This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Problem. Uber deploys a few storage technologies to store business data based on their application model. One such technology is called Schemaless , which enables the modeling of related entries in one single row of multiple columns, as well as … The post Jellyfish: Cost-Effective Data Tiering for Uber’s Largest Storage System appeared first on Uber Engineering Blog.
Summary Gartner analysts are tasked with identifying promising companies each year that are making an impact in their respective categories. For businesses that are working in the data management and analytics space they recognized the efforts of Timbr.ai, Soda Data, Nexla, and Tada. In this episode the founders and leaders of each of these organizations share their perspective on the current state of the market, and the challenges facing businesses and data professionals today.
The CDP Operational Database ( COD ) builds on the foundation of existing operational database capabilities that were available with Apache HBase and/or Apache Phoenix in legacy CDH and HDP deployments. Within the context of a broader data and analytics platform implemented in the Cloudera Data Platform ( CDP ), COD will function as highly scalable relational and non-relational transactional database allowing users to leverage big data in operational applications as well as the backbone of the a
I’ve always found event sourcing to be fascinating. We spend so much of our lives as developers saving data in database tables—doing this in a completely different way seems almost […].
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Martin Tingley with Wenjing Zheng , Simon Ejdemyr , Stephanie Lane , and Colin McFarland This introduction is the first in a multi-part series on how Netflix uses A/B tests to make decisions that continuously improve our products, so we can deliver more joy and satisfaction to our members. Subsequent posts will cover the basic statistical concepts underpinning A/B tests, the role of experimentation across Netflix, how Netflix has invested in infrastructure to support and scale experimentation, a
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure). This introduces new challenges around managing data access across teams and individual users.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure). This introduces new challenges around managing data access across teams and individual users.
The pace of data being created is mind-blowing. For example, Amazon receives more than 66,000 orders per hour with each order containing valuable pieces of information for analytics. Yet, dealing with continuously growing volumes of data isn’t the only challenge businesses encounter on the way to better, faster decision-making. Information often resides across countless distributed data sources, resulting in data silos.
At the 1992 Olympics, the American men’s basketball team won the gold medal after years of disappointment and underperformance. For the first time at an Olympics, Team USA was comprised of professional US National Basketball Association (NBA) players, including the legendary Michael Jordan. Since this ‘Dream Team’ was formed, the USA men’s basketball team has won seven golds at the last eight Olympics, including most recently at Tokyo 2020.
Apache Hive and Apache Spark are the two popular Big Data tools available for complex data processing. To effectively utilize the Big Data tools, it is essential to understand the features and capabilities of the tools. Spark vs. Hive comparison elaborates on the two tools’ architecture, features, limitations, and key differences. Table of Contents Spark vs Hive - Architecture Hive vs Spark - Key Features and Capabilities Apache Hive - Key Features Apache Spark - Key Features Apache Spark
In recent years there has been increased interest in how to safely and efficiently extend enterprise data platforms and workloads into the cloud. CDOs are under increasing pressure to reduce costs by moving data and workloads to the cloud, similar to what has happened with business applications during the last decade. Our upcoming webinar is centered on how an integrated data platform supports the data strategy and goals of becoming a data-driven company.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Change is inevitable, but you have to adapt to survive. Take a look back on the last 40 years to see how Teradata has adapted to change.and not only survived, but thrived.
Adopting DataOps can be easy; by following DataKitchen's 'Lean DataOps' four-phase program, you can roll out DataOps in smaller, easy-to-manage increments. The post Jumpstart Your DataOps Program with DataKitchen’s Lean DataOps first appeared on DataKitchen.
At Rockset, we work hard to build developer tools (as well as APIs and SDKs) that allow you to easily consume semi-structured data using SQL and run sub-second queries on real-time data. You automatically get our Converged Index ™, which unifies indexing, sub-second query latency on terabytes of nested data, real-time data ingestion for mere seconds in data latency, and much more.
Meet Fanly Tanto. Fanly is a Regional Sales Director operating out of Indonesia and the recent recipient of Channel Asia’s Women in ICT “Shining Star” Award – an award recognizing candidates with “a strong record of achievement and a consistent high performer who regularly achieves standout business results and continues to assume increased levels of seniority.” .
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Apache Superset™ now supports Rockset as a data source. Rockset is a real-time indexing database built for the cloud that uses RocksDB for fast storage.
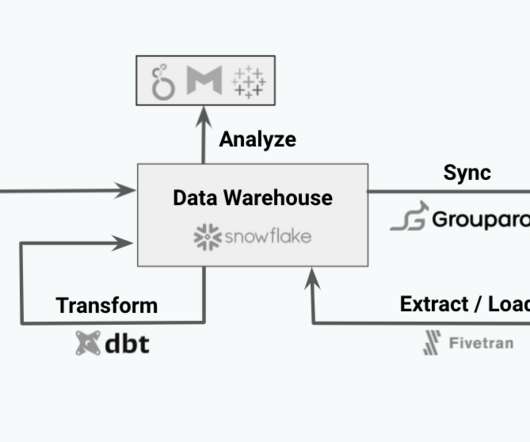
Modern data teams have all the right solutions in place to ensure that data is ingested, stored, transformed, and loaded into their data warehouse, but what happens at “the last mile?” In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use? Here’s where Reverse ETL and Data Observability can help teams go the extra mile when it comes to trusting your data products.
