learning algorithm that assigns a new data point to the most common class among its k closest neighbors. In this tutorial, you will learn the basic steps of building and applying this classifier in Python.
Introduction We had an amazing opportunity to learn from Mr. Pavan. He is an experienced data engineer with a passion for problem-solving and a drive for continuous growth. Throughout the conversation, Mr. Pavan shares his journey, inspirations, challenges, and accomplishments. Thus, providing valuable insights into the field of data engineering. As we explore Mr.
1. Introduction 2. What is self-serve? 2.1. Components of a self-serve platform 3. Building a self-serve data platform 3.1. Creating dataset(s) 3.1.1. Gather requirements 3.1.2. Get data foundations right 3.2. Accessing data 3.3. Identify and remove dependencies 4. Conclusion 5. Further reading 6. References 1. Introduction Most companies want to build a self-serve data platform.
Surprised? You shouldn't. I've always been eager to learn, including 5 years ago when for the first time, I left my Apache Spark comfort zone to explore Apache Beam. Since then I had a chance to write some Dataflow streaming pipelines to fully appreciate this technology and work on AWS, GCP, and Azure. But there is some excitement for learning-from scratch I miss.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
I’ve been a dog licking my wounds for some time now. Over on my Substack newsletter, I’ve been doing a small series on DSA (Data Structures and Algorithms). I tackled some of the easier stuff first, like Linked Lists, Binary Search, and the like. What’s more, I actually did most of it in Rust, since […] The post Exploring Graphs in Rust.
( credits ) Hey, this is the Data News. It's super hard to change habits, but it's how it is, the newsletter is going out on Saturday. I hope this edition finds you well. Summer is coming ☀️ Thank you all because we crossed the 3000 subscribers mark last week. Let's go for the 4000 before the end of the year 🤗 This is a almost-raw edition for this week.
Generative AI will have a transformative impact on every business. Databricks has been pioneering AI innovations for a decade, actively collaborating with thousands.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Written by Konstantin Gizdarski and Martin Liu at Lyft. In early 2022, Lyft already had a comprehensive Machine Learning Platform called LyftLearn composed of model serving , training , CI/CD, feature serving , and model monitoring systems. On the real-time front, LyftLearn supported real-time inference and input feature validation. However, streaming data was not supported as a first-class citizen across many of the platform’s systems — such as training, complex monitoring, and others.
For the last several years, internal infrastructure at LinkedIn has been built around a self-service model, enabling developers to onboard themselves with minimal support. We have various user experiences that let application teams provision their own resources and infrastructure, generally by filling out forms or using command-line tools. For example, developers can provision Kafka topics, Espresso tables, Venice stores and more via Nuage , our internal cloud-like infra management platform.
This article provides a general overview of Stable Diffusion and focuses on building a basic understanding of how generative artificial intelligence works.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Get an introduction into the world of events and event-driven architecture in Apache Kafka. Learn what events are and the role they play in event design, event streaming, and event-driven design.
Active listening is an admired and sought after skill in both the professional and personal sphere. After all, who doesn’t love to be heard? But what happens when we apply that mindset to the way our organizations solicit feedback and interact with our customers? We don’t have to make any assumptions to answer this question, because we have the data.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
At Snowflake Summit , we announced the public launch of the Snowflake Performance Index (“SPI”), an aggregate index for measuring real-world improvements in Snowflake performance experienced by customers over time. At Snowflake, our product philosophy revolves around continuously enhancing the performance of our product, particularly the core database engine.
At ThoughtSpot, we know how important it is for businesses of every size and industry to empower every knowledge worker with personalized, actionable data-driven insights. These insights are your secret sauce to making better business decisions, growing faster, and delivering customer experiences that keep people coming back for more. But how do you scale self-service analytics to business users without completely overwhelming your data teams?
Large language models are getting released left right and center, and if you want to understand them better you need to know about NLP. Here are 5 Free books to help you.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Since launching this year’s contest in October, receiving hundreds of submissions, and completing three rounds of judging, the wait is over: Maxa is the 2023 Snowflake Startup Challenge grand prize winner! Maxa’s goal is to automate financial and operations ERP insights extremely fast and without requiring special skills. To make that happen, it leverages the breadth of the Snowflake platform to transform raw data from multiple financial and operational systems into a common data model that user
Pride is more than just a month-long celebration; it is a powerful movement that reminds us of the importance of equality, acceptance, and love. It is that special time of year for the global queer community to come together to celebrate, commemorate, and continue to push for progress. It’s no different here at ThoughtSpot. We believe in creating an inclusive environment where everyone feels seen, heard, and valued.
This list of the most commonly used machine learning algorithms in Python and R is intended to help novice engineers and enthusiasts get familiar with the most commonly used algorithms.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content