Zalando's Fashion Store has been running on top of microservices for quite some time already. This architecture has proven to be very flexible, and project Mosaic has extended it – although partially – to the frontend, allowing HTML fragments from multiple services to be stitched together, and served as a single page. Fragments in Mosaic can be seen as the first step towards a Micro Frontends architecture.
Across the federal government, agencies are struggling to identify, organize, analyze, and act on troves of data. It’s a problem that leaders are working actively to tackle, but they’re in a race against immeasurable volumes of data that is continuously being generated in perpetuity in stores known and unknown. At the Internal Revenue Service, decades’ worth of data exceeds even the most cutting-edge processing capabilities.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Event stream processing has lately become the most-requested feature among data practitioners, who are ever being pushed by their business counterparts for more fresh, real-time insights to improve their operational decisions and boost the digital customer experience. But while streaming data is easy, analyzing it in real time was, until recently, too expensive and too slow.
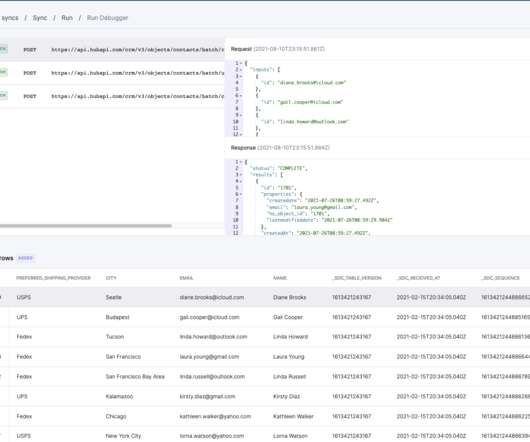
We've improved the Getting Started Experience! Check out our UI Configuration method. The steps utilizing grouparoo generate will not be replicable as the command will be fully deprecated in v0.8.1 What is Operational Analytics? Operational analytics is the process of creating data pipelines and datasets to support business teams such as sales, marketing, and customer support.
From Warehouse to Lakehouse Pt.1 SCD Type 1 in SQL and Python Introduction With the move to cloud based Data Lake platforms there has often been criticism from the more traditional Data Warehousing community. A Data Lake, offering cheap, almost endlessly scalable storage in the cloud is hugely appealing to a platform administrator however over the number of years that this has been promoted some adopters have often fallen victim to the infamous Data Swamp.
Corporate responsibility may have a new name but Teradata’s commitments continue to shine. Read Claire Bramley and Molly Treese’s overview of Teradata’s dedicated ESG efforts.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
August is usually a quiet month, with vacations taking their toll. But data engineering never stops. I’m Pasha Finkelshteyn and I will be your guide through this month’s news, my impressions of the developments, and ideas from the wider community. If you think I missed something worthwhile, ping me on Twitter and suggest a topic, link, or anything else.
In this article, you will find a list of interesting web scraping projects that are fun and easy to implement. The list has worthwhile web scraping projects for both beginners and intermediate professionals. The projects have been divided into categories so that you can quickly pick one as per your requirements. Table of Contents Top 20 Web Scraping Project Ideas Useful Web Scraping Projects for Beginners Fun Web Scraping Projects for Final Year Students Python Web Scraping Projects Machine Lear
The promise of open source is one of community. It is about people making great things together. With that in mind, maybe it's not surprising that we first met KC Glick years ago when he contributed to the Actionhero project that is at the core of Grouparoo. Now, he's on the Grouparoo team and will be contributing throughout the stack. KC comes to us most recently from iHeart, the media company that runs all those stations we listen to.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
The Machine Learning market is anticipated to be worth $30.6 Billion in 2024. The world is increasingly driven by the Internet of Things (IoT) and Artificially Intelligent (AI) solutions. Machine Learning plays a vital role in the design and development of such solutions. Machine learning is everywhere. We live in an era led by machine learning applications , be it the Voice Assistants on our Smartphones, the Face Unlock feature, the surge pricing on the ride-hailing apps, email filtering, and m
August is usually a quiet month, with vacations taking their toll. But data engineering never stops. I’m Pasha Finkelshteyn and I will be your guide through this month’s news, my impressions of the developments, and ideas from the wider community. If you think I missed something worthwhile, ping me on Twitter and suggest a topic, link, or anything else.
Are you confused about choosing the best cloud platform for your next data engineering project ? AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. So, are you ready to explore the differences between two cloud giants, AWS vs. google cloud? Let’s get started! Table of Contents AWS vs. GCP - The Cloud Battle AWS vs.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content